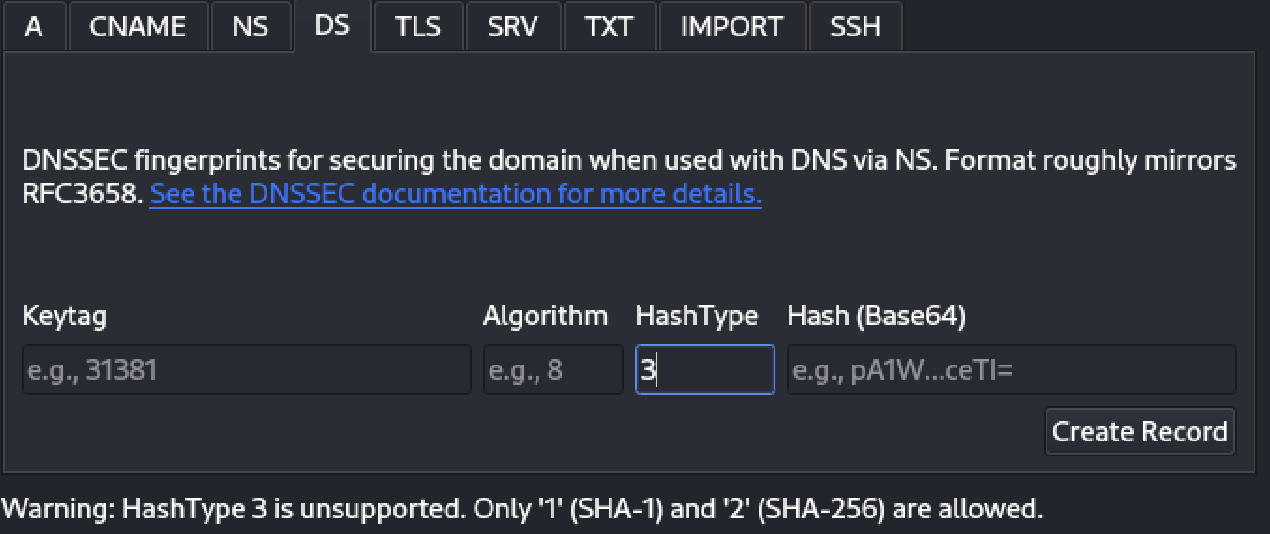
News
(RSS Feed)
Namecoin will be at FOSDEM 2026
We’re happy to announce that Namecoin will have a presence at FOSDEM 2026 in Brussels, January 31 - February 1. We expect to give a talk; check out the FOSDEM schedule to find us (or find our absence, if we are unlucky). Recordings and live-streams may happen as well.
If you’d like to meet up with us during FOSDEM, you can say hello in the #namecoin-dev Matrix channel, or possibly find us in the Decentralized Internet and Privacy Devroom.
We would like to give a huge thank-you to Power Up Privacy, NLnet Foundation, and RIAT for facilitating our presence. See you in Brussels!
Namecoin will be at 39C3
We’re happy to announce that Namecoin will have an Assembly at 39C3 (the 39th Chaos Communication Congress) in Hamburg, December 27-30. We will once again be hosted by the CDC (Critical Decentralization Cluster).
We expect to give some talks, however, the details are still in flux and will probably not be announced until shortly before the beginning of C3. Keep an eye on both the C3 and CDC websites to find us (or find our absence, if we are unlucky). We heard a rumor that recordings and live-streams may happen as well.
If you’d like to meet up with us at C3, the usual methods (c3nav, etc) should lead you to the CDC and the Namecoin Assembly. Some of us will also be reachable in the #namecoin-dev Matrix channel.
We would like to give a huge thank-you to Power Up Privacy, NLnet Foundation, Cyphrs, RIAT, and Sibermerdeka for facilitating our presence. See you in Hamburg!
Introducing Encasha: Off-Chain SSHFP Records
Since Encaya now supports off-chain TLSA records (used for TLS server authentication), this begs a question: can something similar be done for SSHFP records (used for SSH server authentication)?
In principle, the main things we would need to pull this off are:
- Some way to embed a blob of data inside an SSH public key.
- Some way for that blob to get passed to code we control (during the SSH handshake).
- Some way to mark a public key as trusted (also during the SSH handshake).
For requirement 1, guess what? SSH has certificates. SSH certificates are surprisingly rarely used, but they are a thing. SSH certificates can have extensions in them.
For requirement 2 and 3, the OpenSSH KnownHostsCommand config option does exactly this.
Thus, Encaya now has a younger sister: Encasha. Encasha has essentially the same threat model and scalability properties as off-chain TLSA records with Encaya. Most of the code that I had written for off-chain TLSA records has been split off into a library, which is now called by both Encaya and Encasha.
Huge kudos are due to the OpenSSH developers for making this much less painful than any of the TLS implementations I’ve ever worked with. If only HTTP over SSH were a thing….
Encasha should be released soon; the code is on GitHub if you’d like to play with it early.
This work was funded by NLnet Foundation’s NGI0 Core Fund.
Namecoin at GCER 2025
I represented Namecoin at the 2025 Global Conference on Educational Robotics (July 8-12, 2025 in Norman, OK). If you enjoy STEM education talks, this presentation might be up your alley.
Huge thanks to the staff and volunteers from KISS Institute for Practical Robotics, who organized GCER. And in particular a huge thanks to KIPR for publishing videos of the breakout presentations; this is hugely helpful to the community.
This work was funded by Power Up Privacy and NLnet Foundation’s NGI0 Core Fund.
Is Post-Quantum Namecoin TLS Feasible?
As the shelf life of most public-key cryptography nears its quantum-induced termination, many protocols are moving toward post-quantum (PQ) cryptography. PQ crypto, defined as cryptosystems that are believed to be secure against both classical and quantum cryptanalysis, is an active research area, with rapid advances happening in both the cryptosystems and the attacks. It would be nice if we had more time to research secure PQ cryptosystems, but alas we do not have that luxury. TLS is thus beginning to deploy PQ crypto. Which begs the question: how is Namecoin affected by PQ crypto adoption in TLS?
There are actually three different cryptosystems in Namecoin TLS that need a PQ replacement:
- Replacing ECDHE for the TLS handshake.
- Replacing ECDSA for the X.509 certificates.
- Replacing Schnorr for the on-chain transactions.
What would they be replaced with?
- ECDHE would be replaced with something like CRYSTALS-Kyber (standardized by NIST as ML-KEM).
- ECDSA would be replaced with something like CRYSTALS-Dilithium (standardized by NIST as ML-DSA).
- Schnorr would be replaced with CRYSTALS-Dilithium, or perhaps something like Falcon or Lamport signatures.
(Yes, cryptographers like sci-fi jokes when naming things.)
And who has to do the work to replace them?
- ECDHE is handled by web browsers. Encaya doesn’t touch this. Web browsers are already starting to deploy CRYSTALS-Kyber; no action is needed on Namecoin’s end.
- ECDSA in X.509 is handled specially by Encaya. It’s our job to make sure this doesn’t break when users try to use CRYSTALS-Dilithium!
- Schnorr on-chain is handled by Bitcoin. As the Bitcoin community moves toward PQ crypto adoption, Namecoin will have to follow Bitcoin on a softfork, but no additional action is needed on Namecoin’s end.
Yeah, uh, about number 2. What’s the challenge with CRYSTALS-Dilithium? The big problem is that Dilithium involves really really big public keys and really really big signatures (at least compared to ECDSA). Specifically, Dilithium5 public keys are 2592 bytes, with signatures of 4595 bytes. Dilithium is probably not catastrophic for TLS in general, but recall that Encaya needs to staple a public key (and maybe a signature too) into the AIA Issuer URL as well as the Issuer/Subject Serial Number. Mainstream TLS clients generally have no reason to expect massive amounts of data in these fields.
I already looked into the length limit of the AIA Issuer URL. The gist is that it’ll give a bit over 65 kB of data. That’s totally fine for Dilithium. However, other limits come into play. OpenSSL imposes a length limit of 100 KiB on the entire cert chain (the manual says 100 kB, but it’s wrong; the OpenSSL devs apparently are illiterate about the metric system). Given that the stapled data shows up 3 times in the TLS cert chain (AIA Issuer URL, Issuer Serial Number, and Subject Serial Number), that means we have a maximum of ~33.3 KiB to work with. (We have to fit the rest of the cert chain in too!) I couldn’t find any official documentation on the limits in Firefox (this article by Tomás Gutiérrez suggests Firefox is less tolerant than OpenSSL), but by manual testing, I found that stapled data of 32 kB worked OK, while 34 kB made Firefox so unhappy that it managed to show a TLS error with an empty error code (wat). So for practical purposes, our limits for Firefox look very close to those of OpenSSL. Microsoft Edge seems mildly more tolerant than Firefox, but I didn’t try to nail down how much more tolerant.
As far as I can tell, 32 kB of stapled data will easily meet our needs. It’s considerably larger than what we’d need for a Dilithium5 public key and a Dilithium5 signature, even if they were hex-encoded. In practice, we would probably use base64 encoding (more compact). TLS would probably use Dilithium2 or Dilithium3 (either of which would yield smaller public keys), and Bitcoin might wind up using Falcon, which has even smaller signatures than Dilithium2.
It’s not clear to me whether 32 kB of stapled data would be able to handle SPV proofs (as Handshake is doing), but on the other hand I am not convinced that stapling SPV proofs into a TLS handshake is something that Namecoin needs.

So, Namecoin’s Encaya certificate format is reasonably well prepared for a PQ transition. There will probably be plentiful drama elsewhere though. No ETA, as far as I’m aware, of when mainstream browsers will support Dilithium certificates.
This work was funded by Power Up Privacy.
Off-Chain TLSA Records in Encaya
Now that hashed TLSA records are a thing, it’s time to ask our inner mad scientist: can we do any better than that?
What would be better for scalability than only putting a hash on the blockchain? What about… not putting any TLS things on the blockchain? Sounds impossible, right?
Let’s frame this question a different way: why are we putting a TLSA record on the blockchain? Or perhaps we can ask an even more radical question: why do we put anything on the blockchain?
There are three main reasons we might put something on the blockchain:
- Authenticity: the data is signed by the rightful owner.
- Exclusivity: the data hasn’t been double-spent.
- Freshness: the data isn’t outdated.
Exclusivity isn’t really relevant for TLSA records; there’s not really any incentive for a domain owner to double-spend their own TLSA record.
What about authenticity? The signature is what’s important, but the signature doesn’t have to be the transaction signature. It’s straightforward to sign a message with a Bitcoin private key, and verify it against the corresponding Bitcoin address. This concept is frequently used in Bitcoinland for proof of reserves. And conveniently, in Namecoin, it’s very easy to check which Namecoin address owns a name.
So how would this look? We’re already stapling a public key into the Subject Serial Number, Issuer Serial Number, and AIA Issuer URL. We could also staple a signature, signed by the Namecoin address that owns the name. Encaya can then call out to Namecoin Core or Electrum-NMC to verify the signature.
Does this break freshness? Not really: the signature becomes stale whenever the name is transferred to a new Namecoin address. This means that if you don’t want to revoke your TLSA records that are stapled in this way, you must keep your name at the same address.
Address reuse is often frowned upon in Bitcoinland due to privacy concerns, but the privacy leakage that results from address reuse is already public knowledge in Namecoin: of course those two transactions were made by the same person, they’re for the same domain name and they point to the same IP address. Address reuse is also sometimes cited as an issue for quantum safety. That is technically true, but if a quantum computer starts attacking Bitcoin, you probably want better security than unique addresses will give you. Transitioning Bitcoin and Namecoin to post-quantum signatures is likely to be a better approach.
There is, of course, a practical issue with this scheme. Bitcoin Core doesn’t yet support message signatures with non-P2PKH addresses. Electrum does support P2WPKH addresses. Neither supports multisig addresses (or any other kind of smart contracts). So for now, this approach will only work if you’re using legacy (non-SegWit) single-key addresses; in terms of transaction weight, the witness discount will typically outweigh the benefit from moving TLSA records off-chain. Hopefully Bitcoin Core will fix this soon upstream.
The above has now been implemented into Encaya and ncgencert, and works fine with both AIA and PKCS#11. No changes were needed to ncp11. The ncdns Windows installer will need some small tweaks to relax Encaya’s sandbox so that it can talk to Namecoin Core.
This work was funded by NLnet Foundation’s NGI0 Core Fund.
generate_nmc_cert is now ncgencert
If you’ve used generate_nmc_cert to set up a Namecoin TLS server, you’ve probably found the interface a tad vexing. Examples of such weirdness:
- Why is the
-use-caargument always required? What happens if you forget it? - Why is the
-use-aiaargument sometimes required? - What the heck is the
-falsehostargument?
The answer is: prioritization of interface stability over UX. This may have made sense many years ago when the Encaya certificate format was still experimental, but by now everyone knows that we’re not going back to the pre-Encaya certificate formats (which is what you’d get if you forgot -use-ca or -use-aia, or if you used -falsehost).
I’ve now refactored the interface, as follows:
-use-cais always true. The code paths for when it was false have been sent to a luxurious permanent retirement; we thank them for their past service.-use-aiais now inferred based on whether parent or grandparent chains are specified. The code paths for when the aforementioned inference was wrong have also been sent to luxurious permanent retirement; we thank them for their past service as well.- All code associated with
-falsehosthas met the same fate, and received the same thank-you, as above.
To celebrate the new, more user-friendly interface, the tool has also been renamed to ncgencert. The old name generate_nmc_cert was a result of the tool’s code being a copy of a Golang standard library example called generate_cert; it was chosen with essentially no thought. In particular, it was inconsistent with existing convention for how Namecoin tools are named: application-layer tools generally are supposed to have nc as a prefix (e.g. ncdns, ncp11, ncprop279, and Encaya’s original spelling ncaia). The NMC abbreviation is supposed to be reserved for wallets and similar tools.
This work was funded by Power Up Privacy.
Hashed TLSA Records in Encaya
As long-time readers will be aware, probably the biggest innovation of Namecoin’s TLS functionality is that it uses a special form of TLS certificates that happens to work well in mainstream web browsers, via the interoperability magic of AIA and PKCS#11. This avoids having to patch web browsers or intercept TLS connections (either of which would introduce nontrivial security liabilities).
One of the consequences of this benefit has been that Namecoin domains must embed an ECDSA public key on-chain. ECDSA public keys, alas, are somewhat big. We worked around this, sort of, by using compressed public keys on-chain, and decompressing them on-the-fly before passing them to web browsers via AIA. This was still suboptimal for a few reasons:
- Compressed ECDSA public keys are still kind of big. Much bigger than a SHA-256 hash.
- Compressed ECDSA public keys aren’t supported by the Go standard library, so we had to maintain a fork of the standard library.
- Whatever escape hatch we get from using compressed ECDSA public keys won’t help us when TLS eventually moves to PQ signatures. (More on this in a future post.)
So, why did we need full public keys in the blockchain (as opposed to a public key hash) anyway? The constraints are as follows:
- Encaya needs to synthesize a CA certificate when the browser asks for it.
- This synthesized CA certificate needs to contain the public key that the domain owner picked.
- The browser will not provide any public keys that the TLS server presented in the certificate chain.
- Therefore, Encaya needs to get the public key from the blockchain, since there’s no other way to get it given the API constraints. QED. Right…?
Um, about that last assumption. Is there really no other way to get the public key given the API constraints?
Moreover, how does Encaya even know what domain name to look up in the blockchain? Could we get the public key that way?
Hmm…
Encaya gets the domain name from an AIA request (for Chromium-like browsers) or from a PKCS#11 request (for Firefox-like browsers). Why do these requests contain the domain name? Uh. Because we put the domain name there?
The AIA request contains whatever data is in the AIA Issuer URL field of a certificate sent by the TLS server. The PKCS#11 request contains whatever data is in the Issuer Distinguished Name (DN) field of that certificate. There’s no requirement that either of those fields contain the domain name. The DN does sometimes contain a domain name in the Common Name field, but that’s normally only a thing for end-entity certificates, not CA certificates. The AIA Issuer URL field definitely doesn’t normally have anything like that under any circumstances. In both fields, we deliberately put the domain name there so that Encaya would see it.
You probably see where this is going. Could we stuff a public key into the AIA Issuer URL and the Subject DN? It’d look pretty weird, but if you’re averse to looking weird, you’re probably not a hacker.
So here’s the new workflow:
- The AIA Issuer URL field of the CA certificate sent by the TLS server adds a new GET query parameter, containing a base64-encoded public key.
- The Subject DN field of that CA certificate’s parent CA adds a base64-encoded public key in the Subject Serial Number subfield.
- The Issuer DN field of the CA certificate matches the Subject DN of its parent, thus also including an Issuer Serial Number with a base64-encoded public key in it.
- When Chromium sees this certificate chain, it sends an AIA request to Encaya that includes the public key as part of the AIA Issuer URL.
- When Firefox sees this certificate chain, it sends a PKCS#11 request to ncp11 that includes the public key as part of the Subject DN or Issuer DN.
- Encaya can then compare this public key to the hashed TLSA record in the blockchain. It if matches, Encaya uses the public key in its synthesized CA.
- Chromium and Firefox don’t know that anything funky has happened. Sure, there’s an intermediate CA with a really long AIA Issuer URL and Issuer Serial Number. But Chromium and Firefox don’t care about that.
- On-chain savings achieved. We win!
I’ve implemented the above in Encaya, ncp11, and generate_nmc_cert. What do the savings look like?
- Before: 90 bytes of JSON per TLSA record
- After: 54 bytes of JSON per TLSA record
The TLS handshake, of course, contains a bit more data, but TLS handshake bytes are cheap compared to on-chain bytes.
Once this feature gets into a release, we will contact Namecoin HTTPS website operators in the wild (where feasible) to nudge them to upgrade their setup. Support for the previous certificate format will probably be dropped soon, because the maintenance burden of a standard Go crypto library fork is not a good use of my time.
This work was funded by Power Up Privacy.
What’s the maximum length of an AIA Issuer URL in Windows 11 CryptoAPI?
For those of you who haven’t seen my various conference talks about Namecoin TLS, AIA (Authority Information Access) is a mechanism for a TLS certificate to provide a URL where you can find the certificate of its issuer. Namecoin does some, uh, creative things with AIA. For reasons that will be elaborated on in a future post (don’t worry, all will be explained there), I wanted to know the maximum length of the URL that AIA can link to.
I had no luck finding any such limit in any relevant RFC, nor could I find anyone on the Internet who had documented any such limit, so I had to fall back to experimentation. I ended up writing a patched certificate generator and AIA HTTP server that could test whether arbitrary AIA URL lengths were usable to build a certificate chain. I then wrote a PowerShell script that tried various AIA URL lengths with Windows 11’s certutil -verify, to see what CryptoAPI’s limits were.
After running some tests, I have some answers:
- AIA URL lengths up to
65534bytes work fine. - AIA URL lengths
65535bytes and higher do not work.
I am not certain why the upper bound is 2 less than a power of 2. If it were 1 less than a power of 2, that would be sensible since that would indicate a length field that’s an unsigned 16-bit integer. My best guess is that Windows is using a strange data structure that uses both a 16-bit length field and a NULL terminator.
Checking CryptoAPI’s logs in Event Viewer indicates that none of the AIA-related code paths are running when the limit is exceeded.
Scope caveats:
- I only ran this test in Windows 11 24H2. I suspect that sufficiently old Windows releases are less tolerant.
- I don’t know what happens if you try to put Unicode in the URL.
- I would not expect to see the same limit in other TLS clients that implement AIA, e.g. macOS.
Should you wish to reproduce these results yourself (Science Rules!), the code should be included in the next release of Encaya.
This work was funded by Power Up Privacy.
Improving sockstrace: Debugging, Process Control, and Proxy Rules
sockstrace just got a major update. Here’s a quick overview of the new features:
Core Dump & Stack Trace
When a proxy leak is detected, sockstrace can:
Stack Trace: Extract a stack trace of the leaking process to show where in the code the leak occurred. This uses gdb behind the scenes, so the trace includes detailed symbol infomation (if available).
Core Dump: Creates a full core dump of the leaking process by sending SIGABRT. Before triggering it, sockstrace checks that ulimit allows dumping. The resulting core can be loaded into GDB for full post-mortem analysis, including memory, registers, and detailed traces.
Kill All Tracees (Including Children)
Previously, sockstrace only supported killing the specific PID that triggered the leak. In multi-process applications like browsers, this often left child processes alive, leading to inconsistent behavior or silent failures.
Now, it can recursively terminate the entire process tree rooted at that PID, ensuring:
- A clearer signal to the user that something went wrong (Avoid silent failures)
- No zombie processes are left behind
Whitelist for Incoming TCP Connections
You can now define a whitelist of allowed source IPs or subnets for incoming TCP connections.
sockstrace enforces the whitelist by intercepting the bind and listen syscalls: it parses the bind address from the syscall arguments, and on listen, it calls syscall.Getsockname to retrieve the actual bound address. This address is then checked against a user-defined whitelist, and if it doesn’t match, the bind is flagged as a leak or blocked based on the configuration.
This is useful because:
- It blocks unexpected incoming connections.
- It ensures only known gateways (e.g. Tor) are allowed to connect, as in Whonix-like setups.
- It catches misconfigured or unsafe behavior in network-facing apps.
SOCKS5 Handshake Enforcement
sockstrace now enforces SOCKS5 rules by intercepting the sendto syscall and parsing the actual handshake data.
Parse & Validate Structure: Verifies the SOCKS5 version, authentication methods, and field layout directly from the syscall. Rejects malformed or legacy handshakes.
Require Authentication: Flags connections that use no-auth (0x00) as leaks. This helps catch unsafe fallback behavior.
Tor-Compatible Isolation: Supports enforcing Tor-style stream isolation using SOCKS5 username/password fields. While implementing this, we also fixed a few typos and ambiguities in the Tor spec.
Regex-Based Rules: Users can define custom regex patterns for valid auth fields (e.g. session-*, profile-[0-9]+) to ensure proper identity separation.
This gives fine-grained control over SOCKS5 behavior and helps detect apps that bypass proxy isolation.
This work was funded by NLnet Foundation’s Next Generation Internet Zero Core Fund.
Namecoin will be at MoneroKon 5
We’re happy to announce that Namecoin will be giving a presentation at MoneroKon 5 in Prague, Czechia (June 20-22). Live streams are expected.
If you’re also attending and would like to meet up to discuss collaboration, please ping us on #namecoin-dev.
We’d like to thank Cyphrs for facilitating our participation. See you there!
Code Quality Improvements in ncp11
As you may recall, ncp11 is Namecoin’s PKCS#11 module that enables TLS to work for Namecoin domains with standard TLS clients that use NSS or GnuTLS. I’ve recently made several improvements to ncp11:
Add additional tracing
Namecoin’s PKCS#11 modules can log traces of their internal state, which can be helpful for debugging. I’ve expanded ncp11’s tracing to cover some additional state.
Disable Certificate Transparency
Modern versions of Firefox and Chromium mandate Certificate Transparency for all certificates by default. Namecoin, of course, cannot comply with this requirement, since the public CT logs don’t accept Namecoin certificates. (To some Namecoin users, this is a feature, not a bug.) This was causing CT errors to show up for Namecoin certificate chains.
I’ve changed ncp11’s trust bits to opt out of the CT requirement for all Namecoin certificates. This gets ncp11 working again in modern browsers.
Work around NSS blacklisting bug
NSS allows PKCS#11 modules to mark a CA as explicitly distrusted for root CA purposes, while still trusting them if they are issued by a trusted CA. ncp11 had been using this for all intermediate CA’s that it signed, but testing showed that NSS’s behavior doesn’t match the documentation, and this feature seems to be broken – marking a CA in this way will result in it being distrusted regardless of its issuer.
I’ve worked around this by making trust objects optional in p11trustmod, and making ncp11 not return trust objects for intermediate CA’s. This makes ncp11’s generated certificate chains substantially more reliable.
Set media type correctly on PEM responses
Encaya’s API endpoint for ncp11’s usage was returning PEM certificate bundles with the default text/plain media type. This is not really spec-compliant. I’ve made it return a proper application/x-pem-file media type. ncp11 itself didn’t care, but this does mean that using the Encaya web interface to download the Encaya root CA certificate will now produce a download dialog as expected, instead of showing a bunch of text in the web browser.
Unify AIA and PKCS#11 implementations
Encaya has two API endpoints: one for AIA usage, and one for PKCS#11 usage. There are a number of differences, mostly related to differences in how AIA clients and PKCS#11 clients query and cache things. These endpoints had substantial code duplication, which was not great for maintainability. I’ve factored out the common code into a lookupCert function. The result:
| Lines of Code (Before) | Lines of Code (After) | |
|---|---|---|
| AIA | 157 | 33 |
| PKCS#11 | 153 | 47 |
| Server Total | 902 | 802 |
The refactored code is much cleaner, easier to follow, and will facilitate decreased effort for future improvements.
This work was funded by Power Up Privacy.
Occlumask: A Content-based Anonymity Leak Detector
A few weeks ago, we announced funding from Power Up Privacy for a number of different projects. One of those projects being “Occlumask”. We will be giving some details about Occlumask, the motivations behind it, its methods, challenges, as well as the current status on research.
What is Occlumask?
Occlumask is an LLM-based tool for detecting content-based anonymity leaks. It is currently built off of the llama.cpp inference engine, running a local LLM instance. We are intending it to mainly be used in the context of chat messaging, forum posting or any other personal writing situation.
Occlumask Motivations
De-anonymization remains a pressing issue for privacy conscious users. To that end, there are many things a prospective anonymous person needs to keep track of to keep their identities hidden. Some of you may be familiar with stylometric analysis, where writing style preferences can be used to identify the writer of a text. Tools for obfuscating stylometry, such as Anonymouth, have existed for a long time. However, stylometry is only one axis of de-anonymization. Even if your stylometry is perfectly obfuscated, the content of your text can give your identity away.
A lot of information, even piecemeal, can be used to identify you (See Always Withhold your Identifying Data on the Whonix wiki for a non-exhaustive list). Famously, Jeremy Hammond was linked to the 2012 Stratfor email leak through various snippets of personal anecdotes posted in IRC. Keeping in mind human error, it becomes difficult to ensure that one follows all these rules. Occlumask aims to be an aide in this process, catching any lapses in judgment.
LLM Use Reasoning
Classification has been a long-standing use case for machine learning, and so it would follow naturally to use machine learning models to “classify” if a text is de-anonymizing. Neural networks have already been used in stylometric obfuscation in ALISON. LLMs present an interesting opportunity with their unique natural language comprehension capabilities. The increased ability for understanding context in particular allows for more accuracy, differentiating between significant and insignificant mentions of potential identifiers. For example, “[City] has terrible weather” vs. “[City] is well known for its cheeses”.
Challenges With Occlumask
The difficulties involved with using are both in the overall accuracy of the program, as well as the performance. LLMs are, to oversimplify, effectively non-deterministic. There is no guarantee that it will be completely correct in determining the presence of an anonymity leak. A large part of this project will be reducing uncertainty. Keep in mind that Occlumask is an aide, not a replacement for proper privacy practices.
Running an LLM locally is also computationally expensive. Occlumask is planned to allow for any GGUF-formatted model. This lets you run less demanding models (i.e. ones with fewer parameters or with more extreme quantization), in exchange for lower quality of output. We also want to minimize the amount of inference any given model does. As such, Occlumask won’t suggest any changes to your writing. It will only warn you that your text has an identity leak, how you handle it is up to you.
That being said, we still believe that Occlumask is a useful tool (otherwise we wouldn’t be making it!). It will still be reducing the amount of identity leaks that happen, and we will be working on reducing that amount as much as possible.
Current Progress
We are currently in the prompt engineering phase, getting the LLM to produce the outputs that we want, with an acceptable level of consistency. To this end, we are also collecting example texts to test our program on. So far the results have been promising, with the LLM being able to correctly identify what and why a section of identifying text is as well as surprising us on one occasion, with a potential identifier that none of us could find before Occlumask flagged it for us.
This work was funded by Power Up Privacy.
Enhancing Proxy Leak Detection with SocksTrace: From ptrace to seccomp notify
Initially, SocksTrace relied on ptrace to trace connect syscalls. While ptrace works well for simple programs, it wasn’t practical for high-performance applications, especially browsers.
Why switch to seccomp notify?
- Performance: ptrace slowed down applications significantly, making it impractical for real-time proxy leak detection.
- Scalability: Large, multithreaded programs like browsers were difficult to trace effectively using ptrace.
- More precise control: seccomp notify allows SocksTrace to intercept only the syscalls it cares about, without stepping through every syscall like ptrace does.
How the transition works
Instead of using PTRACE_SYSCALL to catch connect, SocksTrace now sets up a seccomp filter with SECCOMP_RET_USER_NOTIF. This allows user-space handling of specific syscalls, without the overhead of stepping through every process instruction. When connect is intercepted, SocksTrace can inspect the syscall parameters, decide whether to allow or deny it, and act accordingly.
Whitelisting syscalls
With seccomp, SocksTrace can define a strict policy that only allows necessary syscalls, blocking everything else.
Why syscall whitelisting matters
- Reduces the attack surface by preventing unnecessary syscalls.
- Ensures SocksTrace only intercepts network-related calls without interfering with other system behavior.
- Can be extended for different security policies.
Implementation details
Using go-seccomp-bpf, SocksTrace creates a seccomp filter that:
- Blocks all syscalls by default (ActionErrno).
- Explicitly allows safe syscalls like read, write and exit.
- Uses
seccomp.ActionTraceto intercept connect for analysis. This prevents unauthorized connections while ensuring minimal disruption to the application’s normal behavior.
Configuring TCP blocking
A new feature in SocksTrace allows users to decide whether to block incoming TCP connections.
How does it work?
By intercepting bind, accept, accept4, and listen, SocksTrace can monitor and control incoming TCP connections.
Configurable blocking options
Currently, SocksTrace offers two options for incoming TCP connections:
- Allow all incoming connections.
- Block all incoming connections (to prevent accidental exposure).
We are also working on an option to allow only specific addresses, adding more fine-grained control.
This work was funded by NLnet Foundation’s Next Generation Internet Zero Core Fund.
Namecoin Receives TLS and Anonymity Research Funding from Power Up Privacy and NLnet Foundation’s NGI0 Core Fund
We’re happy to announce that Namecoin is receiving three new grants:
- $25,760 USD from Power Up Privacy for anonymity research and development.
- Alice Margatroid is project lead.
- Jeremy Rand and Brandon Roberts will assist as needed.
- $24,480 USD from Power Up Privacy for TLS research and development.
- Jeremy Rand is project lead.
- Robert Nganga will assist as needed.
- 20,000 EUR from NLnet Foundation’s NGI0 Core (Next Generation Internet: Zero Core) Fund for TLS research and development.
- Jeremy Rand is project lead.
- Robert Nganga will assist as needed.
Anonymity R&D Grant
Most anonymity-related tools focus on preventing metadata leaks, e.g. Tor (prevents leaking your IP address metadata) and Mullvad Browser (prevents leaking your browser fingerprint metadata). However, there is another class of deanonymization vectors: the content of the communication itself. For example, mentioning the weather is an easy way to severely narrow your anonymity set. Alice is developing an automated tool that warns users if they are at risk of deanonymizing themselves in this way.
Namecoin has a solid history of developing privacy/security tools that aren’t strictly tied to the Namecoin blockchain, including SocksTrace, certinject, and pkcs11mod. This isn’t unusual in this space; Tor Project also routinely publishes research that isn’t strictly related to the Tor network. We’re excited to continue this trend.
TLS R&D Grants
Namecoin’s TLS support has a solid track record on scalability, including our innovations on layer-2 TLS. These grants will cover additional Namecoin scalability improvements, including fleshing out various functionality that Robert’s 38C3 talk covered. They will also cover collaboration with Tor Project on areas of TLS-related common interest, including fleshing out the onion service functionality that Jeremy’s 38C3 talk covered.
Our collaboration with Tor Project goes back many years, and we’re happy that this will be continuing.
Funding Sources
You’re probably familiar with NLnet Foundation by now, but if not, you might want to read about NLnet Foundation, or just take a look at the projects they’ve funded over the years (you might see some familiar names).
Power Up Privacy is a relatively new funder whom you may not have heard of, but they fund some familar names as well. Diversifying Namecoin’s funding has been a goal for a while now, and we’re pleased to add Power Up Privacy to our growing list of funders.
We’d like to thank the awesome people at NLnet Foundation for the continued vote of confidence, as well as the European Commision for their support of the Next Generation Internet. And a huge thank-you to Power Up Privacy for their new support!
Alice and Jeremy will be posting updates regularly as development proceeds.
38C3 Summary
As was previously announced, several developers represented Namecoin at 38C3 in Hamburg, Germany. You know the drill by now: we had a lot of conversations with other attendees, and we won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to us at conferences without worrying that off-the-cuff comments will be broadcast to the public. That said, a practical result of one of those conversations should be getting its own announcement in the next day or two.
There were multiple Namecoin-related talks at the Critical Decentralization Cluster (CDC). We’re still waiting for the official recordings to be published, but in the meantime, live-stream archives are provided below where available.
Lightning Talk: Intro to Namecoin
Speaker: Yanmaani
- Pretalx page
- Was not live-streamed; recording coming soon.
Lightning Talk: Intro to Sibermerdeka
Speaker: Rose Turing
- Pretalx page
- Was not live-streamed; recording coming soon.
A lost art: forgotten primitives for a decentralized web
Speaker: Yanmaani
There were many projects around the new millennium seeking to create decentralized/anonymous networks. Most failed, but they had some good ideas that died along with them. This talk will cover some “lost gems” from that era.
Most development within anonymous overlay networks the past 20 years has centered around low-latency networks (like Tor or I2P); networks that allow you to use conventional web applications and protocols. (like IRC, or whatever web applications you want)
High-latency networks don’t allow you to do this. They require you to re-build everything from the ground up. That’s why they never took off, but it also required clever people to spend a lot of time building interesting things.
This short talk will cover the primitives that were used to build things like decentralized web sites, search engines, identity systems, and even bulletin boards. While of little practical use today, the techniques in some ways exceed our current technology and ought to be remembered.
- Pretalx page
- Was not live-streamed; recording coming soon.
Not Your Keys, Not Your Name
Speaker: Adam Joseph
This talk will explain the benefits of decentralized protocols which use public keys directly as identities, and encourage this approach for newly-designed protocols.
The example familiar to the most CCC attendees is Tor onion names. At least 20 other protocols use this strategy as well. This talk will briefly survey those examples and explain the benefits of this approach for autonomy, decentralization, and ability to resist surveillance.
The main alternative to public keys is names controlled by some globally trusted party, such as US-ICANN, the DNSSEC root key, or the browser-vendors’ WebPKI appointees. This talk will explain the drawbacks of centralized alternatives.
If a protocol uses public keys as identities, it should allow users to keep their permanent private key offline. Private keys in online “secure elements” are not offline. Because an online device requires a network connection its physical location cannot be hidden; this means it can be seized or stolen and the keys extracted using a vulnerability like the one recently discovered in all Yubikeys and Infineon TPMs. Only a small number of protocols support offline identity keys. This support cannot be added to a protocol “after the fact”; it must be included from the very beginning. This talk will encourage protocol designers to include this feature from the very beginning, and will give concrete advice (“copy SSH or Tor”) on how to do it.
More details can be found here: https://codeberg.org/amjoseph/not-your-keys-not-your-name.
Self-Authenticating TLS Certificates for Tor Onion Services
Speaker: Jeremy Rand
TLS (the security layer behind HTTPS) and Tor onion services (anonymously hosted TCP services) are both excellent protocols. Wouldn’t it be nice if we could use them together? In this talk, I’ll cover a working implementation of combining TLS with onion services, without compromising on the security properties that each provides.
Topics to be covered include:
- Why would you want to combine TLS with onion services? Why isn’t onion service encryption good enough?
- Why isn’t unauthenticated TLS (e.g. self-signed certificates) good enough for onion services?
- How can we authenticate a TLS certificate for a
.oniondomain without relying on public CA’s like Let’s Encrypt or any other trusted third parties? (No we’re not using a blockchain.) - How can we teach standard (unmodified) web browsers like Firefox to apply different certificate validation logic for
.onioncertificates? - How can we teach standard (unmodified) web browsers like Firefox to validate certificates using typically-unsupported elliptic curves like Ed25519 (which Tor uses)?
-
How is teaching standard (unmodified) web browsers like Firefox to validate
.onioncertificates similar to Namecoin.bitcertificates? How is it different? - Pretalx page
- Live-stream archive on YouTube
Scaling Namecoin
Speaker: Robert Nganga
The DNS has an inherent scalability advantage over Namecoin. But that doesn’t mean we’re not going to optimize Namecoin as best we can. In this talk, I’ll cover several tactics we’re using to reduce the on-chain data stored by Namecoin — while minimizing the UX impact.
Topics to be covered include:
- Why is the Namecoin value size only 520 bytes?
- How can security improvements like cold storage support allow storing more data?
- How did we avoid putting TLS public keys in the blockchain?
- How are we compressing the data that goes into the blockchain?
- How are we shrinking the on-chain overhead of registrations of new names?
There may be bit of bonus content covering other Namecoin development.
Protecting Namecoin Users from Their Mistakes: Namecoin Wallet UX
Speaker: Rose Turing
If user mistakes cause their website to go down, that’s already bad — but not nearly as bad as if user mistakes make them permanently lose control of their website or get doxed and arrested. This talk is about how we’re helping Namecoin wallet users avoid mistakes before they cause irreversible consequences.
People are generally way more careless than we give them credit for, and all it takes for a full on security breach is one mistake, anywhere in the worst of cases. Our job in Namecoin is to prevent such incidents from occurring, and this means designing our UX in such a way that mistakes can be avoided by end-users. In this talk we discuss the consequences of mistakes on the user’s end as well as mitigations that have or will be implemented in Namecoin.
Topics to be covered include:
- Warning about likely-invalid domain configurations.
-
Preventing accidental expiration disasters.
- Pretalx page
- Live-stream archive on YouTube
Thanks
Huge thank you to The Critical Decentralization Cluster for facilitating our participation. We’re looking forward to 39C3 in December 2025!
This work was funded by NLnet Foundation’s Internet Hardening Fund, NLnet Foundation’s Next Generation Internet Zero Core Fund, and Cyphrs.
Namecoin will be at 38C3 and FOSDEM 2025
We’re happy to announce that at least three Namecoin developers will be at 38C3 (the 38th Chaos Communication Congress) in Hamburg, December 27-30. Additionally, at least two Namecoin developers will be at FOSDEM 2025 in Brussels, February 1-2.
We expect to give some talks, however, the details are still in flux and will probably not be announced until shortly before the beginning of the respective conferences; keep an eye on both the C3 and FOSDEM schedules to find us (or find our absence, if we are unlucky). Recordings and live-streams may happen as well.
As you may recall, last year’s Congress (37C3) was the first year that Namecoin stepped out from Monero’s shadow to form our own Assembly. This was a huge success for all involved, and the Namecoin Assembly is back this year. Of course, we remain close friends with Monero. Meanwhile this will be our first time attending FOSDEM, so we’re very excited to see what we’ve been missing all these years.
If you’d like to meet up with us at C3, the usual methods (c3nav, etc) should lead you to us. Meanwhile if you’d like to meet up with us at FOSDEM, you can say hello in the #namecoin-dev Matrix channel, or you can ask at the NLnet table and perhaps they may be able to point you in our direction.
Namecoin Core 28.0 Released (UPDATED)
Namecoin Core 28.0 has been released on the Downloads page.
Here’s what’s new since 22.0:
- RPC
- Disambiguate “expired” from “never existed” in
name_showerror message. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Disambiguate “expired” from “never existed” in
- GUI
- Disable configuring/renewing names that are unspendable due to expiration or transfer. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Clarify passphrase dialog to make clear that names are protected by the passphrase. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Clarify Receive tab to make clear that it can be used for name transfers. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Fix suboptimal Unicode usage in Manage Names tab. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Add “Export” button to Manage Names tab. (Patch by Jeremy Rand; Review by Daniel Kraft.)
name_firstupdateQt GUI. (Patch by Jeremy Rand; Review by Daniel Kraft.)- Add decoration for incoming and outgoing name transfers. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Add decoration for name renewals. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Move name operation into Type column. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Add icon for Configure Name button. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Show name count in Manage Names tab. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Check availability in Buy Names tab. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Show
.bitform ford/names inTransactionRecord. (Patch by Jeremy Rand; Review by Daniel Kraft.) - Show namespace in Type column of Transactions tab. (Patch by Jeremy Rand; Review by Daniel Kraft and Yanmaani.)
- Prioritize Data over Transfer in tab order in Configure Name dialog. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Avoid jargon in Configure Name dialog. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Show value size in Configure Name dialog. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Check for invalid JSON in Configure Name dialog. (Patch by Rose Turing; Review by Jeremy Rand and Daniel Kraft.)
- Check for non-minimal JSON in Configure Name dialog. (Patch by Rose Turing; Review by Jeremy Rand and Daniel Kraft.)
- Misc
- Use
fundrawtransactionmore in the suggested atomic name trades workflow. (Patch by Daniel Kraft; Review by Yanmaani.) - Add mainnet DNS seeds from s7r. (Patch by s7r; Review by Daniel Kraft and Jeremy Rand.)
- Fix missing
#includeinbuynamespage.h. (Patch by Zoltan Konder; Review by Daniel Kraft and Jeremy Rand.)
- Use
- Numerous improvements from upstream Bitcoin Core.
Known potential issues (will hopefully be resolved soon):
- Initial peer discovery may not work reliably over Tor.
- Setting
-fallbackfeemay be needed if you don’t want to wait some blocks before you can issue transactions. - The Buy Names tab only performs
name_firstupdate, notname_new; you’ll have to doname_newfrom the console first. - The Buy Names tab might require setting
-addresstype bech32 -changetype bech32. - Some GUI lag is present when switching to the Overview and Transactions tabs, and when scrolling in the Transactions tab.
- Old BDB-based wallets are no longer supported (per upstream policy). Migration of BDB wallets to the new Descriptor wallets is not thoroughly tested, so if you have high-value BDB wallets, you may want to back them up and keep an old version of Namecoin Core around until you are confident that your wallets migrated properly.
Why is it on the Beta Downloads page, you ask? As of this writing, we only have 1 set of Guix signatures, and we require 2 sets to do a release. For logistical optimization reasons, we have decided to upload the binaries and publish the changelog now. However, do not consider the release to be official until a 2nd set of matching Guix signatures has had a PR submitted (which we expect to be in the next week). We fully expect these binaries to be bit-for-bit identical to the ones that we place on the main Downloads page in a little while. If you see another set of matching Guix signatures by the time you read this, then you can safely conclude that these binaries are of the quality you would normally expect on the main Downloads page.
Huge thanks to Rose Turing and mjgill89 for Guix-signing this release. Also huge pre-emptive thanks to Robert Nganga for Guix-signing this release in the next week or so.
This work was funded by Cyphrs.
Namecoin’s SocksTrace Receives Funding from NLnet Foundation’s NGI0 Core Fund
We’re happy to announce that Namecoin is receiving additional funding from NLnet Foundation’s NGI0 Core (Next Generation Internet: Zero Core) Fund. If you’re unfamiliar with NLnet, you might want to read about NLnet Foundation, or just take a look at the projects they’ve funded over the years (you might see some familiar names).
This new funding is focused on SocksTrace. You might know SocksTrace by its former (and truly magical) name, Heteronculous-Horklump. While the former name was hilarious for Harry Potter geeks, we got feedback at 37C3 that it was too… let’s say, “unmemorable” for the rest of the world (especially for non-native English speakers); thus, we’ve seized the chance to simplify things with a name that’s easier on the brain. Don’t worry, though—the new name is still meme-worthy!
SocksTrace is a proxy leak detection tool designed for both CI testing and manual QA testing. It leverages the Linux ptrace feature to monitor socket syscalls that could potentially bypass a proxy.
Specifically, the following areas of development will be funded:
- Improved speed by whitelisting specific syscalls
- Handling incoming TCP (Transmission Control Protocol) connections
- Improved test coverage
- Enforce stream isolation
- Provide support for POWER systems
- SOCKSify DNS traffic
This work will principally be done by developers Jeremy Rand and Robert Nganga (who is the author of this post).
We’d like to thank the awesome people at NLnet Foundation for the continued vote of confidence, as well as the European Commision for their support of the Next Generation Internet.
We’ll be posting updates regularly as development proceeds.
Tor Meeting 2024 / GPN 22 / MoneroKon 4 Summary (UPDATED)
As was previously announced, Rose, yanmaani, Hugo, and I (Jeremy Rand) represented Namecoin at three conferences in Europe. This was an excellent series of events for a number of reasons, not least the fact that this is the first time we’ve ever had 4 Namecoin developers attending a single conference (our previous record was 3 developers, at 37C3). Expanding our team size has been a priority for a while, and it’s great to see that this is starting to pay off. Of course, there were major substantive benefits as well. As usual for conferences that Namecoiners attend, we engaged in a large number of conversations with other attendees. Also as usual, we won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to us at conferences without worrying that off-the-cuff comments will be broadcast to the public.
Notes/slides for Namecoin’s sessions at the Tor meeting, and recordings of Namecoin’s sessions at GPN and MoneroKon, are published below:
Tor Lisbon 2024: Self-authenticating TLS Certificates for Onion Services using a PKCS#11 module
Facilitator: Jeremy Rand
Onion services are self-authenticating. It is highly unfortunate that this isn’t presently the case for their TLS certificates. ahf already made a proof of concept for using onion service Ed25519 keys as a TLS CA, but this requires substantial browser modifications, both to the trust logic (browsers don’t know they should trust these keys) and to the crypto support (browsers don’t support EdDSA). However, there is hope! Mainstream browsers (including Firefox and Chromium) actually do expose APIs that (with a little creativity) can enable validating TLS certificates based on onion service keys. You don’t even need to recompile the browser. Let’s discuss the implications of this, and maybe make some plans!
Tor Lisbon 2024: Pluggable Transport Executables Compression
Facilitators: Jeremy Rand, Morgan Ava
The download size of Tor Browser is somewhat larger than would be ideal (even causing rejection in the Android Play Store recently). The Go-based pluggable transports take up a nontrivial portion. A potential solution lies within the well-regarded u-root project (a spin-off of Coreboot that one of Tor’s interns worked with recently). u-root includes a subproject called Go-Busybox, which can merge multiple Go executables into one meta-executable, thus de-duplicating library code via the standard compiler optimization process. Our initial experiments have shown significant space savings, and the savings further compound if Namecoin naming (which also uses Go) is included in the Tor Browser binaries. Is this a fruitful line of inquiry? Are there security implications that we should consider? Are there other tricks we can use to decrease the size of the PT binaries? Let’s discuss!
Tor Lisbon 2024: Refreshing Best Practices Guidelines for Tor-Friendly Applications
Facilitators: Jeremy Rand, Morgan Ava
Many years ago, some community members wrote up a Tor-Friendly Applications Best Practices document. The document has proven to be valuable, but parts are underspecified, and other parts will need revamping for Arti. This session is to refresh the document. Bring your ideas for things that Tor-friendly applications should do, and your horror stories of things Tor-friendly applications shouldn’t do.
GPN 22: Self-Authenticating TLS Certificates for Tor Onion Services
Speaker: Jeremy Rand
TLS (the security layer behind HTTPS) and Tor onion services (anonymously hosted TCP services) are both excellent protocols. Wouldn’t it be nice if we could use them together? In this talk, I’ll cover a working implementation of combining TLS with onion services, without compromising on the security properties that each provides.
Topics to be covered include:
- Why would you want to combine TLS with onion services? Why isn’t onion service encryption good enough?
- Why isn’t unauthenticated TLS (e.g. self-signed certificates) good enough for onion services?
- How can we authenticate a TLS certificate for a .onion domain without relying on public CA’s like Let’s Encrypt or any other trusted third parties? (No we’re not using a blockchain.)
- How can we teach standard (unmodified) web browsers like Firefox to apply different certificate validation logic for .onion certificates?
- How can we teach standard (unmodified) web browsers like Firefox to validate certificates using typically-unsupported elliptic curves like Ed25519 (which Tor uses)?
MoneroKon 4: Human-Meaningful, Trustless, Anonymous Monero Addresses with Namecoin
Speaker: Jeremy Rand
Monero addresses are already long and unwieldy, and they’re about to get longer with Jamtis. Namecoin is a DNS-like naming system implemented as the first project forked from Bitcoin, predating Monero by 3 years to the day. This talk will cover using Namecoin as a human-meaningful naming layer for Monero addresses, recent anonymity advances that make Namecoin’s privacy more suitable for this use case, how OpenAlias fits in, and how Namecoin compares to the MoneroDNS approach of creating a Monero sidechain for this purpose.
Thanks
Huge thank you to the following groups who facilitated our participation:
- Cyphrs
- The Replicant Assembly
- Cypherpunks
We’re hoping to return to these events next year.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Reducing Size With Concise Binary Object Representation (CBOR) and Name Gifting
Several new Electrum-NMC enhancements have been added.
Minimizing Size with Concise Binary Object Representation (CBOR)
Incorporating Concise Binary Object Representation (CBOR) offers significant advantages, including reduced data size and improved efficiency. Currently, to use CBOR, you need to convert your JSON data into CBOR format and paste the hex equivalent into the hex tab.

While this process can be a bit confusing, we are working to simplify it by providing an avenue to do the conversion directly within Electrum-NMC. Once you’ve pasted the CBOR hex data, you can confirm its validity by parsing it and displaying its contents in the DNS builder dialog, by clicking the DNS Editor button, you’ll see the different records contained in the CBOR data. Unfortunately, if you parse your CBOR hex data, you’ll need to paste it again in the hex tab, but we’re actively working to streamline this process.
With the addition of CBOR support in ncdns, after registering a name with a CBOR encoded value, ncdns should be able to parse and provide the DNS records associated with that name.
Gifting Names
Similar to requesting a payment, you can now also request a name. When registering a name that is available, you’ll see an extra button and field to request someone to pay for it on your behalf. Additionally, there is an extra field where you can add an additional amount to your request.
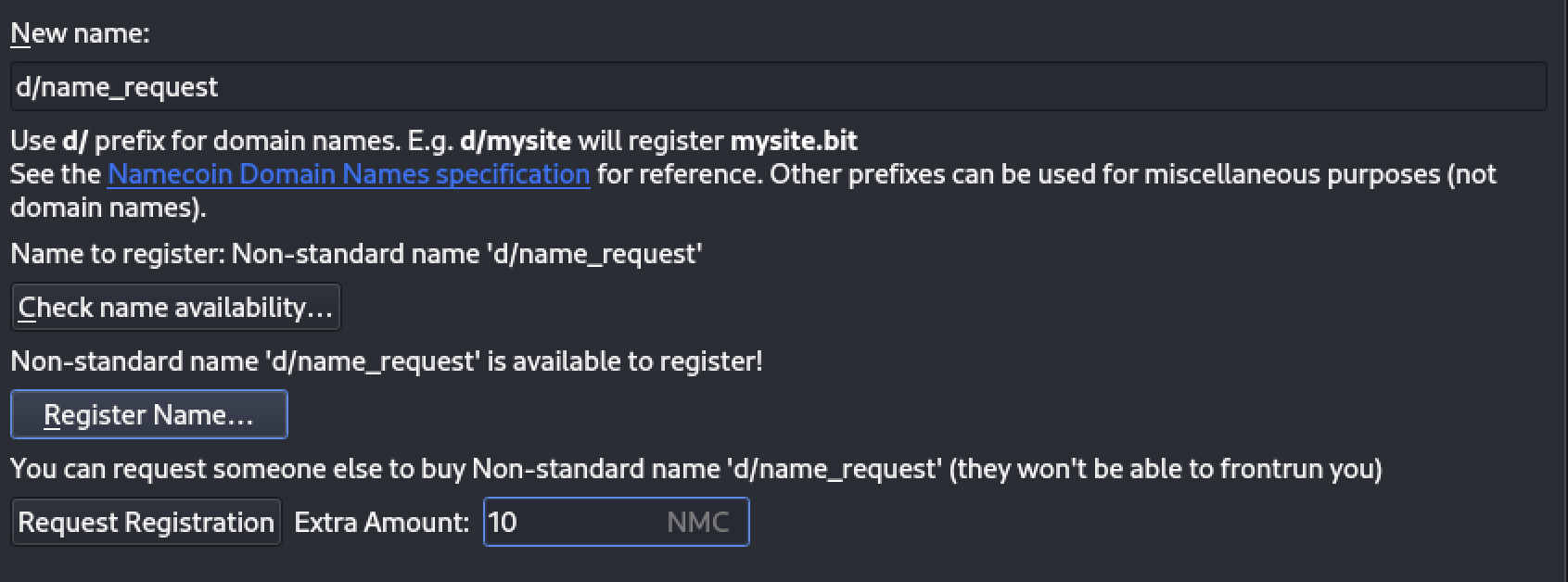
After clicking the “Request Registration” button, a UI with your request will be displayed, similar to what is seen in the request tab. From there, you can send the request URL or QR code to the recipient (gifter).
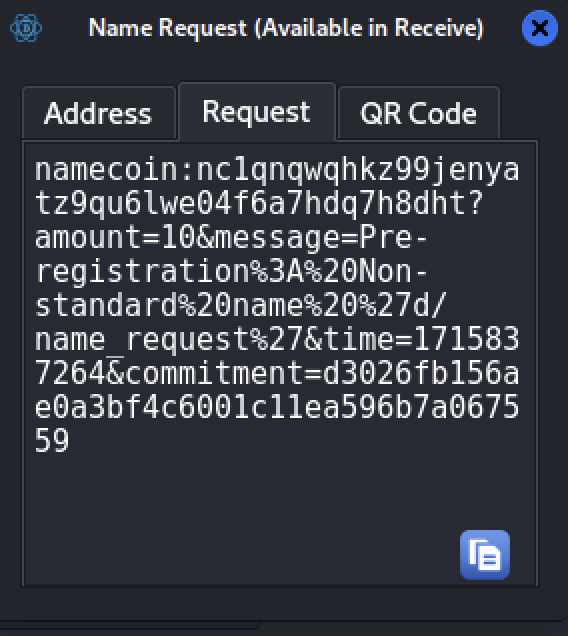
The gifter can now paste the payment URL in the receive tab or use the QR code. The details will be automatically populated, allowing the gifter to proceed with the payment.
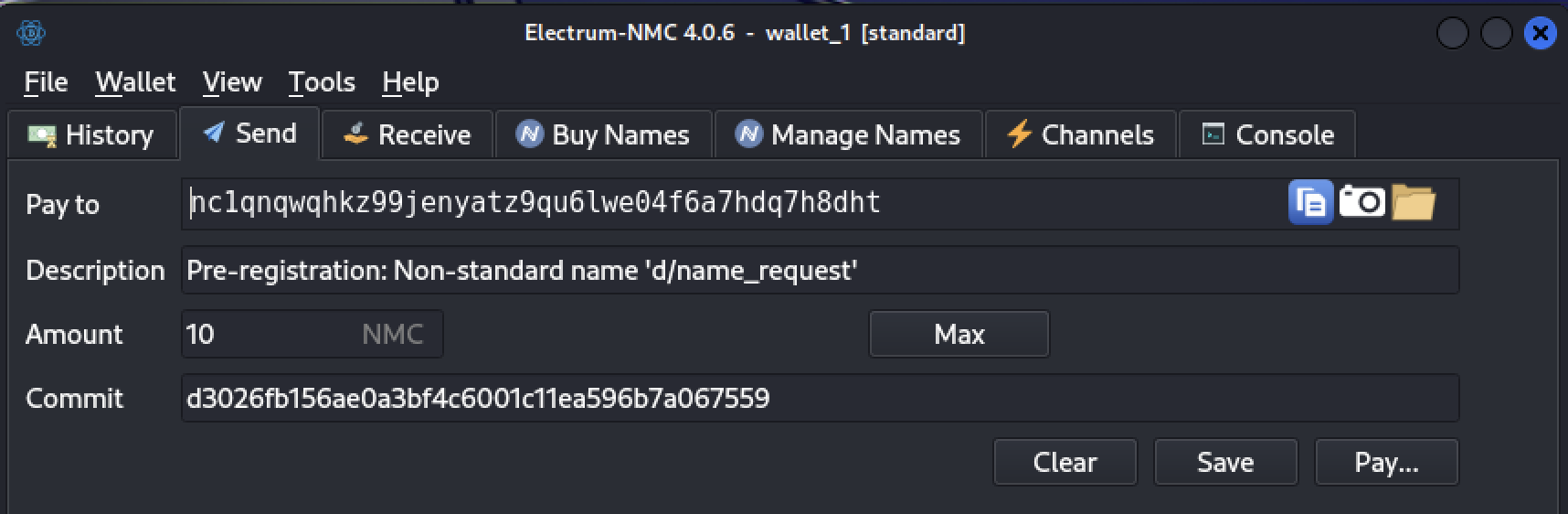
After your invoice is settled, you simply need to proceed with the normal name registration process. You’ll only be required to pay minimal update fees, as the name has already been paid for.
This work was funded by NLnet Foundation’s NGI Assure Fund.
Namecoin will be at Tor Meeting 2024, GPN 22, and MoneroKon 4
We’re happy to announce that Namecoin developers will be at multiple conferences over the next month:
- Tor Meeting 2024 in Lisbon, Portugal (May 20-24): Jeremy Rand will represent Namecoin during the main event; Jeremy Rand, Rose Turing, and Yanmaani will represent Namecoin during Community Day.
- GPN 22 in Karlsruhe, Germany (May 30 - June 2): Jeremy Rand and Rose Turing will represent Namecoin.
- MoneroKon 4 in Prague, Czechia (June 7-9): Jeremy Rand, Rose Turing, and Yanmaani will represent Namecoin.
As of this writing, schedules are not yet finalized, but details should be posted soon on the respective conferences’ websites. (We expect to host sessions at Tor, GPN, and MoneroKon). If you’re near any of these events and would like to meet up to discuss collaboration, please ping us on #namecoin-dev.
We’d like to thank Cyphrs, Replicant, and Cypherpunks for facilitating our participation at these conferences. See you there!
Electrum-NMC AppArmor, Static Analysis, and Input Validation + ncdns Unix Sockets
Several new Electrum-NMC & ncdns enhancements have been added.
AppArmor Profiles for Electrum-NMC
AppArmor is a Mandatory Access Control (MAC) system which confines programs to a limited set of resources. AppArmor confinement is provided via profiles loaded into the kernel. By using AppArmor profiles, we can ensure that Electrum-NMC operates within a predefined security policy, reducing the risk of unauthorized access or malicious actions. The profiles are provided in the contrib folder. For more information on AppArmor, visit their website.
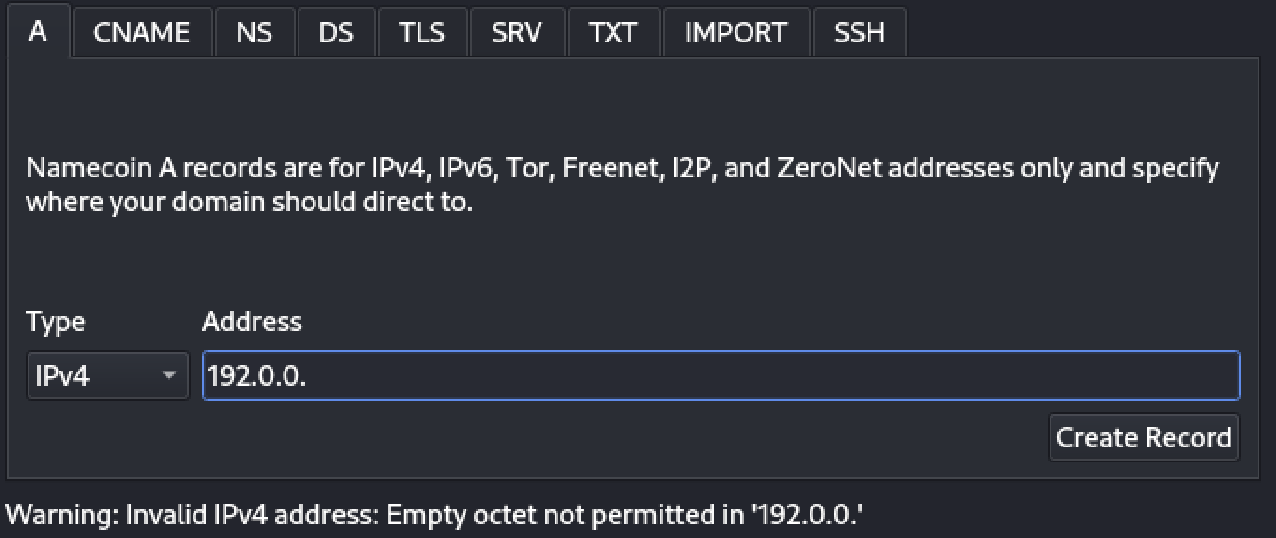
Input Validation in Electrum-NMC’s DNS Builder GUI
When passing data to the DNS Builder, certain validations are performed to offer hints and warnings about invalid data or outdated methods (such as algorithms).
Static Analysis Testing
We run static analysis using tools such as Flake8, MyPy, and Pylint, comparing results with Electrum (Bitcoin version) to focus on Electrum-NMC-specific issues. This process, integrated into our CI, helps catch bugs early. Looking to contribute? Static analysis issues provide good first-time issues!
Enabling ncdns to Perform RPC Requests via Unix Domain Sockets
Enabling ncdns to perform RPC requests via Unix domain sockets offers a more secure communication method than TCP/IP. To utilize a Unix domain socket, specify it in the namecoinrpcaddress field as unix:// + "your unix socket path" such as unix:///tmp/test.XXXX
Since Namecoin Core supports only TCP/IP, we’ll redirect RPC requests from the Unix Socket to Namecoin Core. This can be achieved using a commnad such as socat command:
socat -d UNIX-LISTEN:"my-unix-socket-path",fork TCP:"host-address"
socat -d UNIX-LISTEN:/tmp/test.XXXX,fork TCP:localhost:8332
This work was funded by NLnet Foundation’s NGI Assure Fund.
rust-electrum-client for Namecoin
Recently, I needed to use rust-electrum-client with Namecoin. I was kind of worried that this would be nontrivial, but as it turned out, I was able to get it working in just a few days of hacking, despite this being my first foray into Rust.
The main incompatibility that came up was that Namecoin headers have an AuxPoW header after the 80-byte Bitcoin-style header, and the deserialization functions in rust-electrum-client really didn’t like that trailing data. There were two deserialization functions that I had to patch to truncate the headers at 80 bytes, which got header parsing to work properly. My current patches are very unclean, and are not really suitable for publication, but I’m planning to clean them up and publish patches over the next few weeks.
Once this was done, a few non-code workarounds were additionally needed (more on these later!), and I was then able to use a real-world rust-electrum-client application with Namecoin. I’ll talk more in a future post about what downstream code is using this.
This work was funded by Cyphrs.
Video, Slides, and Paper from Namecoin at GCER 2022
This post is a bit late, but I represented Namecoin at the 2022 Global Conference on Educational Robotics. Although GCER doesn’t produce official recordings of their talks, I was able to obtain an amateur recording of my talk from an audience member. I’ve also posted my slides, as well as my paper from the conference proceedings.
It should be noted that, as this is an amateur recording, the audio quality is not spectacular. It should also be noted that the audience is rather different from the audiences for whom I usually give Namecoin talks; as a result, the focus of the content is also rather different from my usual Namecoin talks.
Huge thanks to the staff and volunteers from KISS Institute for Practical Robotics, who organized GCER. Also huge thanks to Helene Myers for the recording.
Enhancements to IPFS & IPNS: A Closer Look at the Latest Updates
Several new Electrum-NMC enhancements have been added.
The Dedicated GUI for IPFS & IPNS
Previously, interacting with IPFS required the creation of TXT records and knowledge of IPFS DNSLink. However, with the introduction of a dedicated GUI, users now have a more user-friendly option, available in the address tab. To learn more about DNSLink and its use of DNS TXT records to map names to IPFS addresses or IPNS names, refer to the IPFS DNS documentation.

Added Option for Value Encoding
When registering names, there is now an option to pass values as binary, encoded in hexadecimal format. This enhancement provides greater flexibility and control for developers and power users, allowing them to represent domain name values in a more efficient and versatile manner.
GUI Testing
For GUI testing, we validate the GUI form’s build process and execute regression tests, which helps us identify any errors in the files.
Windows Binaries Testing
We validate the integrity of the build process and conduct regression tests on these binaries to ensure their functionality and detect any potential issues.
This work was funded by NLnet Foundation’s NGI Assure Fund.
Electrum-NMC v4.0.6 Released
We’ve released Electrum-NMC v4.0.6. The changelog will probably be posted after 37C3.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
Namecoin will be at 37C3
After a lengthy pandemic-induced hiatus, C3 is finally back this year, and we’re happy to announce that three Namecoin developers will be at 37C3 (the 37th Chaos Communication Congress) in Hamburg, December 27-30.
Excitingly, one of our developers in attendance (Hugo Landau) will be giving a talk in the main track (not a Cluster track); the details for that talk are here.
We expect to give some additional talks and workshops at the Critical Decentralization Cluster (CDC), however, the details of those events are still in flux and will probably not be announced until shortly before the beginning of the Congress; keep an eye on the CDC schedule. Recordings and live-streams may happen as well.
In the past, Namecoin has participated in C3 as a Project of the Monero Assembly. We’re excited to announce that this year, Namecoin has been upgraded to a full Assembly of our own. Namecoin and Monero remain excellent friends, but everyone agreed that this year, the time was right for us to branch out as an independent Assembly. Also thanks go out to our friends at The Replicant Assembly, who are once again facilitating Namecoin’s participation. We’re looking forward to the Congress!
Namecoin Receives 40.1k EUR in Additional Funding from NLnet Foundation’s NGI Assure Fund and European Commission
We’re happy to announce that Namecoin is receiving 40,100 EUR (roughly 44,134 USD) in additional funding from NLnet Foundation’s NGI Assure Fund. If you’re unfamiliar with NLnet, you might want to read about NLnet Foundation, or just take a look at the projects they’ve funded over the years (you might see some familiar names). The NGI Assure Fund is managed by NLnet and funded by the European Commission, the executive branch of the European Union, through their Next Generation Internet intitiative. This new funding is focused on Electrum-NMC.
We will use this funding to work on the following:
- Improved sandboxing for better security.
- Improved test coverage.
- Improved domain management GUI for better UX.
- Compact on-chain storage for better scalability.
- Linux packaging.
This work will principally be done by developers Robert Nganga and Jeremy Rand (who is the author of this post).
We’d like to thank the awesome people at NLnet Foundation for the continued vote of confidence, as well as the European Commision for their support of a Next Generation Internet.
We’ll be posting updates regularly as development proceeds.
Binary Encoding Support and Testing Enhancements
Electrum-NMC has recently undergone significant improvements aimed at refining the user experience and expanding functionality. The most prominent changes involve the introduction of three distinct tabs within the graphical user interface (GUI): Hex, Domain, and ASCII. The Hex tab now serves as a dedicated space for users to interact with the hexadecimal representations of names, providing a standardized and transparent view of binary data. The Domain tab focuses on simplifying interactions by allowing users to employ a simpler format like “name.bit” instead of the original “d/name” format. Meanwhile, the ASCII tab preserves the original format of registration, ensuring compatibility for users who prefer the original format.
Graceful Handling of Invalid ASCII
In the event of invalid ASCII input, the system gracefully handles the situation. This allows valid hexadecimal data that is not a valid ASCII representation to be managed without disrupting the user experience.
AppImage Binaries Testing
A dedicated testing pipeline has been introduced for AppImage binaries. The regression tests run on these binaries to verify their functionality and identify any potential issues. This meticulous approach ensures that users working with AppImage binaries can trust in the stability and performance of Electrum-NMC.
MacOS Tarball Binaries Testing
For MacOS, a specific testing environment has been created to run regression tests on the tarball binaries. This testing setup not only verifies the integrity of the binaries but also ensures that Electrum-NMC performs seamlessly in a MacOS environment.
These testing procedures cover a range of scenarios and use cases, providing a robust framework to identify and address any potential issues before they impact end-users. The commitment to thorough testing underscores the project’s dedication to delivering a reliable and high-performance cryptocurrency wallet.
This work was funded by NLnet Foundation’s NGI Assure Fund.
SOCKSification: Outreachy Internship Progress
SOCKSification refers to the process of rerouting network traffic from an application via a SOCKS proxy server. This method is frequently used for security, anonymity, and circumventing network constraints. There are numerous techniques for SOCKSification, but in this article, we will focus on two main approaches that were considered.
The first method includes intercepting the application’s connect and send system calls. When an application wants to connect to a remote server, it performs a connect system call with the target IP address and port specified. Following that, the send system call is used to transfer data through the established connection.
With this method, we intercept the connect syscall and change the target IP address and port to those of the SOCKS proxy server. Then we intercept the send syscall which will contain a pointer (in tracee memory space) to the buffer that the application wants to send. We can prepend a SOCKS handshake to that buffer. While this method can accomplish SOCKSification, it necessitates changing the tracee’s memory, which is not memory safe and might cause security problems.
The second method, which is safer, includes utilizing the pidfd getfd capability, which was added to Linux v5.6, to duplicate the file descriptor of the established connection. When an application connects, the connect syscall returns a file descriptor, which may be used to transmit and receive data through the connection. We can replicate the file descriptor from the tracee to the tracer using the pidfd getfd functionality without having to touch the tracee’s memory.
To SOCKSify the program, we intercept the connect syscall and change the target IP address and port to those of the SOCKS proxy server. The exit of the connect syscall, which returns the file descriptor of the established socket, is then intercepted. Using pidfd getfd, we copy this file descriptor to the tracer and execute a SOCKS5 handshake with the tracer’s socket. After the handshake, we resume the tracee, and all future network traffic gets SOCKSified.
SOCKSification occurs in the function Socksify. This function allows an application running on a Linux system to use the SOCKS5 protocol to route network traffic through a proxy server.
The function begins by checking whether the “one circuit” configuration option is set. If not, it initializes a set of authentication data consisting of 10 SOCKS user+pass pairs. Each connection is then assigned to a randomly selected slot from those 10. This is important in order to prevent vulnerability to a Sybil attack. Applications that connect to a P2P network (such as the Bitcoin network) may need to avoid using the same Tor circuit for all connections. Otherwise, a malicious Tor exit relay can block the application’s view of the network. Furthermore, using a different Tor circuit for each connection can also be helpful for things like download managers, as it avoids slowdowns caused by an unlucky slow Tor circuit.
The function then reads the IP address and port number of the address we’re diverting from exit_addr, a thread-safe map. The address for each process that requires the SOCKS5 proxy is saved in the map.
The function then opens the file descriptor associated with the program’s network connection. With the os.NewFile function, the file descriptor is utilized to construct a new file object. The net.FileConn function is then called on the file object to generate a net.Conn object. This enables the application to communicate with its network connection using the standard net package rather than the lower-level system calls that were used to establish the connection.
The NewClient function is called, as well as the client’s Dial method. This creates a new client containing details such as authentication credentials and timeout values. The Dial method is then called, which carries out the redirecting. To listen to an existing net.Conn , we are currently utilizing a customized version of SOCKS5.
Relevant Links
SOCKS5 Repository We are planning to contribute the changes to the main SOCKS5 repository (Allowing the Dial Function to listen to an existing net.Conn file)
Heteronculous-horklump Repository: The main codebase.
Temporary Heteronculous-horklump Repository: Contains the SOCKSification work in progress, which will be soon be merged upstream.
This work was funded by Outreachy under the Tor Project umbrella.
Outreachy Internship Progress
Greetings! I wanted to provide an overall update on the project’s progress. We have successfully implemented the ability to detect the IP address and port that socket system calls are sending data to, as well as the capability to block system calls that are sending data to an IP address and port that is not the desired proxy. Additionally, we have added an option to kill the application if a proxy leak occurs, which is useful for manual QA testing, and an option to allow proxy leaks but log any that occur, which is useful for automated testing of applications. Furthermore, we have included the capability to use the environment variables that Tor Browser uses, such as TOR_SOCKS_PORT, to determine the desired proxy.
Lastly, we are currently in the process of implementing SOCKSification, which involves intercepting the connect syscall’s entry point, modifying the destination IP/Port, and capturing the established socket’s file descriptor through the exit of the connect syscall. A SOCKS5 handshake is then performed on the file descriptor. Afterwards, socks authentication enforcement and support of UDP proxies will be implemented. Socks authentication enforcement will detect if the tracee is using SOCKS without an appropriate username/password (stream isolation leak)
The program instructions are manipulated using flags through easyconfig which enables easy manipulation of arguments. Logging is done using xlog which provides different options for logging. U-root was preferred for tracing since it is easier to use.
Suggestions are much welcomed! Project Repository & Project Summary
This work was funded by Outreachy under the Tor Project umbrella.
Internship Progress
Greetings! I completed the initial tasks for the internship during the first week, where I utilized and experimented with the u-root strace package. The first tasks were to launch a program using ptrace and detect socket system calls. The first task was straightforward, requiring only the usage of the Trace Function. For the latter, it included utilizing a map to determine if the system call is a socket syscall and then informing the user if it is.
Later, I worked on the main tasks, which included determining the IP address and port on which socket system calls send data. I did this by first filtering out syscalls that initiate a socket connection, then sending the syscall through the SysCallEnter function. This returns a string containing the Address and Port, which we then extract using string slicing. Better methods will be developed to replace string slicing.
While resolving some of the issues, I am now working on blocking system calls that transfer data to an IP address+port that is not the targeted proxy.
This work was funded by Outreachy under the Tor Project umbrella.
Publishing of this post was delayed by infrastructure issues on Namecoin Project’s end; we apologize for the delay, which was not due to any fault of Robert.
Outreachy Blog #1: Introduce Yourself
Hello! My name is Robert, an Outreachy Intern. I spend most of my days gaming, coding and learning. I’ve been very interested in open-source projects, and two months after contributing to Namecoin, I started my internship. For the two months, the experience has been very enjoyable and interesting.
My Core Values
- Integrity: I believe in being honest and transparent in all my actions and decisions.
- Innovation: I value creativity and constantly strive to find new and better ways of doing things.
- Collaboration: I believe in working together with others to achieve common goals and create successful outcomes.
What motivated me to apply to Outreachy
Several factors influenced my decision to apply to Outreachy. To begin, I am really interested in open source and want to obtain practical experience in this subject. Outreachy is a fantastic chance for people like me to contribute to open source projects while learning from experienced mentors.
Second, I am enthusiastic in learning new things and honing my talents. Outreachy provides a structured internship program in which I may work on difficult projects while developing my technical and professional abilities.
Finally, I feel Outreachy will give me with beneficial networking chances. I am looking forward to meeting other Outreachy participants and mentors and developing contacts that will benefit my career.
This work was funded by Outreachy under the Tor Project umbrella.
Cross-posted from Medium. The cross-posting was delayed by infrastructure issues on Namecoin Project’s end; we apologize for the delay, which was not due to any fault of Robert.
ncp11 Nightly Builds Now Available
More work has been done with pkcs11mod and ncp11.
First off, a bunch of additional missing functions have beeen added to p11mod. A lot of these functions came from Oureachy applicants, since I used pkcs11mod as a contribution task repo for Outreachy. Some of these previously-missing functions may be useful to smartcard use cases, so if you’ve been holding off on touching p11mod for a smartcard project, it may be time to look again.
Next, I discussed the p11 API with Miek, specifically some shortcomings that make it hard for Namecoin to emulate the p11 API. We’ve agreed that Namecoin will maintain a fork with API changes for about 6 months, and then I’ll submit the changes upstream once I’m satisfied that it works in production. The changes have a Concept ACK. p11mod has beeen updated to use the fork.
The p11trustmod library is fully working now, although there are no integration tests for it yet. But how did I test it, then? The ncp11 codebase has also now been rewritten to use p11trustmod! Currently it only does positive overrides, and I’ve only tested it with Firefox on GNU/Linux, but it works. For reference, the old ncp11 was 1351 lines of code; the rewrite is only 228. Not a bad result; seems the abstraction work done on p11mod and p11trustmod was well-worth it. There is currently a quirk where ncp11 has to mark intermediate CA’s as trusted; only marking the Namecoin root CA as trusted does not make the certs pass validation. I intend to debug this later, but trusting intermediate CA’s is harmless here.
For anyone who wants to play around with this, ncp11 Nightly builds are now available on the Beta Downloads page. You’ll also need a Nightly version of Encaya, as a bunch of bugfixes were needed on the Encaya side. Installation instructions don’t exist yet, but if you know how to install Encaya, and you know how to install PKCS#11 modules into Firefox (e.g. for smartcards), you should be able to figure it out.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Introducing Namecoin’s New Intern, Robert Nganga
Hey everyone, Jeremy here. We’re happy to announce that Namecoin has accepted an intern via Outreachy (we are participating under the Tor Project umbrella). Robert Nganga will be funded to work on a new project that I think both the Namecoin and Tor communities will find exciting. Huge thanks are due to Tor Project for taking us under their wing for this internship. I don’t want to steal his thunder any more than I already have, so I’m going to turn over the remainder of this post to Robert to tell you about his project – please join us in welcoming him to the Namecoin community!
Greetings, I am pleased to join the Namecoin team as a Outreachy Intern after two months of contributing to Namecoin. I’ll be working on developing a tool that can identify and prevent proxy leaks. I’ll be using ptrace to intercept network socket system calls in a Tor-using application and block them if they constitute a proxy leak. Given the substantial threats posed by proxy leaks, the technology will improve security and privacy while resolving current problems with the technologies already in use. For instance, torsocks, an LD_PRELOAD-based program that intercepts calls to the network functions of the standard C library, is incompatible with statically linked software, such as the majority of Golang-written applications (Given that Golang is frequently used for security-conscious applications, this is particularly problematic) Transparent proxy tools like Whonix can result in usage of multiple applications being traceable to the same user, since you can’t easily enforce stream isolation (degrading anonymity into much weaker pseudonymity)
Furthermore, prior Namecoin development such as the Namecoin support in Tor Browser, was for a period slowed down by manual audits for proxy leaks. In the future, the tool will prevent such bottlenecks. This ptrace approach has a crude proof-of-concept in Bash, which was developed by the Namecoin team.
The project will be mentored by Jeremy Rand, who will also provide any support required.
This work was funded by Outreachy under the Tor Project umbrella.
Anonymity Improvements in Electrum-NMC v4.0.6
Electrum-NMC v4.0.6 (soon to be released) brings some long-awaited anonymity improvements.
Automatic Coin Control for Names
I first described this feature in my 34C3 presentation on anonymity. There’s not much else to say here; my presentation covers how the feature works and why that design was chosen. The delay between 34C3 and implementation is due to the preferences expressed by the Tor developers, hopefully it was worth the wait.
Whonix/Tails Support
Various anonymous OS’s such as Whonix and Tails come with Tor preconfigured. A major component of how these OS’s handle preconfiguration is via environment variables that tell Tor-friendly applications such as Tor Browser and OnionShare where Tor’s SOCKS port is. Electrum-NMC now supports these environment variables, so it will automatically use the correct SOCKS port (with stream isolation) on Whonix and Tails instead of relying on transproxying.
As part of this work, I engaged with the Tor Applications Team on improving the specifications for Tor-friendly applications. This work has been slower than hoped, but some major improvements have already worked their way through the review process, and I expect to deliver more improvements to these specifications in the coming months.
AppArmor Sandboxing Support
Besides environment variables, another trick that Whonix uses to Torify applications is usage of AppArmor to blacklist traffic that doesn’t go through Tor’s SOCKS port. This works by having Tor listen on a Unix domain socket, and then blacklisting IP sockets via AppArmor; standard filesystem ACL’s take care of the rest. Electrum-NMC now supports connecting to a SOCKS proxy via a Unix domain socket, so it should now be possible to enforce Torification via AppArmor.
So far, no one has written such an AppArmor policy for Electrum-NMC; this will be the subject of future work.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
Changes to name_show in Electrum-NMC Protocol v1.4.3
In my 36C3 presentation (seems so long ago…), I mentioned some future changes I wanted to make to the Electrum-NMC protocol. Some of these changes have recently been implemented:
Verifying Unconfirmed Transactions
For security reasons, Electrum-NMC has historically required 12 confirmations before it accepts a name transaction. Unfortunately, waiting 2 hours (on average) for a name update to take effect is not great UX, and also introduces its own security issues (e.g. it means that TLS revocations are unnecessarily delayed). When evaluating security of name transactions, there are two different attacks that we need to consider:
- Hijacking attacks
- Double-spend attacks
Hijacking attacks occur when a malicious miner mines a Namecoin block with an invalid scriptSig, which (if accepted) would allow them to hijack an arbitrary name without any participation from the name owner. In contrast, double-spend attacks occur when a malicious name owner signs two different name updates with the same input, which (if accepted) would allow one of those name updates to be accepted even though only the other update is part of the longest blockchain.
In practice, while any name could be targeted by a hijacking attack, only names that have recently been transferred to a new owner can be targeted by a double-spend attack. (Double-spending a name that you still own doesn’t really confer any benefit.) Since the vast majority of names have not been transferred in the last 12 blocks, if we can prevent hijacking attacks, we can accept the risk of double-spend attacks, since the latter can easily be mitigated by waiting 12 blocks from receiving a name transfer before using that name for critical purposes.
Can we do this? Ryan Castellucci proposed many years ago that we could verify the scriptSigs of recent name updates, chaining them back to a previous name update that has sufficient DMMS confirmation (i.e. 12 blocks). I have now implemented this in Electrum-NMC Protocol v1.4.3; Electrum-NMC will retrieve recent updates to a name (from 1 to 11 confirmations) and verify scriptSigs to chain them back to the most recent update with at least 12 confirmations. The result is that name updates now take effect in 1 block (~10 minutes) instead of 12 blocks (~2 hours).
Checkpoint Verification
One of the inherent problems with the SPV threat model is that it only verifies DMMS signatures (attached to blocks), not scriptSigs (attached to transactions). This means that an attacker with a majority of hashrate can mine invalid blocks (e.g. that hijack names) that will appear valid to SPV clients. Full nodes are, of course, immune to this, since they check scriptSigs on all transactions.
Unfortunately, full nodes have a much longer IBD duration, and also are much more resource-intensive. Can an SPV client verify scriptSigs on the transactions it cares about? In Bitcoinland, this is not really feasible, because the fungible nature of bitcoins means that you’d have to verify every transitive input to every transaction you care about, which would probably be exponential with respect to the verification depth. However, in Namecoinland, we don’t have this problem. The nonfungible nature of Namecoin names means that the number of transitive inputs grows linearly, not exponentially.
Thus, we can reuse the scriptSig chaining trick to chain the latest confirmed name update back to a previous update that was committed to in the checkpoint (if such an update exists). This means that in order to hijack a name that existed at the checkpoint height, an attacker would need to compromise both a majority of hashrate and the full node used to generate the checkpoint. I’ve implemented this in Electrum-NMC Protocol v1.4.3 as well; Electrum-NMC will retrieve all updates for a name going back to just before the checkpoint height, and verify the chain of scriptSigs.
One Round Trip
Electrum-NMC’s protocol has always been inefficient for name_show, because it needed to issue 4 commands to the ElectrumX server per name:
- Get the latest name update txid.
- Get the transaction preimage.
- Get the Merkle proof tying the txid to the block header.
- Get the Merkle proof tying the block header to the checkpoint.
The latter 3 of those could be issued in parallel, but that still means a best case of 2 round trips per lookup (and the best case was not always achieved in practice). Especially over Tor, this extra latency is a major UX problem. This inefficiency was a result of the upstream Electrum protocol for Bitcoin not being designed for Namecoin’s use cases. As of Electrum-NMC Protocol v1.4.3, there is a dedicated command for name_show, which combines the above 4 commands into 1, thus cutting down the lookup time to a single round trip. The above scriptSig-related features are also integrated into the dedicated command, so retrieving the extra transactions does not incur any extra round trips.
Future Optimizations
Electrum-NMC Protocol v1.4.3 also allows the ElectrumX server to send hint data for names other than the requested one. For example, if d/wikileaks imports from dd/wikileaks, the server might return data for both d/wikileaks and dd/wikileaks when the client requests the former, thus saving a round trip if the client would have asked for the latter name next. At the moment, the hint data is left unpopulated, but we should be able to start populating it in the future without needing another protocol change.
Deployment
Electrum-NMC and upstream ElectrumX have both merged Protocol v1.4.3, so we’re now waiting for server operators to update. Once we’ve determined that enough server operators have updated, we expect to flip a switch in the Electrum-NMC source code that enables the new protocol features. This functionality should also work out of the box in other ElectrumX-supported coins that use a name index, which in practice means Xaya.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
winsvcwrap: Open source replacement for SRVANY in Golang
Unlike *nix platforms, system services on Windows must be specifically designed to run as services, and written against the Win32 Service APIs. This creates a problem when it is desired to run a program as a Windows system service which was not designed to function in this role.
SRVANY.EXE is an executable distributed by Microsoft in the Windows NT 4.0
Resource Kit, which can be used to adapt any program into a system service.
SRVANY.EXE is configured as the system service, and it spawns and supervises
the target process in turn. Thus, it forms an adapter between the Windows
service manager and arbitrary programs. However, SRVANY is a proprietary
binary for which source code is not available, and is no longer even
distributed by Microsoft.
winsvcwrap is a simple open source Go
program to replace SRVANY and provide equivalent functionality, and is now
used by the Namecoin project to power its Windows installer bundle. This
enables the Namecoin project to avoid depending on an unmaintained proprietary
component. It can be used by anyone seeking to run arbitrary Windows programs
as Windows system services. Since it is written in Go, it is memory-safe
(unlike C/C++) and bootstrappable (unlike Rust).
This work was funded by Cyphrs.
Hacktoberfest 2022
Namecoin is participating in Hacktoberfest 2022. If you’re interested in contributing to Namecoin, Hacktoberfest is a great chance to start (and maybe win a t-shirt).
The list of Hacktoberfest issues for Namecoin is here. Of course, we welcome other PR’s as well.
Namecoin Core 22.0 Released
Namecoin Core 22.0 has been released on the Downloads page.
Here’s what’s new since 0.21.0.1:
- RPC
- Deterministic salts. (Reported by s7r; Design by Ryan Castellucci and Jeremy Rand; Patch by Yanmaani; Review by Daniel Kraft.)
- Transaction queue. (Patch by Yanmaani; Review by Jeremy Rand and Daniel Kraft.)
- GUI
name_listQt GUI. (Patch by Jeremy Rand; Review by Brandon Roberts, Randy Waterhouse, and Daniel Kraft.)name_pendingQt GUI. (Patch by Jeremy Rand; Review by Daniel Kraft.)- Edit contents of model instead of resetting. (Patch by Jeremy Rand; Review by Daniel Kraft.)
name_updateQt GUI. (Patch by Jeremy Rand; Review by Daniel Kraft.)- Name renew Qt GUI. (Patch by Jeremy Rand; Review by Daniel Kraft and Randy Waterhouse.)
- Add Renew Names button. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Fix double lock when creating a new wallet. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Name decoration in Qt GUI. (Patch by Jeremy Rand; Review by Daniel Kraft and Brandon Roberts.)
- Misc
- Fix name operations in descriptor wallets. (Reported by Jeremy Rand; Patch by Daniel Kraft; Review by Jeremy Rand.)
- Rebrand Cirrus build directory. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Rebrand Guix. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Add mainnet DNS seed from Jonas Ostman. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Update hardcoded seeds. (Patch by Jeremy Rand; Review by Daniel Kraft.)
- Fix some AuxPoW CI errors. (Reported by Jeremy Rand; Patch by Daniel Kraft.)
- Numerous improvements from upstream Bitcoin Core.
pkcs11mod progress: Windows, macOS, certutil support, and more!
Lots of things have been done with pkcs11mod since my last post on the subject. This is going to be a bit of a “grab bag” post without much structure (because that’s what reality looks like here, and this post is intended to reflect reality).
I noticed that the Chromium tests were hanging. After a bit of investigation, I found that the flags I was passing to Chromium to make it run in Docker weren’t quite sufficient. The alpine-chrome project has a more thorough set of flags, and applying these to pkcs11mod’s test scripts got the tests passing again.
I implemented the GenerateKeyPair function in p11mod, which got the test-rsapub OpenDNSSEC test passing. Thanks again to OpenDNSSEC for the test!
I noticed that trying to use either of the proxy modules with a nonexistent target module path resulted in a Go panic. This is not good, since a panic will crash the host application. Now this is mitigated by both pkcs11mod and p11mod checking for initialization errors, and returning CKR_GENERAL_ERROR, which is used by the PKCS#11 specification to indicate an error that is probably not recoverable. The application can handle this however it likes, but whatever it does will probably be better than crashing.
When trying to test pkcs11mod on Windows, I noticed that it failed very early. So early that the Go runtime never even tried to initialize. By comparing pkcs11proxy.dll to nssckbi.dll in Dependencies, I found that pkcs11mod was failing to export the C_GetFunctionList function, which caused applications to conclude that pkcs11proxy wasn’t a PKCS#11 module. That explained the symptoms. But wait, didn’t ncp11 work on Windows back when it was first released? Yes. Some digging found that this regression was caused by the fix for Go issue 30674. (Apparently, Go used to export all functions, and Windows has a tendency to crash if you export too many functions, so Go now requires developers to explicitly designate which functions will be exported.) I fixed this via the __declspec(dllexport) attribute. And now, pkcs11proxy is detected as a PKCS#11 module on Windows.
I fixed the documentation (and Cirrus scripts) to generate libraries with the idiomatic pkcs11proxy.dll filename on Windows targets, instead of the libpkcs11proxy.so filename that’s supposed to be only a Linux thing. Not a big deal, but correct documentation is important.
I added a trace mode (hidden behind an environment variable) to both pkcs11mod and p11mod, which makes it easier to follow what PKCS#11 calls are being issued. Be warned, even running a proxy module for a minute or so can produce a trace log of over a megabyte, so this should not be done routinely. Not all functions are traced yet; I’d happily accept PR’s to add more detailed tracing.
I added a test for tstclnt on Debian, and noticed that it was failing. Further investigation showed that tstclnt was failing to read the trust bits from the CKBI module when pkcs11proxy was in the middle. This was odd, because I was already testing tstclnt on Fedora, and it worked fine there. The obvious difference was that Fedora uses Red Hat’s p11-kit CKBI module, while Debian uses Mozilla’s CKBI module. Fedora’s replacement is supposed to be compatible with Mozilla’s version, but clearly the Red Hat CKBI module was doing something different from Mozilla’s, and my code was expecting the behavior of Red Hat’s module. Using the trace mode (see above paragraph), I figured out what was going on. NSS queries for 4 different EKU trust attributes: TLS server authentication, TLS client authentication, email, and code signing. (Clearly NSS could get away with only querying for TLS server authentication in this case, since tstclnt isn’t doing anything with the other three, but they don’t do that optimization here. Which is probably okay, since most of the time, the extra queries won’t harm performace.) Red Hat’s CKBI module contains trust bits for all 4 of those EKU attributes. Mozilla’s CKBI module, however, omits the TLS client authentication attribute. This makes sense, I guess, since the Mozila root CA program is not intended to be used for TLS client authentication, while Red Hat’s CKBI module incorporates certificates added by the user, which might be used for that EKU. Here’s where the problem happens: NSS queries for all 4 trust attributes in a single GetAttributeValue function call. Per the PKCS#11 specification, if any of the attributes in a oneshot query are missing, some extra error bits are returned, so that the caller knows which attributes existed and which didn’t. However, Miek’s pkcs11 library doesn’t handle this case; it instead just returns an error, causing pkcs11mod to lose the trust bits attributes that did exist. Patching Miek’s library seemed like an overkill approach, so I instead rigged pkcs11mod to detect the CKR_ATTRIBUTE_SENSITIVE and CKR_ATTRIBUTE_TYPE_INVALID error codes, and retry the attributes one at a time to figure out which ones we can return to the application. This isn’t ideal performance-wise, since we end up retrieving the attributes twice, but the difference should be negligible in the real world. And with that, tstclnt on Debian passed the tests.
Upstream p11 v1.1.0 added some named errors, which allowed me to avoid recognizing those errors via a brittle string comparison. That makes my code cleaner, which is good.
I added tests for Firefox and Chromium on Debian, which passed immediately (presumably because of the above tstclnt fixes).
I added tests for Firefox (both ESR and Nightly) on Windows. These mostly passed, but I did need to fix the logfile output paths, since $HOME is not a thing on Windows. The logfile is now saved to os.UserConfigDir(), which behaves sanely on all major OS’s. It falls back to the current working directory if the user config directory isn’t accessible for some reason (e.g. sandboxing).
I then added some more Firefox variants on Windows: Firefox Rapid Release, Firefox Beta, Firefox Developer Edition, LibreWolf, and GNU IceCat. They all passed. I also tried to add Waterfox and Pale Moon, but Waterfox hung on the install step in my Cirrus VM, and Pale Moon doesn’t support the headless screenshot feature, which my tests rely on. My guess is that both of them would work fine outside of my test environment.
Next, I added tests for certutil (the NSS tool, not the CryptoAPI tool of the same name). Specifically, I dumped the CKBI certificate list, with trust bits, via pkcs11proxy and p11proxy, and compared the output to what I got without the proxy. Surprisingly, this turned out to be a giant gopherhole [1]. Dumping the certificate list caused certutil to segfault halfway through dumping when proxied – but only on Windows, and only via p11proxy (pkcs11proxy didn’t segfault). Inspecting logs revealed that certutil was calling the CloseAllSessions function, which p11mod didn’t implement. I implemented that function (it was pretty simple), but this didn’t fix the segfault. I enabled the trace mode that I had previously added, and found that it was segfaulting after the Finalize function had returned, which seemed odd, since that meant my code had already finished running by the point of the segfault. After some confusion, I found Go issue 11100, which described my problem: certutil had tried to unload p11proxy.dll, which yanked some data structures out from under the Go runtime, causing a segfault. There is a way to instruct Windows (via the GET_MODULE_HANDLE_EX_FLAG_PIN argument to the GetModuleHandleEx Windows API function) not to ever unload a DLL file until the application exits. Conveniently, the golang.org/x/sys/windows package (nicknamed goxsys/windows by the Tor folks [2]) has support for this. I tried it out, and sure enough, that fixed the segfault.
However, this introduced a new issue. Now, certutil wouldn’t segfault, but it would hang after outputting the entire certificate list, until I hit Ctrl-C in the command prompt. Go issue 11100 had some mention of this occurring in Unity: apparently some applications wait for all background threads to exit before closing the program, and the Go runtime (which never terminates) is being recognized as such a background thread. In theory, this is an application bug, but pkcs11proxy is supposed to leave the behavior of buggy software unchanged, so this was something I couldn’t just ignore. Alas, I didn’t find a clean way to solve this. So I did the dumb approach: when the Finalize function is called, pkcs11mod starts a 5-second timer in a goroutine, which then calls os.Exit(0). Sometimes the dumb approach is the best option that presents itself.
Unfortunately, this meant that now, if an application tries to unload pkcs11mod, the application will be forcibly closed 5 seconds later. This works fine for applications like certutil which will exit right after that point anyway. But in Firefox, you probably don’t want your browser to kill itself 5 seconds after you click the Unload button in the Security Devices dialog. So, what to do…?

Yep, once again, sometimes the dumb approach is the best option that presents itself. We simply check the process name that pkcs11mod is loaded into. If it’s certutil.exe, we start the 5-second exit timer; otherwise, we don’t. The number of applications that exhibit this bug is, I’m guessing, small enough that we can simply enumerate them.
This got the certutil tests passing. However, now the Firefox tests on Windows were failing. Inspection of Firefox stderr indicated some error messages about a tab subprocess failing to start. A DuckDuckGo search for these errors indicated a Bugzilla thread where the reporter said that disabling the Electrolysis sandbox fixed a crash. I added some Cirrus tasks that ran my usual Firefox tests but with Electrolysis disabled. Sure enough, those tests passed. I initially figured that my usage of GetModuleHandleEx, or perhaps my attempt to read the process name, had violated some kind of sandbox policy, but after bisecting my recent changes, I came to a surprising conclusion: the thing that crashes Electrolysis is simply the act of importing the goxsys/windows package. I’m guessing there’s some kind of init() function inside that package that tries to do something that the sandbox doesn’t like, and panics when it gets a permission failure [3]. After grepping GitHub hoping someone had already found a solution to this, I discovered that the vst2 project had already implemented a similar solution to mine, but using the lower-level syscall package instead of goxsys/windows. I copied their code nearly verbatim, and it worked out of the box: the DLL was pinned properly in certutil, and Electrolysis worked fine. Thus bringing me out of the certutil gopherhole.
I then relaxed a bit by adding macOS builds to Cirrus, and confirmed that pkcs11mod builds without errors on macOS. (I don’t know if the binaries actually work, but they’re on Cirrus now, you can try them yourself and let me know.)
Finally, after discussion with the other pkcs11mod devs (Aerth and Bernard), we unanimously agreed to relicense pkcs11mod and ncp11 from LGPLv3+ to LGPLv2.1+. This makes it unambiguously legal to use pkcs11mod with GPLv2-licensed applications. The failure to do this initially was an oversight on our end; it was kind of ridiculous that we permitted pkcs11mod to be used with non-freedom software but not GPLv2 software.
We’re not yet at the point where I’d consider pkcs11mod to be well-tested enough to be used in production by people other than its 3 authors, but we are getting a lot closer to that point.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Rabbitholes are a thing in Plan 9, not Go.
[2] Insert Andrew “rasengan” Lee joke here.
[3] The “goxfail” jokes write themselves.
Electrum-NMC v4.0.0b1 fixes CVE-2022-31246
Electrum-NMC v4.0.0b0 and earlier are affected by CVE-2022-31246 / GHSA-4fh4-hx35-r355 (the vulnerability is inherited from upstream Electrum). Electrum-NMC v4.0.0b1 and ncdns for Windows v0.3.1 contain the fix. Tor Browser Nightly was not vulnerable. We would like to thank Unciphered and Immunefi for reporting the vulnerability and coordinating the disclosure with us, and upstream Electrum for implementing the fix.
ncdns v0.3.1 Released
We’ve released ncdns v0.3.1. This Windows-only release includes important improvements to memory safety and UX; we recommend that all Windows users upgrade.
Full changelog of what’s new since v0.3:
- certinject
- Code quality improvements. Patches by Jeremy Rand.
- ncdns
- Code quality improvements. Patches by Jeremy Rand.
- ncprop279
- Fix stderr privacy leak when tlshook is enabled at compile-time. Patch by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- StemNS
- Log errors to stderr. Patch by Jeremy Rand.
- Redact target address from stderr logs. Patch by Jeremy Rand.
- Load configuration from
configfolder. Reported by Patrick Schleizer; patch by Yanmaani. - Support
ControlPort auto. Reported by Adolf-Putin-2022; patch by Jeremy Rand. - Code quality improvements. Patches by Jeremy Rand.
- x509-compressed
- Fix Go 1.18.x compatibility.
- Windows installer
- Switch from BIND’s dnssec-keygen to CoreDNS’s coredns-keygen. Unlike BIND, CoreDNS is memory-safe and has no non-freedom build dependencies. This also means the Visual C++ Runtime is no longer required. Reported by Yana Teras and Aminda Suomalainen; patch by Jeremy Rand.
- Fix compatibility with StemNS’s conf.d feature. Patch by Jeremy Rand.
- Log StemNS stderr to event log. Makes it easier to diagnose Tor Browser configuration bugs. Patch by Jeremy Rand.
- Work around PowerShell v2 bug. Partially fixes Windows 7 compatibility. Reported by Cyphrs; patch by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- Build system
- Bump Electrum-NMC to v4.0.0b1.
- Bump godns to v1.1.49.
- Bump tor-browser-build to v11.5a12.
As usual, you can download it at the Downloads page.
This work was funded by Cyphrs.
Electrum-NMC v4.0.0b1 Released
We’ve released Electrum-NMC v4.0.0b1. This release includes important UX improvements to reduce the risk of accidentally letting names expire, both on the wallet side and a resolution mechanism called semi-expiration that stops resolving names before they are permanently lost. Since semi-expiration affects resolution results, we therefore recommend that all users upgrade, even if you do not own any names yourself, so that you see the same resolution results as everyone else. Here’s what’s new since v4.0.0b0:
- Simplify GUI for editing TLS records. (Patch by Jeremy Rand.)
- Add documentation links to DNS Builder GUI. (Patch by Jeremy Rand.)
- Add server from deafboy. (Patch by Jeremy Rand.)
- Improve UNOList datetime formatting consistency. (Patch by Jeremy Rand, review by Daniel Kraft.)
- Add
expires_timefield toname_show. (Patch by Jeremy Rand, review by Daniel Kraft.) - Implement semi-expiration. (Reported by Cypherpunks, patch by Jeremy Rand, review by Arthur Edelstein, Cyberia Computer Club, Cypherpunks, Cyphrs, Daniel Kraft, Diego Salazar, Forest Johnson, s7r, Somewhat, and Yanmaani.)
- Allow passing raw commitment to
name_new. (Patch by Jeremy Rand.) - Show exact expiration timestamps for expired names. (Patch by Jeremy Rand.)
- Warn user in UNOList when names are expiring soon. (Reported by Diego Salazar, patch by Jeremy Rand.)
- Fix some i18n bugs. (Patch by Jeremy Rand, review by Somewhat, Yanmaani, and Daniel Kraft.)
- Add Namebrow.se explorer. (Patch by Jeremy Rand.)
- Produce packager-friendly tarballs. (Reported by Jeremy Rand, patches by Yanmaani and Jeremy Rand, review by Jeremy Rand and SomberNight.)
- Switch to detached OpenPGP signatures (to follow upstream).
- Various improvements from upstream Electrum.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and NLnet Foundation’s NGI0 Discovery Fund.
ncdns v0.3 Released
We’ve released ncdns v0.3. This release adds Tor Browser configuration support to the Windows installer. If you have Tor Browser installed already, the Windows installer will offer to configure Tor Browser to use Namecoin. This Tor Browser support is aimed at a different audience than the support currently shipped with Tor Browser Nightly; the major features that the ncdns installer brings to the table compared to Tor Browser Nightly are:
- Windows support (Tor Browser Nightly only supports Namecoin on GNU/Linux).
- Choice of Tor Browser Stable, Alpha, or Nightly (Stable and Alpha do not have Namecoin built-in).
- Choice of Electrum-NMC or Namecoin Core (Tor Browser Nightly only supports Electrum-NMC).
.bitdomains fall back to IP address resolution if no onion service exists (Tor Browser Nightly only supports onion services).
Additional features we intend to add to the ncdns installer in the future include:
- TLS support (important for Tor since exit relays are in an excellent position to do MITM attacks, and also important given the censorship attacks we’ve observed from public CA’s such as Comodo and ISRG in the past few years).
- Recursive DNS support (will allow more complex setups such as
NS/DSrecords to be used with Namecoin over Tor).
While we are looking forward to all of the above features making their way into Tor Browser, we want to give power users the option to experiment with these features now. We expect the feedback from that experimentation to make it easier and faster to migrate these features into Tor Browser.
Meanwhile, here are some important caveats you should be aware of in this integration:
- Download size is much larger than Tor Browser Nightly’s Namecoin integration. If you are on a heavily metered data plan, you may be better off with Tor Browser Nightly.
- The build system is less strict on reproducibility than Tor Browser Nightly. In particular, Electrum-NMC is built with the upstream Electrum reproducible build system, and BIND and DNSSEC-Trigger use official upstream binaries. If you are concerned about these components, you may be better off with Tor Browser Nightly.
- You must launch Electrum-NMC or Namecoin Core yourself and keep it running while Tor Browser is running; otherwise
.bitresolution will fail. If you want Electrum-NMC to automatically start when Tor Browser does, you may be better off with Tor Browser Nightly. - Some timing metadata (in particular, the date and time at which you exit Tor Browser) will be written to the Windows event log, which could be a privacy leak. Timing metadata about Tor Browser usage has been used against alleged whistleblowers (e.g. alleged Vault 7 source Joshua Schulte) in the past, so if you have a strong requirement for disk nonpersistence, you may be better off with Tor Browser Nightly.
- The TorButton patch for showing the underlying onion service in the circuit display is not included. If you care about being able to easily view which onion service a
.bitdomain is pointing to, you may be better off with Tor Browser Nightly. - The Firefox patch for adding
bit.onionto the eTLD list is not included. This means that the address bar will default to search mode if you type a.bitor.bit.oniondomain without a URL scheme (leadinghttps://). More importantly, it means that FPI (first-party isolation) will treatbit.onionas an eTLD+1; as a result, all.bit.onionwebsites that you visit will be trivially linkable to each other. To work around this privacy leak, you can use.bitinstead of.bit.onion(but see the conflicting advice below), or you can limit yourself to one.bit.onionfirst-party domain at a time (use the New Identity button when you want to switch to another.bit.oniondomain). If you’re worried that you may not remember to do this, you may be better off with Tor Browser Nightly. - TLS is not mandated for
.bitdomains that point to an IP address. This means that you cannot be confident that.bitdomains are secure origins. Tor Browser will correctly tell you that these origins are not secure; you should heed that warning. To work around this, you can use.bit.onioninstead of.bit(but see the conflicting advice above), or you can use thehttps://URL scheme; either of these will guarantee a secure origin. If you use HTTPS, you will need to verify the certificate chain yourself. If you’re worried that you may accidentally use thehttp://URL scheme with.bitdomains, or if you’re worried that you may accidentally click through a TLS certificate dialog without checking the chain, you may be better off with Tor Browser Nightly. - Our QA team has reported occasional timeout errors when accessing
.bitdomains in Tor Browser. We are investigating the cause. If you require solidly reliable connectivity without timeouts, you may be better off with Tor Browser Nightly. - Our QA team has reported various breakage on Windows 7. We are working on fixes, but this is not a high priority since Windows 7 is EOL. If you require Windows 7 support, you may be better off waiting for us to fix that.
Some of the above caveats are easier to fix than others. We expect some of these to be fixed very soon; others are longer-term efforts. We reiterate that this is intended for power users who want to experiment with Namecoin in Tor Browser, so that their feedback can facilitate future efforts to get these features added to Tor Browser. As such, we very much appreciate feedback so we can improve this functionality.
Full changelog of what’s new since v0.2.2:
- certinject
- Add dexlogconfig support. Patch by Jeremy Rand.
- Add –capi.watch flag (paves the way for better sandboxing). Patch by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- dexlogconfig
- Support custom Windows event log source name. Patch by Jeremy Rand; code review by Hugo Landau.
- Clarify help text. Reported by Jeremy Rand; patch by Hugo Landau.
- easyconfig
- Support durations. Reported by Jeremy Rand; patch by Hugo Landau.
- Encaya
- Add README. Patch by Jeremy Rand.
- Clarify license as GPLv3+. Patch by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- ncdns
- Use new certinject package. Patch by Jeremy Rand.
- Remove Layer-1 TLS support (100% of Namecoin domain owners moved to Layer-2 by now). Patch by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- ncprop279
- Documentation: add sample config file. Patch by redfish; code review by Jeremy Rand.
- Code quality improvements. Patches by Jeremy Rand.
- StemNS
- Use
StreamStatus.CONTROLLER_WAITwhen available. Patches by Jeremy Rand and Lola Dam. - Code quality improvements. Patches by Jeremy Rand
- Use
- tlsrestrictnss
- Fix compatibility with ncprop279. Patch by Jeremy Rand.
- x509-compressed
- Fix GOROOT paths containing a space. Patch by Jeremy Rand.
- Windows installer
- Configure Tor Browser. Patch by Jeremy Rand.
- Remove Layer-1 TLS support (100% of Namecoin domain owners moved to Layer-2 by now). Patch by Jeremy Rand.
- Code quality improvements. Patch by Jeremy Rand.
- Build system
- Add coredns-utils project, by Miek Gieben, Steve Winslow, and Andrew Heberle.
- Add python-windows project. Patches by Yanmaani and Jeremy Rand; code review by Nicolas Vigier.
- Add winsvcwrap project, by Hugo Landau.
- Bump BIND to v9.16.28.
- Bump Electrum-NMC to v4.0.0b0.
- Bump godns to v1.1.48.
- Bump gointernal to v1.8.1.
- Bump gopkcs11 to v1.1.1.
- Bump gotoml to v1.1.0.
- Bump gounits.
- Bump tor-browser-build to v11.5a11.
- Code quality improvements. Patches by Jeremy Rand.
- Improve Cirrus CI integration, as we continue to incubate RBM Cirrus support in preparation to send upstream to Tor. Patches by Jeremy Rand.
You can download it at the Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Go DNS Seeder TCP Support
In a previous post, I covered some Go DNS seeder improvements I made. Now here’s another one: DNS over TCP support.
DNS is an application-layer protocol, and can thus be used with multiple transport protocols. The most common is UDP, but various others such as TCP, TLS, DTLS, QUIC, HTTP, HTTPS, and Unix sockets are a thing. TCP is particularly relevant from a privacy standpoint because TCP works with Tor, while UDP does not. Due to a bug, Lyndsay Roger’s DNS seeder didn’t support TCP, which made it unpleasant to access over Tor. I’ve now fixed that; master branch now supports DNS over TCP, which both improves the experience for Tor users and brings the DNS seeder into compliance with RFC 7766 (which says TCP support is mandatory).
Thanks to Lyndsay for merging the fix! The fix will hopefully be deployed onto Namecoin’s DNS seeds over the next days.
Namecoin Receives 30k EUR in Additional Funding from NLnet Foundation’s Internet Hardening Fund and Netherlands Ministry of Economic Affairs and Climate Policy
We’re happy to announce that Namecoin is receiving 30,000 EUR (roughly 33,306 USD) in additional funding from NLnet Foundation’s Internet Hardening Fund. If you’re unfamiliar with NLnet, you might want to read about NLnet Foundation, or just take a look at the projects they’ve funded over the years (you might see some familiar names). The Internet Hardening Fund is managed by NLnet and funded by the Netherlands Ministry of Economic Affairs and Climate Policy. Unlike our already-active funding from NLnet’s NGI0 Discovery Fund, which is focused on Namecoin Core and Electrum-NMC, this new funding is focused on TLS use cases.
We will use this funding to work on the following:
- Namecoin interoperability with TLS implementations that use AIA. In addition to reducing attack surface of Namecoin TLS on Windows, this lays the groundwork for Namecoin TLS support on Android/Linux, macOS, and iOS.
- Refactoring Namecoin TLS PKCS#11 interoperability to use higher-level API’s that are more straightforward to audit. In addition to improving security and reliability of Namecoin TLS on Firefox (all OS’s) and GNU/Linux (most browsers), this lays the groundwork for things like decentralized TLS with
.oniondomains (in collaboration with the Tor developers), and is likely to benefit 3rd-party developers who wish to create PKCS#11 modules in Go (e.g. for HSM or smart card use cases). - Adding imposed name constraint support to NSS’s TLS trust store (used by Firefox), similar to the existing functionality that exists in CryptoAPI (used by Windows) and GnuTLS (used by GNOME Web). In addition to allowing us to simplify Namecoin’s TLS interoperability code considerably, this is likely to benefit system-wide trust policy projects such as sponsored by Red Hat.
- Auditing TLS clients for name constraint bugs, using Netflix’s BetterTLS test suite. This helps ensure that Namecoin’s security guarantees cannot be bypassed by exploiting bugs in 3rd-party applications.
- Improved integration testing for Namecoin TLS PKCS#11 interoperability. In addition to helping us review PR’s faster, this helps ensure that future changes in third-party applications/libraries don’t cause problems for Namecoin.
- Windows installer for Namecoin TLS in Firefox and/or Tor Browser.
This work will principally be done by developers Aerth and Jeremy Rand (who is the author of this post).
We’d like to thank the awesome people at NLnet Foundation for the continued vote of confidence, as well as the Netherlands government for recognizing that the economy and the climate require a hardened Internet.
We’ll be posting updates regularly as development proceeds. Due to delays in paperwork processing, some work covered by this funding has already taken place; for transparency, we have amended the relevant past news posts to clarify that they were funded by Internet Hardening Fund.
The Namecoin Lab Leak (Part 2): How p11trustmod Vaccinates Against the Unmaintainable Code Omicron Variant
In a previous post, I covered how splitting off p11mod from ncp11 improved code readability and auditability by using a higher-level API. Jacob Hoffman-Andrews’s p11 API is certainly more high-level than Miek Gieben’s pkcs11 API, but I wasn’t satisfied. Consider that most PKCS#11 usage in the wild involves encryption or signature algorithms that operate on public or private keys. In contrast, PKCS#11 modules like Mozilla CKBI or Namecoin ncp11 are strictly using the PKCS#11 API as a read-only database API, and only for X.509 certificates [1] – public and private keys are nowhere to be found. Given these limits on what usage Namecoin will need, we can construct a much higher-level (and much simpler) API than even the p11 API.
For reference, here are the function prototypes of p11:
FindObjects finds any objects in the token matching the template.
func (s Session) FindObjects(template []*pkcs11.Attribute) ([]Object, error)
Attribute gets exactly one attribute from a PKCS#11 object, returning an error if the attribute is not found, or if multiple attributes are returned. On success, it will return the value of that attribute as a slice of bytes. For attributes not present (i.e. CKR_ATTRIBUTE_TYPE_INVALID), Attribute returns a nil slice and nil error.
func (o Object) Attribute(attributeType uint) ([]byte, error)
Note that the p11 API is intentionally very generic; every object is an arbitrary mapping of attribute types (generic integers) to attribute values (generic binary data), and searching for objects requires constructing a template that looks about as generic as the object itself. This necessarily involves a lot of boilerplate. Here’s the higher-level API, which I call p11trustmod:
type CertificateData struct {
Label string
Certificate *x509.Certificate
BuiltinPolicy bool
TrustServerAuth uint
TrustClientAuth uint
TrustCodeSigning uint
TrustEmailProtection uint
}
func (b Backend) QueryCertificate(cert *x509.Certificate) ([]*CertificateData, error)
func (b Backend) QuerySubject(subject *pkix.Name) ([]*CertificateData, error)
func (b Backend) QueryIssuerSerial(issuer *pkix.Name, serial *big.Int) ([]*CertificateData, error)
func (b Backend) QueryAll() ([]*CertificateData, error)
As you can see, this API matches the behavior of libraries like NSS, which query for certificates by only a few search keys: the certificate itself, the subject, the issuer and serial, and asking for all the certificates at once. In ncp11, we extract the .bit domain from the subject or the issuer. (If the entire certificate is searched for, the subject and issuer are both within the x509.Certificate struct. The QueryAll search method can’t be used to look up .bit certificates, but it can be used to find the Namecoin root CA, which is sufficient.) Here’s some of what p11trustmod is doing behind the scenes:
- The
FindObjectsfunction checks which attributes are in the search template, and callsQueryCertificate,QuerySubject, orQueryIssuerSerialas appropriate. Thus, ncp11 won’t need to deal with processing attributes from the search template. - The
FindObjectsfunction always callsQueryAlland appends those results. This allows ncp11 to return certain objects such as the Namecoin root CA even if those objects aren’t being referenced by name [2]. - The
FindObjectsfunction filters all the query results to make sure it actually matches the search template. This allows ncp11 to simply return whatever Namecoin says matches the.bitdomain, without worrying about the search template. - The
Attributefunction automatically fills in sane values for boilerplate attributes such asCKA_TOKEN(always true),CKA_PRIVATE(always false),CKA_MODIFIABLE(always false), andCKA_CERTIFICATE_TYPE(alwaysCKC_X_509). - The
Attributefunction automatically extracts the subject, issuer, serial number, and hash from the certificate, so ncp11 can just return the certificate. - The backend (e.g. ncp11) can choose whether to supply trust bits, and if so, p11trustmod synthesizes trust bits objects for the Namecoin root CA from the
BuiltinPolicy,TrustServerAuth,TrustClientAuth,TrustCodeSigning, andTrustEmailProtectionfields. There are some tradeoffs here:- The
BuiltinPolicytrust bit causes Certificate Transparency errors in Chromium, but enforces better security (e.g. blacklisting obsolete crypto and enforcing key rotations) in Firefox. - Omitting all trust bits from ncp11 and putting the Namecoin root CA in the standard trust store instead allows ncp11 to run with improved sandboxing. However, depending on which trust store implementation is used, this might preclude the security benefits of the
BuiltinPolicytrust bit. p11-kit, which is used in Fedora and Arch, supports theBuiltinPolicytrust bit. Softoken, which is used in Debian, Windows, and macOS, does not. Since Tor Browser does not have a mutable trust store (for fingerprinting reasons), this sandboxing is probably not possible in Tor Browser.
- The
So, all things considered, p11trustmod eliminates quite a lot of boilerplate code that ncp11 would have otherwise needed to mix in with the Namecoin-specific ncp11 code. By proactively implementing this additional layer of abstraction between p11mod and ncp11, we reduce the risk of a second “Omicron lab leak” of insufficiently auditable code. p11trustmod is nearly finished with implementation but still needs testing; once testing is complete, we can move on to the Namecoin-specific code in ncp11, which I expect to be quite simple since the complex things have been split out into p11mod/p11trustmod.
In other p11mod news, p11mod now supports generating key pairs. Thanks to OpenDNSSEC for facilitating this.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Technically this isn’t quite true. In addition to X.509 certificates, there are a couple of other object classes that are used for setting the trust policy bits on the Namecoin root CA. Those classes are only used by optional features, though.
[2] There are a few ways this might happen. NSS sometimes retrieves a list of all known CA’s, e.g. to display in the certificate GUI. NSS also retrieves trust bits objects by searching for an object class or a certificate hash instead of a PKIX name or full certificate.
Preventing Expiration Mishaps with Semi-Expiration
Forgetting to renew a Namecoin name on time is rather catastrophic: it means that anyone else can re-register it and then hold the name hostage. In practice today, it is likely that such re-registrations will be done by Good Samaritan volunteers who are happy to donate the name back to you. However, as per the cypherpunk philosophy of “don’t trust, verify”, it’s not desirable to rely on those Good Samaritans, since they constitute a trusted third party. How can we improve this situation?
Let’s start by observing two fundamental properties of expired names:
- Expired names resolve as
NXDOMAIN. - Expired names can be registered by anyone.
Astute readers will have noticed that these are, in principle, distinct properties. Where are they enforced?
- Policy layer: Expired names resolve as
NXDOMAIN. - Consensus layer: Expired names can be registered by anyone.
And what are their respective impacts?
- Temporary DoS: Expired names resolve as
NXDOMAIN. - Permanent hijacking: Expired names can be registered by anyone.
So what happens if we make the following change? We introduce a new state for names: Semi-Expired. Semi-expired names obey Property 1 but not Property 2. Names semi-expire when they come within 4032 blocks (4 weeks) of expiration. Does the situation improve?
Let’s imagine that Alice forgets to renew her name before it semi-expires. As a result, her name becomes unresolvable. This causes her website to go down. Some of Alice’s users notice this, and complain to her via email, social media, or some other out-of-band medium. Alice then renews her name, which reverts the semi-expired state. And this out-of-band process gives Alice 4 weeks to fix things before she is at risk of having her name stolen. That certainly seems like an improvement. And this is solely a policy change, not a consensus change, making it cheap to implement and deploy.
I’ve now implemented this in Electrum-NMC. The RPC interface adds fields for the “semi-expired” state, and the Manage Names GUI counts down to semi-expiration rather than expiration.
Some additional observations:
- Semi-expiration will only help you as a name owner if you actually actively use your name. It won’t help you if you hold an unused name for squatting purposes. While I don’t think any of the Namecoin developers are opposed to additional anti-expiry mechanisms that work for squatters, I think it’s arguably a good thing that semi-expiration incentivizes active use of names.
- Because semi-expiration decreases the effective duration of resolvability for names (this is a necessary consequence of implementing semi-expiration on the policy layer), it means that name owners will renew somewhat more often with respect to time. Theoretically, this means that name owners will pay higher fees with respect to time, and that the blockchain will grow faster with respect to time. In practice, the difference is likely to be negligible, and if it is detectable at all, it will be in the form of increased block reward (which indirectly improves blockchain hashrate) and decreased incentive to squat on names (which indirectly improves usefulness of the system).
Semi-expiration should be released in Electrum-NMC v4.0.0b1. Namecoin Core will hopefully follow soon after.
Go DNS Seeder Improvements
Any P2P network has to deal with initial peer discovery. Bitcoin and Namecoin mostly solve this via DNS seeds: special domain names that return a large number of IP addresses corresponding to Bitcoin/Namecoin nodes. If you’ve used Namecoin Core, you’ve probably encountered the dreaded “no peers” symptom. This is because, unfortunately, the primary DNS seeder implementation used by Bitcoin (by Pieter Wuille) is neither Freedom Software (it’s under an All Rights Reserved license, so Namecoin cannot legally use it) nor memory-safe (it’s in C++). To help improve Namecoin peer discovery (and maybe Bitcoin too), I’ve submitted the following improvements to Lyndsay Roger’s Go-based DNS seeder (which is both Freedom Software and memory-safe):
- Run without root privileges via
setcap.- This is a good alternative to
iptables, which was already supported.
- This is a good alternative to
- Use multiple initial IP’s.
- Helpful if there are no operational DNS seeds when you start a crawl.
- Receive multiple peers per crawl.
- Fixes a Bitcoin protocol implementation bug that caused crawls to stall.
- Support Bitcoin Core’s
seeds.txtAPI.- Allows us to export the seed list into Namecoin Core, so that even if the DNS seed is offline, Namecoin Core can still find peers.
- Route TCP traffic over SOCKS5 proxy.
- Prerequisite for crawling onion-service peers.
Lyndsay has merged all of these except for the SOCKS5 patch, which is waiting on some review from the Tor developers. Huge thanks to Lyndsay for reviewing and merging the patches – I’m hoping that these patches will result in much better peer discovery for Namecoin Core (which has always been a pain point for us).
p11mod Now Supports Signatures
In a previous post, I covered p11mod and how it improves the auditability of Namecoin’s TLS interoperability with NSS and GnuTLS. Recently, I’ve expanded the subset of the PKCS#11 implementation that p11mod covers; p11mod can now:
- Import certificates, public keys, and private keys.
- Delete certificates, public keys, and private keys.
- Sign messages with private keys.
- Verify signatures with public keys.
None of these operations are required by Namecoin, but they do make p11mod useful for a wider variety of use cases, which helps attract more users and developers. This new functionality was made possible by integration tests from OpenDNSSEC. Thanks to the OpenDNSSEC developers for that!
I also fixed a PKCS#11 specification compliance bug in p11mod (stupid off-by-one error in object handle validation), which was surfaced by a GnuTLS upgrade that enforces greater strictness. Kudos to the GnuTLS developers for being strict and helping me fix a bug!
All of these improvements are now tested daily on Cirrus via p11proxy.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Unix domain sockets in Electrum
I recently sent in a patch to Electrum which adds support for Unix domain sockets to the RPC interface. After review by ghost43 and Jeremy Rand, who is also a Namecoin developer, this patch has been merged. As a result, Electrum now has support for Unix domain sockets in the RPC daemon. (Unix domain sockets are not yet supported for other occasionally local network operations, such as for connecting to a SOCKS proxy.)
Unix domain sockets are a type of sockets that run entirely inside of the system (the “Unix domain”). Instead of binding to a network port, they bind to a file. The access to this file can then be controlled by the ordinary mechanisms, like file system permissions or ACLs. This makes them very well-suited to replace connections to the loopback interface, because unlike such connections, they are not visible to the entire system. Moreover, by completely disabling the ability of an application to make network requests and limiting its connections to a few select Unix domain sockets, a very high degree of control can be maintained.
It is envisioned that this will be useful for ncdns, our DNS resolver, because it will allow Electrum-NMC to provide an RPC interface to ncdns without having to bind to a network port. This reduces attack surface, making the application more secure. The functionality can also be used by other Electrum users for other use-cases, and some are even suggesting to make it the default on Unix platforms.
I would like to thank Jeremy Rand and ghost43 for reviewing this pull request, pointing out several important details I missed and giving me helpful feedback on future-proofing and codebase standards.
This change does not in any way impact how Electrum makes connections to other hosts over the network. This change is not expected to break any existing behaviors.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
Electrum-NMC v4.0.0b0 Released
We’ve released Electrum-NMC v4.0.0b0. This release includes numerous bugfixes and improvements, both Namecoin-related and from upstream Electrum.
The following Namecoin developers contributed to this release:
- Jeremy Rand
- Daniel Kraft
- Yanmaani
- Somewhat
As usual, you can download it at the Beta Downloads page.
Namecoin-Qt: Export, Name Count, and Buy Names Feedback
I implemented a few more Namecoin-Qt features. The Manage Names tab now includes both an Export button and a name counter:
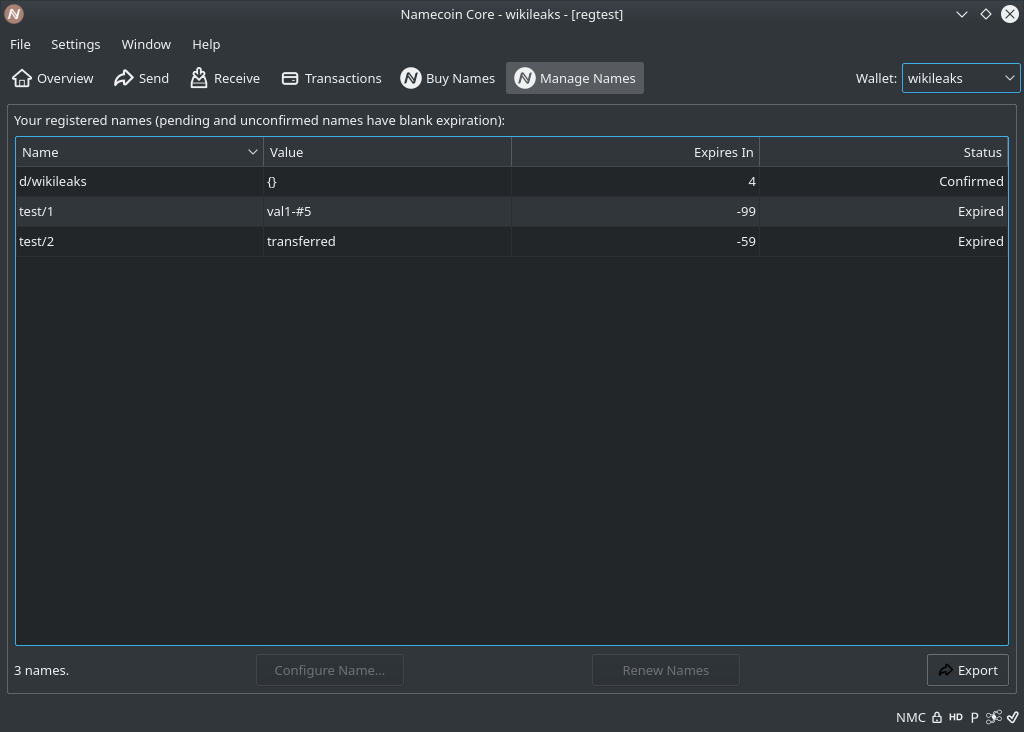
The Buy Names tab also now gives real-time feedback on which names are available:
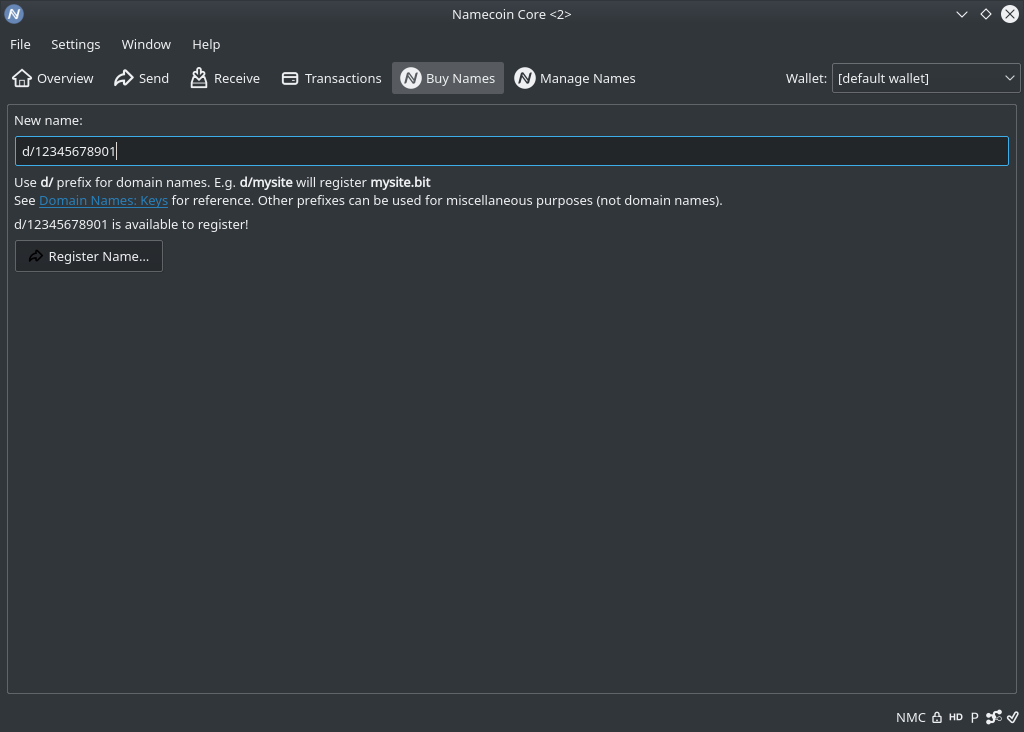
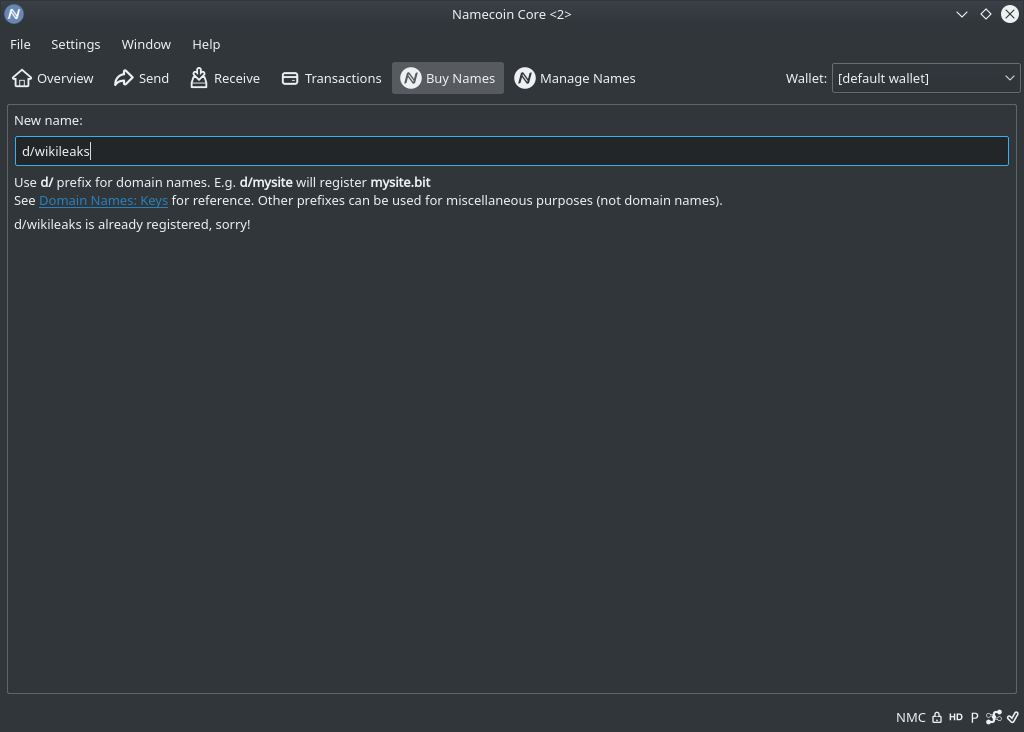
This is a good example of a UX benefit that only full-node users get: because name lookups in Namecoin Core don’t generate network traffic, they are fast enough that they can be performed every time a character is typed in the name field, without making the user click anything.
I’m not leaving RPC users behind either: the name_show RPC method now yields more specific error messages when a name doesn’t exist, depending on whether it is expired or never existed. This should make things more convenient for human RPC users. The error codes haven’t changed, so this shouldn’t break any software.
These improvements are expected to be included in Namecoin Core 23.0.
This work was funded by Cyphrs.
Upstream btcd Has Merged Last Outstanding Namecoin Patch
Good news: upstream btcd has merged the last outstanding patch that Namecoin was applying for our usage of btcd’s JSON-RPC client in ncdns. This means that Namecoin’s fork of btcd will be discontinued, and as of the next btcd release (v0.22.1), ncdns will switch to using an unpatched upstream btcd. Using unpatched upstream btcd will decrease our maintenance effort and improve code quality.
Huge thanks to Torkel Rogstad, Anirudha Bose, and John Vernaleo from upstream btcd for code review.
ncdns v0.2.2 Released
We’ve released ncdns v0.2.2. This release contains multiple bugfixes, in particular a patch to generate_nmc_cert that works around a CryptoAPI connectivity bug. We strongly recommend that all users upgrade. All domain owners who have TLS enabled will need to re-generate their TLS certificates and TLS records after upgrading.
Full changelog of what’s new since v0.2:
- ncdns
- Remove tlsrestrict_chromium_tool binary. (certinject should be used instead now.)
- Code quality improvements.
- generate_nmc_cert
- Disable AIA over HTTPS. (No major TLS clients support it, and it was tickling a CryptoAPI connectivity bug. Thanks to mjgill89.)
- Rebase against Go 1.17.
- Code quality improvements.
- ncp11
- Temporarily suspend providing macOS binaries of ncp11. (macOS support for ncp11 will return after the ongoing p11mod refactor has completed.)
- Windows installer
- Support chain-installing and configuring Electrum-NMC.
- Redesign Components dialogs.
- Fix installation error on certain non-English locales, e.g. Swedish. (Thanks to Jonas Ostman.)
- Warn users of Windows 7 and earlier. (ncdns hasn’t supported these EOL Windows versions for a while; users who are okay with security degradation will be able to bypass the warning and install anyway.)
- Relicense under GPLv3+.
- Remove non-freedom build dependency.
- Code quality improvements.
- Build system:
- Downgrade to BIND 9.16 branch for Windows. (Upstream BIND has dropped Windows support in 9.17 branch.)
- Relicense ncdns-repro under tor-browser-build license. (Thanks to Nicolas Vigier and Georg Koppen.)
- Code quality improvements.
- Bump dependencies:
- tor-browser-build
- gobtcd
- godns
- goisatty
- gopretty
- gotoml
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin-Qt Buy Names Tab
Now that the Manage Names tab in Namecoin-Qt (which lets you update existing names in your wallet) is implemented, it’s time to move onto the Buy Names tab. Like the Name Update GUI, this forward-port was pretty uneventful, so rather than boring you with details, here’s a screenshot:
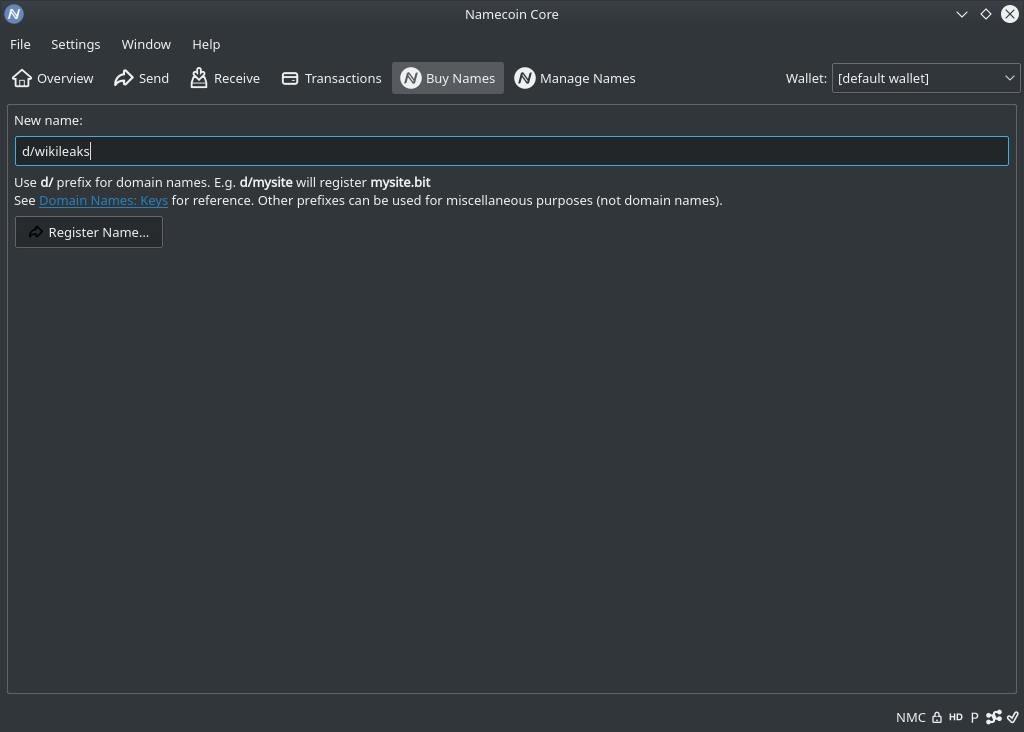
As you can see, I kept things minimalist to enable faster review. For example, there is not yet any UI element to tell you if a name already is registered (you’ll find out in such cases after clicking the button). In addition, this UI only triggers the name_firstupdate RPC method, not name_new (which you’ll need to do yourself via the console prior to using the Buy Names tab). This is because Yanmaani is already working on RPC support for combining name_new and name_firstupdate; once his work on that is merged, this GUI should be convertible to use his work with a one-liner patch.
The Buy Names tab is expected to be included in Namecoin Core 23.0.
This work was funded by Cyphrs.
Namecoin-Qt Decoration Improvements
I’ve been improving the UX of decorations applied to transactions in Namecoin-Qt. For comparison, here’s what it looked like before the improvements:
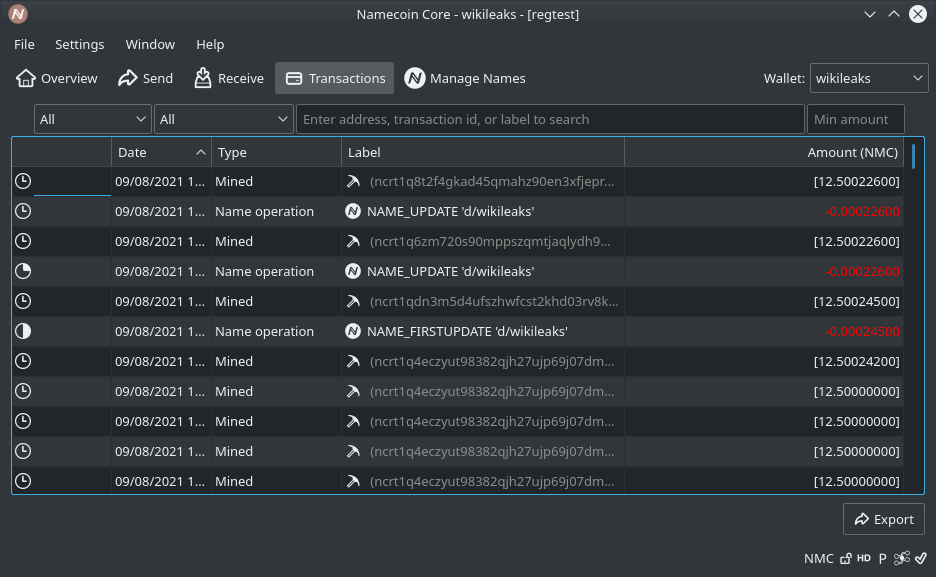
And after:
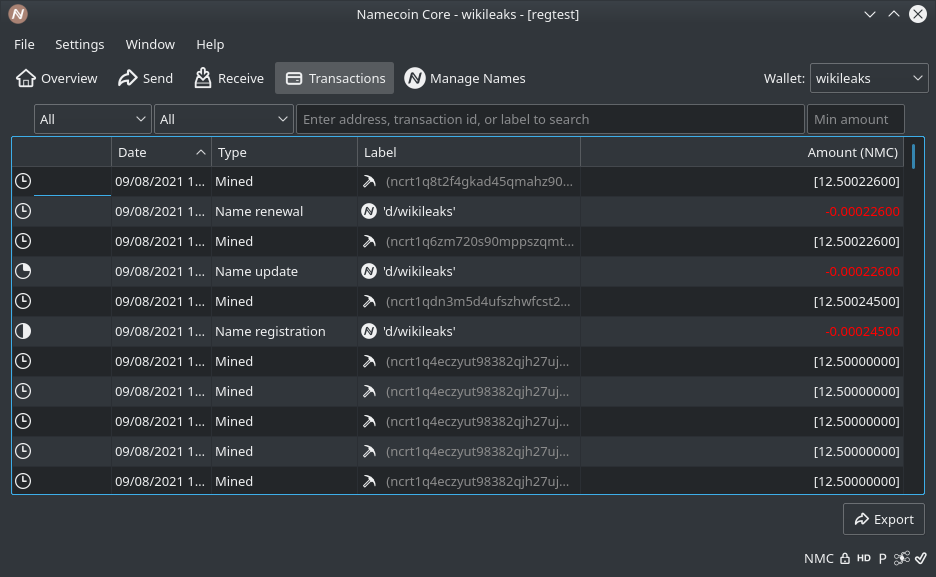
As you can see, jargon such as NAME_FIRSTUPDATE has been replaced with more user-friendly terminology such as Name registration and has been moved to the Type column (replacing the redundant Name operation text). Name updates that do not change the value are now marked as Name renewal, which more precisely conveys the nature of such transactions (this required some plumbing, as previously the transaction decoration code did not have access to the previous value of a name transaction). Additionally (not pictured above), name transfers are now decorated appropriately.
These improvements are expected to be included in Namecoin Core 23.0 (22.0 has already branched from master and should be released soon).
The Namecoin Lab Leak: How p11mod Vaccinates Against the Unmaintainable Code Pandemic
Every now and then, some mad scientists will get foreign government funding, routed through an intermediary NGO, to create something in their lab, with the expectation that their creation will stay in the lab – and then it escapes, potentially wreaking havoc. Oops. This is what happened to Namecoin in the months surrounding 35C3.
As those of you who watch our C3 talks will be aware, Aerth and I did some mad science in the leadup to 35C3, in the form of ncp11. ncp11 is a PKCS#11 module that enables Namecoin TLS certificate verification in software that uses NSS or GnuTLS (which means Firefox, the GNU/Linux release of Chromium, GNOME Web, GNU Wget, and various other software). The ncp11 codebase that we released at our 35C3 workshop was very much a proof of concept, as the workshop notes make clear:
Welcome to the 35C3 Namecoin TLS Workshop, home of the code that first worked a few days ago.
We figured at the time that this was not really a big deal, since the code did work just fine, and we could always refactor and clean it up later. And it’s not like the hackers attending 35C3 have a problem with experimental code. Alas, you already know what happened: after 35C3, we entered major discussions with the Tor Browser developers, and all of our capacity for cleaning up the ncp11 code got gobbled up. Thus, the ncp11 codebase ended up in production use (though hopefully not in large numbers, since it was never added to the ncdns Windows installer), escaping the lab.
So, what was wrong with the ncp11 codebase that made it so in need of a refactor? I think the best way to explain it is to examine the API it’s forced to provide. ncp11 provides an API that is equivalent to the API that Miek Gieben’s pkcs11 package provides. Here’s an example consumer of this API, courtesy of Miek’s documentation:
p := pkcs11.New("/usr/lib/softhsm/libsofthsm.so")
err := p.Initialize()
if err != nil {
panic(err)
}
defer p.Destroy()
defer p.Finalize()
slots, err := p.GetSlotList(true)
if err != nil {
panic(err)
}
session, err := p.OpenSession(slots[0], pkcs11.CKF_SERIAL_SESSION|pkcs11.CKF_RW_SESSION)
if err != nil {
panic(err)
}
defer p.CloseSession(session)
err = p.Login(session, pkcs11.CKU_USER, "1234")
if err != nil {
panic(err)
}
defer p.Logout(session)
p.DigestInit(session, []*pkcs11.Mechanism{pkcs11.NewMechanism(pkcs11.CKM_SHA_1, nil)})
hash, err := p.Digest(session, []byte("this is a string"))
if err != nil {
panic(err)
}
for _, d := range hash {
fmt.Printf("%x", d)
}
fmt.Println()
As Miek’s doc prefaces this example:
yes, pkcs#11 is verbose
This example doesn’t really do us justice though, since Namecoin uses the FindObjects API, which the above example doesn’t include. Here are the function prototypes of that API:
FindObjectsInit initializes a search for token and session objects that match a template.
func (c *Ctx) FindObjectsInit(sh SessionHandle, temp []*Attribute) error
FindObjects continues a search for token and session objects that match a template, obtaining additional object handles. Calling the function repeatedly may yield additional results until an empty slice is returned. The returned boolean value is deprecated and should be ignored.
func (c *Ctx) FindObjects(sh SessionHandle, max int) ([]ObjectHandle, bool, error)
FindObjectsFinal finishes a search for token and session objects.
func (c *Ctx) FindObjectsFinal(sh SessionHandle) error
GetAttributeValue obtains the value of one or more object attributes.
func (c *Ctx) GetAttributeValue(sh SessionHandle, o ObjectHandle, a []*Attribute) ([]*Attribute, error)
Anytime you have to provide an API this low-level, the code is going to be hard to follow. So, how to fix it? In fact, there is actually a higher-level API available: the p11 API by Jacob Hoffman-Andrews, which also lives in Miek’s repo (and acts as a high-level wrapper for Miek’s pkcs11 API). Here’s an example consumer of Jacob’s API:
module, err := p11.OpenModule("/path/to/module.so")
if err != nil {
return err
}
slots, err := module.Slots()
if err != nil {
return err
}
// ... find the appropriate slot, then ...
session, err := slots[0].OpenSession()
if err != nil {
return err
}
privateKeyObject, err := session.FindObject(...)
if err != nil {
return err
}
privateKey := p11.PrivateKey(privateKeyObject)
signature, err := privateKey.Sign(..., []byte{"hello"})
if err != nil {
return err
}
Doesn’t look as bad. And here are the function prototypes that correspond to the above ones:
FindObjects finds any objects in the token matching the template.
func (s Session) FindObjects(template []*pkcs11.Attribute) ([]Object, error)
Attribute gets exactly one attribute from a PKCS#11 object, returning an error if the attribute is not found, or if multiple attributes are returned. On success, it will return the value of that attribute as a slice of bytes. For attributes not present (i.e. CKR_ATTRIBUTE_TYPE_INVALID), Attribute returns a nil slice and nil error.
func (o Object) Attribute(attributeType uint) ([]byte, error)
That certainly looks simpler.
So, in the same way that we created a helper library for ncp11 to use, pkcs11mod, to interface between the C ABI for PKCS#11 and the Go API for Miek’s pkcs11 package, we can create a helper library (which we call p11mod) to interface between the Go API for Miek’s pkcs11 package and the Go API for Jacob’s p11 package. We can then make ncp11 implement Jacob’s p11 API, which allows us to make the ncp11 code substantially more readable, maintainable, and auditable.
I’ve now done exactly that. p11mod has been merged as a subpackage of the pkcs11mod repository, which enables us to move forward with refactoring the Namecoin-specific parts of ncp11 (more on that in a future post).
In addition, I’ve improved testability of pkcs11mod/p11mod. The repo now includes two example modules, pkcs11proxy and p11proxy. These simply act as a passthrough shim between pkcs11mod and Miek’s pkcs11 package, and p11mod and Jacob’s p11 package, respectively. Thus, you can load Mozilla’s CKBI (built-in certificates) module into NSS via the pkcs11proxy and p11proxy shims, and confirm that the resulting behavior matches loading CKBI into NSS without the shims (e.g. you can do a TLS handshake and make sure that certificate acceptance behavior matches). So, there are now nightly builds of both pkcs11proxy and p11proxy courtesy of Cirrus, as well as nightly integration tests that make sure both pkcs11proxy and p11proxy work as expected in Firefox, Chromium, GNU Wget, tstclnt, and gnutls-client, among other applications. This is a major improvement over the previous situation, where testing pkcs11mod required Namecoin-specific tests with ncp11.
Coming soon: refactoring the Namecoin-specific parts of ncp11.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
tstclnt: openssl s_client / gnutls-cli equivalent for NSS
When debugging TLS handshakes, it’s incredibly helpful to have a CLI tool that acts as a simple TLS client. For OpenSSL (the TLS library used by Python, curl, and various other GNU/Linux things), the relevant tool is openssl s_client. For GnuTLS (the TLS library used by GNOME Web, wget, and various other GNU/Linux things), it’s gnutls-cli. But did you know that there’s an analogous tool for NSS (the TLS library used by Firefox and the GNU/Linux version of Chromium)? If you didn’t know this, you can be easily forgiven – the Mozilla NSS documentation doesn’t mention that it exists, and there are almost no web search results for it! Yet it’s there.
The tool is called tstclnt (“testclient” with the vowels removed). On Debian Buster, you can find it in the libnss3-tools package. On Fedora 34, it’s a tad more complicated: tstclnt is in the nss-tools package, but it doesn’t install to a directory that’s on the default PATH. Fedora instead installs tstclnt to the /usr/lib64/nss/unsupported-tools/ directory (path is accurate for ppc64le; other architectures may have slightly different paths).
Once you’ve installed tstclnt, you can run it like this:
tstclnt -b -D -h www.namecoin.org
The -h argument indicates which TLS server to connect to. The -b flag instructs tstclnt to use the default CKBI (built-in certificate database) PKCS#11 module. The -D flag disables the Softoken (SQLite-based certificate database) PKCS#11 module.
If all goes well, tstclnt will do a successful TLS handshake with www.namecoin.org.
For more fun, you may also wish to try the following:
- Replace
-bwith-R /usr/lib64/pkcs11/p11-kit-trust.soto use a non-default PKCS#11 module instead of CKBI. - Replace
-Dwith-d sql:/etc/pki/nssdbto use a SQLite certificate database with Softoken. (You can use thedbm:prefix instead ofsql:if you want to use Softoken’s legacy BerkeleyDB database format instead of the modern SQLite.) - Add
-Cto dump the certificate chain. (You can use-C -Cor-C -C -Cfor more verbosity.) - Add
-oto override certificate validation errors. - Add
-p 443to connect to a non-default TLS port.
And of course you can access a full list of options via tstclnt --help.
tstclnt is an excellent tool for TLS hackers; it’s too bad Mozilla doesn’t document its existence.
ncdns v0.2 Released
We’ve released ncdns v0.2. This release adds layer-2 TLS via Encaya, and overhauls the build system.
Full changelog of what’s new since v0.1.2:
- ncdns
- Code quality improvements.
- generate_nmc_cert
- Rebase against Go 1.14.
- Set ExtKeyUsage on CA.
- Use compressed ECDSA public keys. Thanks to Filippo Valsorda.
- Support AIA.
- Add
chain.pemandcaChain.pemoutput files. - Support certs with multiple hostnames.
- Code quality improvements.
- Windows installer
- Enable TLS by default in silent installs.
- Add Encaya (layer-2 positive TLS overrides for CryptoAPI).
- Fix NSIS logging in silent mode.
- Code quality improvements.
- Linux
setuid/setgidno longer require cgo. Thanks to Hugo Landau.
- Build system:
- Windows installer is now built in RBM.
- GNU/Linux and macOS binaries are built again.
- RBM builds now run on Cirrus CI.
- Add projects:
- certinject.
- encaya.
- generate_nmc_cert.
- qlib.
- Bump dependencies:
- tor-browser-build.
- BIND.
- goansicolor.
- gobtcd.
- gobtcutil.
- goconfigurable.
- godexlogconfig.
- godns.
- gogroupcache.
- goisatty.
- gomadns.
- gopflag.
- gopretty.
- goservice.
- gosvcutils
- gosystemd.
- gotext.
- gotlsrestrictnss.
- gounits.
- Switch to
tar.xzoutput to match upstream Tor. - Generate rbm.conf from upstream Tor at build time.
- Auto-create GitHub PR for dependency bumps.
- Code quality improvements.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
rbm on Cirrus CI
rbm (Reproducible Build Manager) is a quite nice system for reproducible builds. rbm was originally created by Nicolas Vigier from the Tor Browser Team as a replacement for Gitian (which was previously used by Tor Browser and is still used by Bitcoin Core). rbm has since been adopted by other projects like Ricochet and Namecoin (in particular, we use rbm for building ncdns). Recently, I’ve been doing some mad science experiments with running rbm on Cirrus CI infrastructure.
Why use Cirrus CI for reproducible builds?
Being able to run rbm as part of a CI workflow brings several benefits:
- We can test PR’s to make sure they build properly, without needing a developer machine to do the build.
- We can upload nightly build binaries, and binaries built from PR’s, again without needing a developer machine.
- We can use the CI service as a co-signer for reproducible release builds.
The third may merit some further explanation, since you may be wondering why anyone should trust Cirrus CI to sign our builds. The underlying principle of reproducible builds is not that any particular co-signer is supposed to be trustworthy. Rather, the co-signers should be diverse, such that an event that compromises a subset of the co-signers is not likely to compromise the remainder. For example, it is desirable for different co-signers to run different OS distributions, not because any of those distributions are trustworthy, but simply because a compromise of Debian signing keys is unlikely to also result in a compromise of Fedora signing keys (or vice versa). This explains why it’s desirable to use Cirrus CI as a co-signer: the circumstances that would cause Cirrus CI infrastructure to be compromised are quite different from the circumstances that would cause the Namecoin developers’ build machines to be compromised; thus using Cirrus CI as a co-signer improves diversity, which by extension improves security.
Why did I pick Cirrus CI instead of other CI services like GitLab, GitHub Actions, or Microsoft Azure Pipelines? Cirrus made sense because Bitcoin Core already uses it, meaning that Namecoin already uses it too. However, it should be noted that there’s no good reason to stick to only one CI service here; more CI services means more diversity, and thus more security. I intend to try porting this work to other CI service in the future.
Running rbm at all
Cirrus typically runs all GNU/Linux builds inside a Docker container. Meanwhile, rbm uses runc to start containers of its own. As Hitler wants us to know, running a container inside a container is an easy way to lose World War II. However, Cirrus does have a minimally documented build mode called docker_builder. This is described in the documentation as a mechanism to build custom Docker containers so that you can then use those containers to run your actual build in the normal way inside Docker. However, the docker_builder mode is actually just a standard Ubuntu VM, and it works totally fine to run an rbm build in this environment without ever touching Docker [1].
Time limits: Caching
Cirrus has a default time limit per task of 1 hour. This can be increased to a maximum of 2 hours via YML configuration, but 2 hours is still too short a duration to build Tor Browser (or ncdns). However, there are some hacks we can use here. First off, we can instruct Cirrus to cache the out directory that rbm creates during a build. This means that once we build a specific project (e.g. GCC or the Go compiler), it won’t have to be rebuilt unless its version or dependencies are bumped. We can also cache the git_clones directory, which means that only new Git commits must be downloaded, rather than cloning entire repositories on each build.
Time limits: Splitting by Project
Once we’re caching the outputs of projects, we can instruct Cirrus to split the build into several tasks, each of which builds only a subset of projects. For example, Namecoin currently builds GCC, the Go compiler, and a few Go libraries in one task, while we build ncdns in another task. I wrote a Bash script that automates construction of a Cirrus YML config that contains many tasks that all run rbm and are executed sequentially. (Maybe I could scrap the Bash script in favor of smarter YML usage? Looking into that is for another day.)
Time limits: The Clang Problem
A few of Tor Browser’s rbm projects take longer than 2 hours to build. The good news is that none of them are necessary to build any Namecoin projects for GNU/Linux or Windows targets. The bad news is that one of them (Clang) is needed to build Namecoin for macOS. And of course, since Namecoin is a good neighbor, I want to get this upstreamed to Tor, so Tor’s problems are my problems. I considered a few options here:
- Try to refactor the affected projects so that they can be split into smaller projects that each take less build time. I rejected this approach because (1) it would probably be fairly invasive to upstream, and (2) it would probably slow down builds that aren’t running on Cirrus (there is a nontrivial per-project overhead in rbm).
- Checkpoint the build containers with CRIU (“Checkpoint/Restore In Userspace”; basically the container equivalent of the “hibernate” feature that operating systems have on bare-metal), so we can split their execution into multiple Cirrus tasks. This seemed like a good option since runc has built-in support for CRIU, until Nicolas from Tor gave me a heads up that rbm was soon going to replace runc with something built in-house, which does not support CRIU.
- Send the SIGINT signal to a build container to interrupt its build script, then cache the container’s filesystem, and then run the build script again in a subsequent Cirrus task. This is conceptually similar to CRIU, but it abuses the fact that most build systems (e.g. GNU Make) are smart enough to not repeat already-completed steps if you run them a 2nd time. In contrast, CRIU is designed to handle the more general case where a program inside a container isn’t that smart – we do not need that level of robustness here, and sending SIGINT to everything inside a build container is a lot simpler than using CRIU with a container system that isn’t designed to support it.
Option 3 is what I decided to go with. I initially wasn’t sure how to send SIGINT to a container, but some brief experiments with pgrep on the host OS showed that all processes inside the rbm container were visible from the host OS, including their command-line metadata. Since rbm always launches a build inside the container by running a script called build, that means we can identify the host-side process ID of the build script inside the container by running pgrep -f '\./build'. Furthermore, I found a Stack Exchange answer by Russell Davis on obtaining all of the descendent process ID’s (e.g. the make and gcc processes); this also works from the host OS.
From this, I wrote a quick Bash script (which runs on the host OS) that first sets a flag (via touching a file) indicating that the build was interrupted, and proceeds to send SIGINT to the build script and all of its descendent processes inside the rbm container. Next, I patched rbm so that when the build script exits, rbm checks if that flag is set. If it was set, then rbm saves a copy of the container’s filesystem before deleting the container. The next time rbm tries to build that particular project hash, it checks whether it had previously saved a filesystem for that project hash; if so, it restores the filesystem instead of creating a clean container image.
Finally, I had to slightly patch the build script for the Clang toolchain projects. This was necessary because although GNU Make is smart enough to not get confused by being run twice in a row, Tor’s Bash script for building Clang is not quite that smart. I didn’t need to make the Bash build script tolerate being restarted at arbitrary points; the only place where it was going to restart from was the make command. So, I simply made the build script set a flag (again, by touching a file) right before it ran the make command; this gets saved along with the rest of the container’s filesystem if the build gets interrupted with SIGINT. If the build script finds that this flag is set at the beginning of the script, it skips ahead in the script straight to the make command. Sure, it’s a little hacky, but it’s dead simple and generally noninvasive.
Results
Namecoin’s rbm build system now runs inside Cirrus CI, meaning that we can use Cirrus as a reproducible build co-signer. In addition, I set up a Cirrus cron task that checks daily for dependencies whose versions we can bump, and automatically submits a GitHub PR when it finds some. Since Cirrus builds our GitHub PR’s, this allows us to automatically test whether the bumped dependencies still build without errors, saving us even more time.
I gave a presentation on this work at Tor Demo Day; the response from the Tor developers was enthusiastic. (My understanding is that Tor intends to post a video of the presentation.) I intend to send these patches upstream to Tor once Namecoin has battle-tested them for a few months.
In the field of reproducible builds, security derives from diversity. Adding the diversity of public CI infrastructure to the Namecoin and Tor reproducible build systems yields a major security bump. I’m looking forward to getting this upstreamed, and maybe adding additional CI services like GitLab and GitHub Actions to the mix in the future.
[1] Yes, I know that Hitler was referring to a container inside a VM, which means we’re still violating Hitler’s advice. Quiet, you.
Transaction queue for Namecoin Core
Lately, work aiming to simplify the RPC API for name management has been proceeding. This is done both for the sake of improvement itself, and to make it easier to write GUIs for Namecoin.
One unique element in Namecoin is the extensive use of time-dependent transactions. This is comparatively rare in Bitcoin. Either you want to send money or you don’t want to send money, but the “when” is usually ASAP. However, in Namecoin, it’s pretty common to, for instance, want to renew a name when it’s close to expiring, or register a name when its NAME_NEW input has matured.
Historically, this has been a bit of an annoyance. Transactions can only[1] be broadcast if they have a good chance of making it into the next block, and not all transactions are intended to be broadcast immediately. The way users had to deal with it, then, was to manually keep track of what transactions they wanted broadcast and when.
This isn’t suitable. It’s bad enough for direct users, but it also makes writing auxilliary software a pain, since the obligation will fall upon it to manage a lot of state. For example, the old name management GUI had to have a series of undocumented internal hooks into the wallet database.
For this reason, a transaction queue has now been added to Namecoin to explicitly manage all that state. It was written by Brandon Roberts, Jeremy Rand, and yanmaani, who is the author of this post. The implementation is actually shockingly simple:
- Keep a list of transactions we’d like to broadcast
- Each block, try to broadcast everything
- Remove everything that made it into the mempool
The initial plan was to have a very baroque API, where users could enter transactions and have them broadcast either when a name reached a certain age or when a transaction had a certain height. The reason for this was was that the transaction queue API was first implemented in Electrum-NMC, which doesn’t allow you to check whether a transaction is valid without leaking it to the server. Having already implemented all this, it was realized that Bitcoin’s existing locking facilities could already cover our needs for Namecoin Core, and so I took it out. Wasting the effort was a bummer, but you can’t be sentimental like that. In the end it made for a better API and cleaner code. Such is life.
The API for the transaction queue is thus very simple:
queuerawtransaction <hex> queues a transaction to be broadcast as soon as it can, and returns the txid on success. There is a basic sanity check to try and ensure the transaction at least theoretically could be broadcast at some point in the future, but there’s no guarantee. Note that it’s on you to properly lock the transaction, or else it will be broadcast immediately. If you want to update a name when it’s 35000 blocks old, make sure to set nSequence on the name input to 35001.
dequeuerawtransaction <txid> removes a transaction from the queue.
listqueuetransactions lists all the queued transactions. Note that this may also include transactions queued by RPC calls.
These changes will be available in Namecoin Core starting version 22.0.
This change was a prerequisite for name_autoregister, an RPC call to register a name in one step without having to manually call name_firstupdate, regarding which we endeavor to have an update in the next few days. That RPC call is the final pre-requisite for completing the new name management GUI.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
[1] Actually, this is only true in Bitcoin. In Namecoin, presumably to take the edge off this wart, there’s a special (somewhat ungainly) exemption for name_firstupdate, which was the cause of very serious bugs in the past, such as the June 2018 incident.
Deterministic salts in Namecoin Core
Namecoin Core will, starting version 22.0, no longer require that a salt or TXID be provided in the name_firstupdate RPC call. If no transaction ID is provided, the wallet will perform a linear scan over its unspent outputs to attempt to find a matching transaction. If no salt is provided, it will assume that it can be deterministically generated from the private key using the same scheme already implemented in Electrum-NMC.
To facilitate this, name_new has also been changed to use deterministically generated salts.
The old API is still supported; users are free to manually enter a salt, TXID, both, or neither. In fact, for name_new transactions created by versions of Namecoin Core prior to this change, the salt is still required. However, the transaction ID can always be determined automatically. In principle, it should only be necessary to provide the transaction ID to select which of several possible name_new outputs should be spent.
There is therefore no longer any need to write down the salt and transaction ID going forward. With the new API, registering a name from the RPC console works like this:
name_new "d/myname"
(wait 12 blocks...)
name_firstupdate "d/myname" [value]
Note that value is optional; omitting the parameter will cause Namecoin to use the empty string by default.
This change is being made as part of the effort to simplify the RPC API for name management. It was also one of the prerequisites for a new name registration GUI, work on which is intended to proceed shortly.
This work was funded by NLnet Foundation’s NGI0 Discovery Fund.
Freenode Undergoing Hostile Takeover – Abandon Ship
The Freenode IRC network is actively undergoing a hostile takeover by London Trust Media Holdings. All Freenode staff have resigned in protest. We strongly recommend that all Namecoin community members who are accessing our IRC channels via Freenode abandon ship immediately, and move to our channels on Hackint, OFTC, or Matrix.org.
Funding from NLnet
We are happy to announce that we have been selected by NLnet Foundation to receive funding. A total of €50’000 (roughly US$60’645) has been pledged toward our development work.
NLnet is a Dutch charitable foundation. It helps fund open-source projects that aim to promote the exchange of electronic information. In the past, they, along with their partners, have helped fund projects such as Tor, Qubes OS, WireGuard, Freenet, PeerTube, YaCy, Libre-RISCV, Briar, GNU Mes, GNU Guix, Replicant, Spectrum, NixOS, Reproducible Builds, Ricochet Refresh, and Namecoin. The full list of projects is available at https://nlnet.nl/project/index.html.
We will receive funding from NLnet’s NGI0 Discovery Fund. This fund is managed by NLnet and funded by the European Commission, the executive branch of the European Union, through their Next Generation Internet intitiative.
We are immensely grateful to NLnet for this decision, and to the European Commission for their generous financial support. A governmental institution that invests in decentralized Internet technologies has its eye toward the future.
We will use this funding to work on the following:
- Making name registration easier with automatic registration and deterministic salts.
- Making it safer and easier to buy and sell names with atomic name trading.
- Making censoring light wallets harder by lightweight SPV proofs of name nonexistence.
- Various security and performance improvements to Electrum-NMC and upstream Electrum.
- Improving on-chain privacy with coin control.
- Better Tor integration in Electrum, Namecoin Core, and hopefully Bitcoin Core.
This work will principally be done by developers Ahmed Bodiwala and yanmaani, who is the author of this post.
We will post updates on a regular basis as development proceeds.
Namecoin Released 10 Years Ago Today
Today, April 18, 2021, marks 10 years since Vincent Durham first released Namecoin. We’d like to wish a very happy birthday to the Namecoin community, and we look forward to the next 10 years (and beyond) of hijacking-resistant, censorship-resistant naming and PKI.
ncdns v0.1.2 Released
We’ve released ncdns v0.1.2 for Windows. This release includes a fix for an upstream issue that impacted Windows service support. Binaries for non-Windows platforms are not yet available; we expect to release those soon.
Full changelog of what’s new since v0.1:
- DNS:
- Fix caching bug that affected DS, SRV, MX, and non-dehydrated TLSA records. Patch by Jeremy Rand.
- TLS:
- Compressed ECDSA public keys are now supported in TLSA records, even for TLS implementations that do not support such keys. This paves the way for decreased blockchain storage. Namecoin patch by Jeremy Rand; thanks to Filippo Valsorda for implementing this in upstream Go.
- Add
aia.x--nmc.bitmeta-domain. This paves the way for layer-2 TLS; see my Grayhat 2020 presentation for details. Patch by Jeremy Rand.
- Windows:
- Support logging to Windows Event Log. Patch by Jeremy Rand; merged by Hugo Landau.
- Switch to Windows Service library from upstream Go instead of abandoned Conformal fork. This fixes a crash bug on Windows 10 when running as a Windows Service with ASLR/PIE enabled. Patch by Jeremy Rand; merged by Hugo Landau.
- Misc:
- Code quality improvements. Patches by Jeremy Rand.
- Build system:
- Support Go modules. Patch by Jeremy Rand; thanks to Hugo Landau for valuable input.
- Code quality improvements. Patches by Jeremy Rand.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin Core 0.21.0.1 Released
Namecoin Core 0.21.0.1 has been released on the Downloads page.
Here’s what’s new since 0.19.0.1:
name_showfor expired names will error by default. (Reported by Jeremy Rand; Patch by Yanmaani; Reviewed by Daniel Kraft.)name_showcan accept queries by SHA256d hash. (Reported by Jeremy Rand; Patch by Daniel Kraft; Reviewed by Jeremy Rand.)name_firstupdateandname_updatenow consider the value to be optional. (Reported by Jeremy Rand; Patch by Yanmaani; Reviewed by Daniel Kraft.)- Added
namepsbtRPC method. (Reported by Jeremy Rand; Patch by Daniel Kraft.) - Added new DNS seed for testnet. (Patch by Yanmaani; Reviewed by Daniel Kraft.)
- Fix build for WSL. (Patch by Chris Andrew; Reviewed by Daniel Kraft.)
- Fix crash on macOS 10.13+. (Reported by Jip; Analysis by Jip, Daniel Kraft, Andy Colosimo, and Cassini; Patch by DeckerSU; Reviewed by Daniel Kraft.)
- Code quality improvements for regression tests. (Patch by Daniel Kraft.)
- Numerous improvements from upstream Bitcoin Core.
Nightly Builds of ncdns and certinject
The Beta Downloads page now includes Nightly builds of ncdns (both the plain binaries and the Windows installer) and certinject. For the #reckless among you who want to help us test new features or identify bugs before a release, the Nightly builds are a great way to do so.
Namecoin Core Name Update GUI
Now that Namecoin Core’s Name Renewal GUI is complete (it’s been merged and will be in Namecoin Core v22.0), it’s time to move on to the name_update GUI. This forward-port was pretty uneventful, so rather than boring you with details, here’s a screenshot:
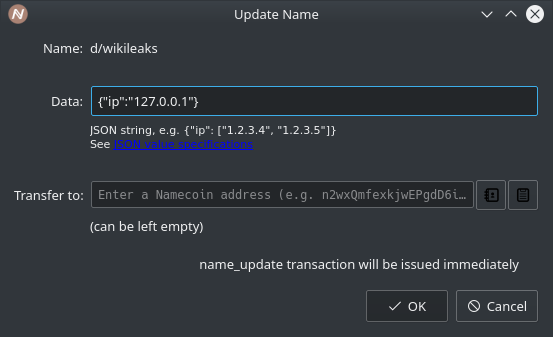
Code review will be needed before a merge can happen, but I expect the review process to be pretty uneventful as well.
ncdns v0.1 Released
We’ve released ncdns v0.1 for Windows. The big new feature is system-wide TLS support on Windows. Now any application that uses Windows for certificate verification (no longer just Chromium) will accept Namecoin TLS certificates, and will reject malicious certificates issued by public CA’s for Namecoin domains. Note that some Windows software, such as Firefox, does not use the Windows certificate verifier, and is therefore not supported by this feature.
Binaries for non-Windows platforms are not yet available; we expect to release those soon.
Full changelog of what’s new since v0.0.10.3:
- TLS:
- Negative overrides are now supported for CryptoAPI (patches by Jeremy Rand).
- Remove negative override support for Chromium (patches by Jeremy Rand).
- Switch from x509-signature-splice to splicesign (patches by Jeremy Rand, thanks to Filippo Valsorda for the suggestion).
- Code quality improvements (patches by Jeremy Rand).
- Build system:
- Fix silent NSIS installation (patches by Jeremy Rand).
- Support NSIS install.log (patches by Jeremy Rand).
- Code quality improvements (patches by Jeremy Rand)
As usual, you can download it at the Beta Downloads page.
CTLPop: Populating the Windows AuthRoot Certificate Store
In my previous post, I introduced improvements to certinject, which allow us to apply a name constraint to all certificates in a Windows certificate store, without needing Administrator privileges. Alas, there is a major issue with using certinject as presented in that post. The issue is that most of the built-in root CA’s in Windows aren’t part of any cert store!
Wait, What?
Yep. Allow me to explain. The root CA list in Windows is pretty large (420 root CA’s at the moment, if my count is correct), and can also be updated on the fly via Windows Update. However, due to what Microsoft claims are performance concerns, only 24 of those root CA’s are actually populated in the cert store on a fresh Windows installation. The full list lives in a file called AuthRoot.stl, which ships with Windows, and can also be updated via Windows Update. This file is a CTL (certificate trust list), meaning it only stores the hashes of the certificates (and a bit of other metadata), not the certificate preimages. (Why does a “CTL” have the file extension .stl rather than .ctl? Don’t ask. Just accept that Microsoft hates you. It’ll be easier that way.) When Windows tries to verify a certificate that chains back to a certificate in AuthRoot.stl but isn’t in the Windows certificate store, it automatically fetches the certificate preimage from Windows Update, and inserts it into the certificate store (typically in the AuthRoot logical store) prior to proceeding with the verification. This is all transparent to the user under typical circumstances.
Personally I am highly dubious that this is a meaningful performance optimization, especially since this system was created (AFAICT) around 2 decades ago, so even if it helped performance when it was introduced, I doubt that this performance gain is applicable on modern hardware (especially since today, network latency is a much bigger contributor to perceived performance than any kind of local CPU or IO performance, and this system entails extra network latency when verifying certificates with a previously-unseen root CA).
So What’s the Problem?
Well, unfortunately, if a root CA is being downloaded on-the-fly during certificate verification, that prevents certinject from applying a name constraint to it before it gets used. This is unfortunate, since it means that most of the root CA’s in Windows cannot be reliably constrained via certinject.
What Can We Do?
It’s entirely feasible to download the full list of certificate preimages that AuthRoot.stl refers to. There’s even a mostly-undocumented [1] certutil command for this. But what do we want to do with it? Two ideas occurred to me:
- We could download the full set of certs in SST (serialized store) format (which also includes all the metadata, i.e. Properties besides the cert preimage), and ask
certutilto import it to theAuthRootlogical store. Unfortunately, this means we’d need to run as Administrator, which is not really ideal. Also, how do we know for sure thatAuthRootis the right logical store to import them? Seems suboptimal. - We could download the full set of certs to individual files, and use
certinjectto individually inject them to theAuthRootstore, with Properties manually parsed from theAuthRoot.stlfile. While this does avoid running with Administrator privileges by virtue of usingcertinject, it means we’d have to carefully parse the Properties fromAuthRoot.stl, and make sure thatcertinjectis applying them correctly. Seems like a lot of attack surface. Also, we still don’t know for sure that they all belong in theAuthRootlogical store, and it still requires write privileges to theAuthRootstore’s registry key. So this is still not great.
Since neither of these jumped out at me as “obviously this is the right way to do it”, I came up with another idea.
Make Windows Do Our Job For Us!
If you were reading the first section of this post carefully, you might have noted that Windows itself will happily insert the certificates from AuthRoot.stl into the certificate store under certain circumstances, specifically when it’s necessary for certificate verification. Hmm, this sounds like something we can abuse! What happens if we download the full set of certificates to individual files from Windows Update, and then just politely ask certutil to verify all of them? Intuitively, this seems like the kind of thing that will cause the following Series of unFortunate Events:
- CryptoAPI tries to verify the certificate by chaining it to a root CA in the certificate store. This, naturally, fails.
- CryptoAPI checks whether the certificate chains to a root CA in
AuthRoot.stl. Yes, the certificate does claim to be issued by a root CA inAuthRoot.stl. (In reality, that’s because the certificate is issued by itself, but CryptoAPI can’t know this until it sees the issuing certificate.) - CryptoAPI helpfully fetches the root CA referenced by
AuthRoot.stlfrom Windows Update, and adds it to the certificate store. Yay, we’ve achieved our goal! - CryptoAPI discovers that the certificate we’re trying to verify is now marked as trusted, and
certutiltells us that verification succeeded. That’s cool and such, but we don’t really care about this step.
And the beauty of this trick is that we don’t need any elevated permissions for the certificate store (all we did was ask Windows to verify some certificates, which is obviously an unprivileged operation; Windows messed with the certificate store for us), nor did we need to worry about the Property metadata (again, Windows does this for us; there’s nothing we can screw up there no matter how buggy our code is).
And indeed, based on testing, the above workflow works exactly as I was hoping it would! Running certutil to verify a certificate in AuthRoot.stl downloaded from Windows Update does indeed result in the certificate being immediately imported to the certificate store. How cool is that?
(Side note: it turns out I was absolutely right to be wary of assuming that the AuthRoot logical store is the right place. In fact, the AuthRoot.stl CTL also covers a small number of Microsoft-operated root CA’s, which go in the Root logical store – AuthRoot is only for built-in root CA’s not operated by Microsoft.)
CTLPop: the AuthRoot Certificate Trust List Populator
I’ve created a simple PowerShell script called CTLPop, which automates this procedure. Just create a temporary directory (e.g. .\place-to-store-certs) to download certificates to, run ctlpop.ps1 -sync_dir .\place-to-store-certs, wait a few minutes (Travis CI indicates that it takes 4 minutes and 26 seconds to run twice in a row on their VM), and voila: now all 420 of the built-in root CA’s are part of your certificate store, ready for you to apply name constraints via certinject!
So What’s Next?
The easiest way to use CTLPop and certinject is to simply run CTLPop once as part of the ncdns NSIS installer, and then run certinject to apply the name constraint globally (again, as part of the NSIS installer). This is probably what we’ll ship initially, since it’s very simple and mostly works fine. However, it’s not great in terms of sandboxing (the NSIS installer runs as Administrator), and it’s also not as robust as I’d like (because if Microsoft updates the AuthRoot.stl list later, the new root CA’s won’t get the name constraint unless ncdns is reinstalled). The “right” way to do this is to have a daemon that continuously watches for AuthRoot.stl updates, and runs CTLPop and certinject whenever an update is observed. We could even add a dead-man’s switch to make ncdns automatically stop resolving .bit domains if the AuthRoot.stl-watching daemon encounters some kind of unexpected error. We’ll probably migrate to this approach in the future, since it’s much more friendly to sandboxing (CTLPop, which involves network access and parsing untrusted data via certutil, can run completely unprivileged, and certinject, which does not touch the network and doesn’t parse untrusted data, only needs read+write privileges to the Root and AuthRoot certificate stores), and also will handle new root CA’s gracefully.
Expect to see name constraints via CTLPop and certinject coming soon to an ncdns for Windows installer near you!
Epilogue
After this post was written, but before publication, I discovered that certutil actually has a built-in command that will do exactly the same thing as CTLPop: certutil -v -f -verifyCTL AuthRootWU. So, we can scrap the custom PowerShell implementation I wrote. Everything else, e.g. integration with the ncdns NSIS installer, remains the same. Why publish this post anyway? Because research isn’t always as clean as people sometimes imagine it to be. Researchers often pursue suboptimal leads; I think it’s useful to document the research process authentically rather than perpetuate the myth that scientists always know what they’re going to find in advance.
[1] It’s not documented at the certutil manual, but is mentioned elsewhere on Microsoft’s website.
External Name Constraints in certinject
In my previous post, I introduced the undocumented Windows feature for external name constraints, which allow us to apply a name constraint without the consent of a CA, and without needing to cross-sign the CA. I mentioned that the Windows utility certutil can be tricked into setting this Property on a certificate using the -repairstore command. Alas, abusing certutil to do this comes with some problems:
- The
-repairstorecommand looks suspiciously like it’s intended to be used for totally different purposes, and I simply do not trust it to only set a name constraint and nothing else. - Using
certutilto edit a public CA requires Administrator privileges, which is not great from a sandboxing perspective. - We’d ideally like to apply the name constraint to all of the root CA’s in the certificate store, not just a single one. The
certutilAPI doesn’t exactly make this impossible, but the UX is a lot worse than, say, thetlsrestrictnsstool I wrote that does something comparable for the NSS TLS library.
Those of you who’ve looked at the ncdns source code will recall that ncdns includes a library called certinject, which is designed to interact with Windows cert stores without needing Administrator privileges. Since certutil isn’t free software, but certinject is, and certinject already solves the privilege issue for us, Aerth and I have been extending certinject to do what’s needed for external name constraints.
Injecting to Arbitrary Cert Stores
The original certinject code only could write to the Root logical cert store in the Enterprise physical cert store. This is where root CA’s added by the system administrator would, by convention, be stored. This is fine for certinject’s original purpose of injecting self-signed certs for Namecoin websites, but all the CA’s we want to apply a name constraint to are elsewhere: generally in either the Root or AuthRoot logical cert store in the System physical cert store. (Root is where the Microsoft root CA’s live; AuthRoot is where the root CA’s run by non-Microsoft corporations live.) certinject can now inject certs into arbitrary logical stores (including the Disallowed logical store, which is used to mark a certificate as revoked), and now supports the System and Group-Policy physical stores in addition to the previously supported Enterprise physical store.
Serializing Properties
Originally, certinject only serialized Blobs that included the DER-encoded certificate, with no other Properties set. This worked fine for its original purpose, but we needed to make it more flexible. certinject can now serialize Blobs with arbitrary Properties set. certinject’s list of Properties supported by Windows is generated (to Go source code) via a Bash script (lots of grep and sed) using the wincrypt.h file from ReactOS as input. Curiously, wincrypt.h only seems to contain the Properties supported by Windows XP. A bunch of extra Properties were added in Windows Vista, but these are only listed in another header file, certenroll.h, which does not appear to exist in the ReactOS source code yet. At the moment, we don’t have any urgent need for the Vista Properties, so we’re sticking with the ReactOS header file for maximum free-software-ness.
certinject can also now generate the binary data for Properties involving either EKU (extended key usage) or name constraints. The Golang standard library doesn’t exactly make this easy; we settled on the approach of setting the EKU or name constraint fields in an x509.Certificate template, serializing the entire certificate, deserializing the result back to a template, and searching the template’s list of parsed Extensions for something that matched the OID of either EKU or name constraints. A tad inefficient, but this approach does seem to maximize the usage of stable, production-grade standard library API’s compared to custom parsing code on our end, so I think it’s safer than trying to roll our own super-efficient implementation.
While I was writing the EKU serialization code, I noticed that the Go standard library supports two EKU values that I had never heard of: ExtKeyUsageMicrosoftServerGatedCrypto and ExtKeyUsageNetscapeServerGatedCrypto. Some DDG-ing revealed that these are a historical relic of 1990’s-era export-grade cryptography (also referred to as “International Step-Up”). In particular, I found a Mozilla Bugzilla bug indicating that modern TLS implementations still support these 1990’s-era abominations because there exist public CA certs that rely on those particular EKU values, which didn’t expire until 2020. I decided to explicitly not support these EKU values in certinject; users who desire to see some mildly more colorful language describing my opinion of this functionality can grep the certinject source code for “beehive”.
We intend to add support for more Properties later; there are several other Properties that have caught our eye, although they’re not a very high priority for us right now.
The only other notable issue we encountered in Blob serialization is that we found experimentally that the Property containing the DER-encoded certificate must be the final Property in the serialized Blob. Any Properties that come after the DER-encoded certificate will be silently ignored. (This meant that our first try, which sorted Properties by ascending Property ID, didn’t work as intended, because the name constraint Property has a greater Property ID than the DER-encoded certificate. Oops!) Interestingly, Aerth was able to dig up a Microsoft documentation page indicating that listing any Properties after the certificate itself would yield undefined behavior. I guess now we know what that undefined behavior is.
Editing Existing Blobs
certinject was always a one-way thing: you put in the cert you want, and it spits out a Blob. However, this is not really desirable for the purpose of applying an external name constraint, because we don’t want to overwrite the Properties that already exist in the certificate store. (Many of them, e.g. EKU, are probably security-critical.) So we added functionality to read an existing Blob from the cert store and use that as the starting point, instead of creating an empty Blob with just the DER-encoded certificate.
This is not as complete as it could be. In the future, we intend to support fine-grained editing within a Property, e.g. adding a domain name to the name constraints list without destroying the existing name constraints.
Searching for Certificates by Hash
Originally, certinject was designed to accept a certificate as input, and it would then calculate the SHA1 hash itself for use as a Windows registry key. (Yes, Windows still uses SHA1 as a certificate identifier. Yes, this is stupid. No, it’s not our problem.) This made sense when the intent was to inject a cert that previously didn’t exist in the cert store, but since we now want to use it to edit existing certs, there’s no reason to force the user to know the preimage. certinject now allows the user to specify a SHA1 hash of a certificate, which will get passed through directly when constructing the registry key. This makes things a lot easier, and also leads to the next item.
Applying Operations Store-Wide
Our intent for external name constraints is to Constrain All The Things, i.e. we want all built-in root CA’s to be prohibited from issuing certificates for .bit domains. Put another way, for those of you who’ve worked with our NSS cross-signing tools, we want the UX to be more like tlsrestrictnss and not crosssignnameconstraint. certinject can now crawl the list of all certificates in a given certificate store, and apply the specified EKU or name constraint operations to all of them. For practical purposes, this would usually entail applying the name constraint to all certs in the Root and AuthRoot logical stores of the System physical store. Optionally, users might also want to apply the name constraint to the Root logical store of the Enterprise and Group-Policy physical stores.
This is not quite as complete as it could be. In the future, we intend to support tagging certificates with a “magic value”, which allows users to designate specific root CA’s that they want to exempt from the name constraint; certinject would then avoid applying the name constraint to those specific CA’s when doing a store-wide operation. This could be used to allow users to deliberately run a MITM proxy on .bit traffic for diagnostic purposes, without losing protection from other root CA’s that the user doesn’t want to intercept .bit traffic. (certinject already has some skeleton support for magic values, which ncdns uses for cleaning up expired certificates for privacy purposes. So this will not be hard to add.)
Adding a Command-line Utility
certinject now can be built as a command-line certinject.exe utility, which facilitates users who want to use it as an alternative to certutil from the command-line. It also supports both DER and PEM certficates, for maximal ease of use.
Adding Extensive Integration Tests
Cirrus CI now tests certinject daily for a variety of use cases against a real TLS client in a real Windows VM. This has already surfaced a few bugs (which we fixed), and also ensures that if Microsoft ships an update that changes the behavior we’re relying on, we will automatically get notified.
An interesting issue that we encountered here was that Windows tends to cache TLS cert verification results, which caused integration tests to interfere with each other. This caching is generally done on a per-process basis, so spawning a separate PowerShell process for each TLS handshake worked pretty well for avoiding this issue. (An exception is that Windows has some kind of special caching mechanism for “revoked” status, which is not on a per-process basis. This meant that our tests for the Disallowed logical store needed to take extra precautions, specifically sleeping for 30 seconds between consecutive TLS handshakes, so that the cache would expire. Yes, this is stupid.)
Another more boring (yet also more amusing) issue we found is that our initial on-a-whim choice of using github.com as a test case of a TLS cert that was publicly trusted backfired, because github.com promptly blacklisted our CI VM for rate-limit violations, causing our tests to start failing nondeterministically as soon as we had more than a few test cases. Oops. We switched these tests to use namecoin.org, which seems a tad more ethical, and all is okay now.
We also did a bunch of code cleanup, based on feedback from static analyzers.
So what’s next?
Stay tuned for a future post on how we’re going to integrate this new certinject functionality into Namecoin.
Undocumented Windows Feature: External Name Constraints
Name constraints are a little-known gem of a feature in X.509 certificates, which are used for TLS. A name constraint is a certificate extension, applied to a CA’s certificate, that contains a whitelist and/or blacklist of names (e.g. domain names) that the CA can issue certs for. There are 3 main reasons why a CA might want to have a name constraint:
- A commercial public CA might sell you a CA for your personal use, with a name constraint that whitelists only domains that you’ve demonstrated that you control. This works similarly to selling you an end-entity certificate, except that now you can renew your end-entity cert (perhaps rotating keys) without needing to interact with the commercial CA, since you now have your own CA you can use. This use case isn’t really used in practice, mostly because of regulatory capture (commercial CA’s have successfully made sure that the CA/Browser Forum regulations prohibit issuing name-constrained CA’s to members of the general public).
- A private CA, perhaps belonging to a corporate intranet or other internal network, wants to limit the damage it can do if it is later compromised, so it includes a name constraint that whitelists a TLD belonging to its intranet. Thus, if the private CA is later compromised, it can’t be used to attack websites on the public Internet. This is the stated motivation for Netflix’s BetterTLS test suite.
- A public CA wants to prevent itself from issuing certificates for specific TLD’s that have unique regulatory requirements that the CA isn’t able to comply with, so it includes a name constraint that blacklists those TLD’s. Thus, users of those TLD’s don’t have to worry about the public CA affecting their environment. The best-known example of this is that the Let’s Encrypt CA has sometimes used a name constraint that blacklisted
.mil, presumably because the U.S. military PKI has regulatory requirements that Let’s Encrypt didn’t want to mess with.
All of these use cases are quite valid and legitimate, but they assume one thing: that the CA wanted to be subjected to a name constraint. What do you do if you’ve been given a CA certificate that doesn’t have a name constraint, and you want to only trust it for a subset of names?
One approach is to cross-sign the CA – in other words, you create your own CA with the name constraint you want, and then produce a cert that’s identical to the CA you want to constrain, except with an issuer and signature from your constrained CA. This is not too hard; I actually wrote a tool called crosssignnameconstraint that does this for you. It works pretty well, but it does produce two potentially unwanted side effects:
- It transforms a root CA into an intermediate CA.
- It changes the fingerprint of the CA.
Both of these can result in unintended behavior from poorly designed TLS implementations, e.g. certificate pinning and EV certificates may behave differently when you cross-sign a certificate.
So, is there another approach we can use? If you’re on Windows, then the answer is yes!
Windows CryptoAPI stores certificates in a kind of funky way: certificates are stored not just in DER-encoded form, but in a custom data structure called a “certificate blob” that allows “properties” to be attached to the certificates. One example of such a property is a constraint on which extended key usages a CA can be used for. For example, you might want to import a CA that’s allowed to issue TLS client certificates but not allowed to issue TLS server certificates or sign code. When I was looking at the list of properties, most looked pretty mundane, but one jumped out: what the heck is this CERT_ROOT_PROGRAM_NAME_CONSTRAINTS_PROP_ID thing? Curiously, the documentation doesn’t say what it does; it’s simply marked as “Reserved”. However, looking at other properties’ documentation, it became clear that Microsoft has a habit of encoding extensions in ASN.1 format and stuffing the resulting binary data into a property. I also noticed that the Windows utility certutil actually has a way to edit arbitrary properties of certificates; it’s the (confusingly named) -repairstore command.
So, I cooked up a certificate that had a name constraint blacklisting .github.io, extracted the ASN.1 binary data for the name constraint extension into a hex blob, and instructed certutil to set it on the built-in root CA that GitHub Pages uses. I then tried to visit GitHub Pages in Chromium, and boom: a TLS error. Inspecting the CryptoAPI logs confirmed that the failure was due to a name constraint.
So, why is this feature there? Is it being used anywhere? As far as I can tell, it’s not used by anyone. The name of the property suggests that Microsoft intended to ship name constraints with its 3rd-party root CA’s, but I briefly checked the entire list of 3rd-party root CA’s, and it appears that none of them have this property set. The property was added to Windows over a decade ago (if Wine commit dates are to be believed), so perhaps Microsoft used it in the past and then decided to stop. Or perhaps they planned to use it, abandoned the plan, and left the code in place. Maybe it was intended for private PKI purposes, but later got shelved. Microsoft doesn’t document what this property does anywhere, and in fact I was unable to find even a single mention of this property on the public Internet besides the source code to Microsoft’s header files and the Microsoft documentation that marks it as “Reserved”. Amusingly, certutil knows exactly what this property is, and if you enable verbose output, it will even happily deserialize the name constraint ASN.1 data into a nice human-readable representation of the name constraint you’re applying.
Reserved or not, it definitely works, and it seems like a useful addition to a PKI toolbox. NSS, GnuTLS, and p11-kit do support external name constraints as well, but NSS requires a recompile if you want to change them, and the support in GnuTLS and p11-kit only works on a few distros (and no mainstream browsers). By supporting external name constraints that are actually enforced in arbitrary applications (including mainstream browsers) and can be edited by the user, Windows is leading the way on an excellent feature (Windows support for this long predates GnuTLS and p11-kit support) – it’s too bad that Microsoft didn’t bother to advertise this as a selling point.
More details on how we’re going to use this functionality in Namecoin will be in a future post.
Namecoin Presentation at Grayhat 2020 Monero Village
I gave a talk on October 31, 2020, at the Grayhat 2020 Monero Village, entitled “Namecoin as a Decentralized Alternative to Certificate Authorities for TLS”. A video recording is below:
Slides are here:
Huge thanks to Diego “rehrar” Salazar from Monero for inviting me!
License information: Diego’s introduction in the video is under a CC-BY 4.0 license.
Namecoin Will Present at Next Generation Internet Webinar on Naming Systems
I will present at the webinar “Next Generation Internet projects’ contribution to technological developments of DNS and naming systems” hosted by NLnet Foundation.
The presentation will cover work by Lola, yanmaani, and Ahmed. It will be December 10, 2020, 2:00 pm – 4:00 pm CET, and should be open to the public via NLnet Foundation.
Namecoin Core Name Renew GUI
Now that Namecoin Core’s name_list GUI is merged to master branch (it’ll be in the v22.0 release!), it’s time to move on to renewing names. As with the name_list GUI, I’m trying to follow the principles of (1) keeping PR’s small, and (2) keeping all the interesting logic in the RPC method rather than the GUI.
In service of principle 1, I’m not touching the “Configure Name” GUI, nor am I touching the “Renew Name” button; this only adds the right-click context menu for renewing names. In service of principle 2, yanmaani has done the excellent work of adding a renew mode to the name_update RPC method, which simplifies the GUI logic considerably.
So, without further rambling, here are some screenshots:
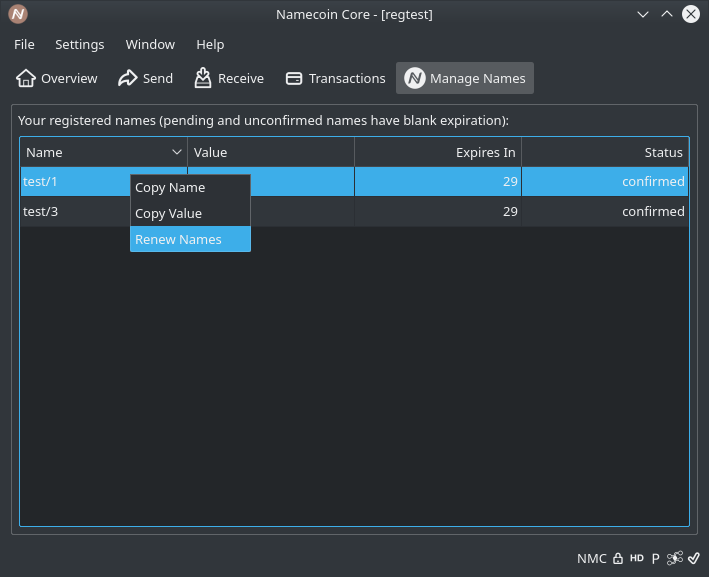
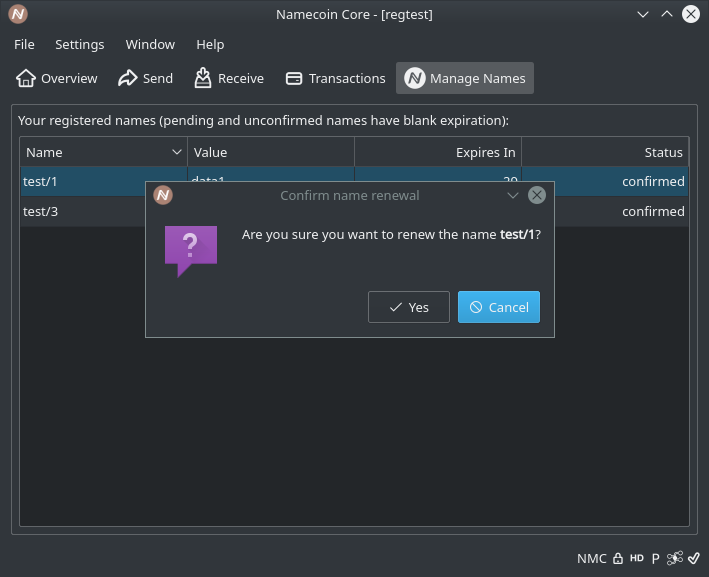
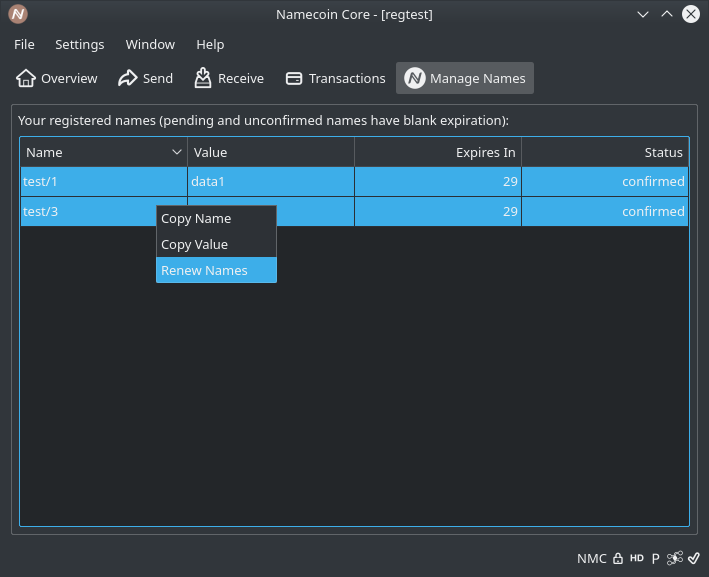
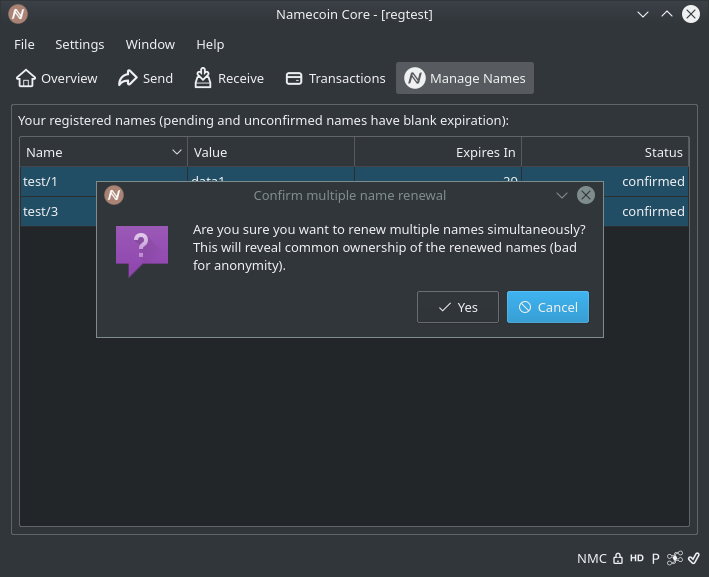
Astute readers will have noticed that you can now renew multiple names at once, like in Electrum-NMC. This was a minimal enough change from Brandon’s GUI that I figured I’d toss it in.
Some more code review will be needed, but I don’t expect any major obstacles getting this merged.
Namecoin Core name_firstupdate, name_update default values
Namecoin Core will, starting version 0.21, no longer require for a value to be provided in the name_update and name_firstupdate RPC calls. If no value is provided, Namecoin Core will use the last known such. If none exists, the empty string will be used. This change has no adverse impact on existing workflows, since it only makes previously required parameters optional. However, it does make it easier to update names. If no change in the value is desired, users will be able to directly issue an update for the name, without having to interrogate the present value with name_show. This simplifies a common workflow.
This change is being made as part of the effort to simplify the RPC API for name management.
Notes on building Python for Windows using RBM
Namecoin would like for Tor Browser to support .bit domains. The only mature, lightweight way to do this is to use the wallet qua name resolver Electrum-NMC. It is written in Python. To run Python software, you need an interpreter, like CPython.
Namecoin and Tor are both intended to be secure projects. All their binaries have to build reproducibly. The Tor Browser is also intended to be portable. It’s not acceptable for users to have to install additional software on their computer to run Tor Browser.
This means a Python interpreter would have to be bundled in order for Electrum-NMC to be includible in Tor Browser. And since Tor Browser is a secure project, said Python interpreter has to be built reproducibly. For this reason, the tor-browser-build repository has received some patches to reproducibly build such binaries.
This post details the problems encountered while making them.
Building CPython reproducibly for Linux is trivial. Download the source code, patch it to disable build timestamps, and compile. That’s it, you’re done.
The situation is markedly different on Windows. The official Python documentation suggests building with Microsoft Visual Studio 2017. This is no good. That compiler doesn’t support reproducible builds, it’s closed-source, and it would have to run in Wine.
There should be another way. CPython is written in standard C. GCC can cross-compile C software for Windows using MinGW - the compiler runs on Linux, but produces binaries for Windows. That’s how the Tor Project build Tor Browser for Windows. In theory, it should be possible to use GCC to cross-compile CPython for Windows, and a lot of Tor’s tooling should be possible to re-use.
In practice, Python’s ordinary build system doesn’t support this. It isn’t made for cross-compilation. Thankfully, one Erik Janssens had created an alternative Meson-based build script to compile Python for Windows with Linux using GCC and MinGW. Many thanks!
This build script needed some minor adaptations to properly integrate it with the Tor Project’s RBM build system. Meson and RBM both have built-in features for dependency handling, such as downloading files from URLs, verifying their hashes, and caching them. Doing this requires Internet access. When compiling, RBM disables Internet access.
The configuration script will thus have to download the binaries and move them into the cache directory used by Meson. This change also makes the build faster - RBM uses a fresh VM for each build, so unless the cache is outside of the VM, it will be wiped on each new build.
After this was done, RBM was able to produce something resembling a Python 3.8 interpreter. However, it wasn’t functional. Owing to what presumably was an idiosyncracy of the MinGW system, a critical library named libwinpthread-1.dll wasn’t included.
This problem turned out to be easy to fix. Ruben Van Boxem, a contributor to the MinGW project, suggested on StackOverflow that the compiler/linker simply be explicitly told to link this library statically. This worked:
$ wine python.exe
Python 3.8.5 (default, xx/xx/xx, xx:xx:xx) [gcc] on win32
>>>
The changes are now submitted and subject to review.
We think other projects that use Python might find these efforts useful. In particular, upstream Electrum may benefit from using a reproducible build of Python. We want to help others, so we try to submit patches and contribute where appropriate:
- The RBM build descriptor carries a custom patch to omit build timestamps in CPython. With this merged upstream, reproducible builds of CPython would become easier, and the maintenance burden lower.
- I have submitted some minor documentation changes for Mr. Janssens’s build script.
- The RBM build descriptor can be used to build Python, without necessarily building the Tor Browser.
Porting Namecoin in Tor Browser to Windows
As you no doubt remember from 36C3, the GNU/Linux version of Tor Browser Nightly comes with Namecoin support included. While we’ve received significant test feedback (overwhelmingly positive), it’s been pointed out that supporting Windows would enable additional test feedback, since not everyone has a GNU/Linux machine to test things on. So, I’ve been porting the Namecoin support in Tor Browser Nightly to Windows.
StemNS and Tor Bootstrap
First off, since this endeavor was going to involve some changes to StemNS, I figured this was a good opportunity to investigate an odd bug that was happening in StemNS sometimes. I had noticed last year that in a fresh Tor Browser install, if Namecoin was enabled on the first run, Tor Launcher would indicate that Tor bootstrap had stalled at the “loading authority certificates” stage. I found that spamming the Tor Launcher buttons to cancel and retry connecting would usually make the connection succeed after 5-10 tries, which seemed to suggest a race condition. After quite a lot of manual inspection of StemNS logs, I found something odd.
While the Tor control spec states that the __LeaveStreamsUnattached config option will cause all streams to wait for the controller (StemNS in this case) to attach them, this was empirically not what was happening. Rather, streams created as a result of user traffic (e.g. Firefox or Electrum-NMC) were waiting for StemNS to attach them, but streams created by Tor’s bootstrap were still automatically being attached. The Tor control spec goes on to say the following:
Attempting to attach streams via TC when “__LeaveStreamsUnattached” is false may cause a race between Tor and the controller, as both attempt to attach streams to circuits.
You can try to attachstream to a stream that has already sent a connect or resolve request but hasn’t succeeded yet, in which case Tor will detach the stream from its current circuit before proceeding with the new attach request.
This certainly explained what had been happening. Tor was opening a stream to bootstrap (attaching the stream to a circuit in the process), and (depending on exact timing) StemNS was trying to attach it a 2nd time, which caused the stream to be detached, thus killing the bootstrap.
At this point, I decided to ask the Tor developers whether this was a bug in the spec or the C implementation. Roger Dingledine pointed me to the exact C code that handled this, which indicated exactly how StemNS could detect this case and handle it properly. Roger also indicated that the C code was correct, and that the spec was incorrect. I concurred that this made sense.
I was then able to modify StemNS to handle this properly by detecting whether a new stream was created by user traffic or internal bootstrap, and only attaching streams from the former. Testing confirmed that the bug was fixed. Great, now let’s move on.
Exiting Namecoin when Tor Browser Exits
The existing Namecoin support in Tor Browser relies on a Bash script that signals Electrum-NMC and StemNS to exit after Firefox exits. Alas, Bash is only used as a launcher in GNU/Linux, so I needed to port this to a more cross-platform approach.
Tor Browser already solves this problem for the Tor daemon: Tor needs to exit when Firefox has done so. Tor Browser does this by having Firefox send the TAKEOWNERSHIP command to Tor, which instructs Tor to exit when Firefox closes the control port connection. This inspired me to do something similar in StemNS: I added an event listener to StemNS that triggers when Tor closes the control port connection to StemNS (which will happen when Tor exits). I configured the event listener to send an RPC stop command to Electrum-NMC (which will make Electrum-NMC exit), and then exit StemNS as well. (The latter took some DuckDuckGo-fu, as it turns out that sys.exit() can’t be called from a child thread in Python; the correct way to exit from a child thread is os._exit().)
Some testing revealed that this worked; I was able to remove the Bash code that terminated Electrum-NMC and StemNS, and they still exited properly. Moving on…
Launching Namecoin when Tor Browser Starts
Of course, the other part of the Bash launcher for Namecoin was the code that launches Electrum-NMC and StemNS. For this, I ended up copying/pasting the code in Tor Launcher that launches the Tor daemon. As XPCOM-based JavaScript code goes, Tor Launcher is pretty readable, so the copy/paste job wasn’t particularly eventful. I did notice that the documentation for debugging Tor Launcher was outdated, but the Tor developers on IRC were able to point me in the right direction there.
I won’t bore you with too many details on this part; it was mostly grunt work. But I got it working. Excellent, moving on….
Windows and Python
By this point, all of the GNU/Linux-specific code had been replaced with cross-platform code. So we were ready to move onto enabling Windows support. Most of this was as simple as tweaking the rbm descriptors to enable Namecoin on Windows, and fixing a few bugs where the Go dependencies for certain rbm projects were wrong on Windows. But, there was one issue that needed dealing with: Python.
Both Electrum-NMC and StemNS are written in Python. GNU/Linux systems generally have Python available by default, but this is not the case for Windows. In addition, on GNU/Linux, Python scripts are executable programs, but on Windows, they’re data files that need to be explicitly opened with the Python interpreter. This means that some Windows-specific things need to be done.
For Python being available, I took the easy way out: I simply defined [1] it to be out of scope, i.e. the user is responsible for installing Python themselves before enabling Namecoin in Tor Browser. I also rigged Tor Launcher to check every directory in the PATH for a Python interpreter, and to use the discovered Python binary as the executable, passing the Electrum-NMC or StemNS path as a command-line argument instead. Worked pretty well.
Finally, I re-implemented verbose logging for Namecoin (which was also part of the Bash code that I had removed). This was done via a TOR_VERBOSE_NAMECOIN environment variable. It does two things when enabled:
- Pass the
-vargument to Electrum-NMC, which enables verbose output. - On Windows, use
python.exe(which pops up a command prompt window with logs) instead ofpythonw.exe(which doesn’t spawn a command window).
Oh, and I had to tweak the linker flags for ncprop279 to make it avoid launching a command prompt window on Windows as well.
Epilogue
I sent in the code to the Tor Browser Team, and it’s now awaiting review.
In the meantime, I noticed that the __LeaveStreamsUnattached issue has a more correct fix now. The master branch of Tor and Stem recently added a new stream status, CONTROLLER_WAIT, which indicates specifically that a stream is now waiting for the controller to attach it. Thus, I’ve updated StemNS to only check for this status, rather than the mildly-convoluted previously-existing method of guessing whether a stream was waiting for this. That means StemNS’s master branch is now incompatible with Tor 0.4.5.0, Stem 1.8.0, and earlier. I’ve tagged a stable release that doesn’t include this refactor, and if any important bugfixes make their way into StemNS before the new Tor and Stem behavior gets into releases, I’ll probably backport them to a stable branch.
And now, we wait for code review from the Tor Browser Team. Let the bikeshedding begin!
This work was funded by Cyphrs and Cyberia Computer Club.
[1] This is a totally legit usage of definitional discretion. Really.
Namecoin Core name_list GUI
Namecoin Core’s name management GUI has always been a bit neglected. While we do have a GUI that works reasonably well, it’s been stuck in an old branch that is nontrivial to forward-port. The main reason that it’s been hard to maintain is that it depends on internal API’s that often get refactored, which breaks the GUI unless someone volunteers to constantly test the GUI whenever upstream refactors get merged (which is not a great use of anyone’s time). GUI code is also hard to test on Travis CI compared to CLI-accessible code, which compounds the problem.
Brandon accurately observed that a way to mitigate this issue is to expose all of the functionality that the GUI needs as RPC methods, and then simply make the GUI call RPC functions. (Bitcoin Core includes a built-in API for internally calling RPC functions.) This minimizes the amount of logic that the GUI needs to carry, which both enables integration testing and eliminates private API usage in the GUI code. This was partially done in Brandon’s branch that was used for the name tab binaries that we released, but unfortunately, there was still some logic that needed internal API’s.
So, I’m picking up where Brandon left off. For one thing, I’m splitting the code into multiple PR’s, which can be merged independently: the GUI equivalents of name_list, name_update, and name_autoregister. The first of these, name_list, is used for displaying the current name inventory. I’ve spent some time forward-porting the name_list GUI to current Namecoin Core, and here’s a preliminary result:
There’s still some more code cleanup needed before it can be merged, but I’m optimistic that we can get a merge to happen soon.
Namecoin Core name_show name expiration
Namecoin Core will, starting version 0.21, change the default behavior of the name_show RPC API call in the presence of certain errors to better match the documentation, the behavior of Electrum-NMC, and the behavior expected by users.
When Namecoin Core was first written, it exposed name resolution using an inconsistent API. When querying for a name that was not active, the behavior varied by the history of the name. If it had never been registered, Namecoin would return an error. If it had once been registered in the past, but was now expired, Namecoin would return a response that was deceptively similar to that returned when querying for names that were still active.
Owing to this inconsistency, some applications using Namecoin Core came to treat expired names as if they were still active. This was a security problem. Users continued to use services identified by the names as usual, and as such their operators did not re-register them, but Namecoin does not afford unregistered names any protection. Therefore, anyone could have registered the names, thereby hijacking the services. While this may be considered immaterial, it is our opinion that Namecoin should not indirectly encourage such dangerous use-cases.
Furthermore, those applications’ use of the API for this purpose was incorrect. Expired names should not be considered alive, and it can hardly be thought that considering them as such would have been the intent in implementing it. A programmer who relied solely on the documentation (“Looks up the current data for the given name. Fails if the name doesn’t exist.”) would not be left with the impression that the operation would, in fact, only fail for never-registered names.
For these reasons, a change to the name_show API in Namecoin Core has been made.
name_show will now by default throw an error when attempting to resolve an expired name.
This brings the default behavior in line with Electrum-NMC, which has always thrown an error.
The old behavior can be preserved by setting the allowExpired option or -allow_expired command-line parameter to true.
There are presently no plans to deprecate these flags.
This change will be included in version 0.21 of Namecoin Core.
Downstream users who use name_show to resolve names for user-facing purposes should not need to make any changes to their usage.
Downstream users who use name_show to resolve names, but who would also like to distinguish between names that have expired and names that have never been registered, are encouraged to explore the allowExpired field in the JSON RPC options argument and the -allowexpired command line parameter.
In such cases, the old behavior still applies, whereby downstream users are expected to consider the value of the expired field to ascertain whether a domain has expired.
This change does not affect the resolution of active names in any way.
This change does not affect the name_history or name_scan RPC calls.
This change does not affect Electrum-NMC.
We oppose the takeover of Open Technology Fund – closed-source projects are scams and must not receive “Internet Freedom” funding
We are watching with alarm the currently-ongoing takeover of the Open Technology Fund (OTF) by the Trump Administration’s newly appointed CEO of the US Agency for Global Media (USAGM, formerly known as BBG), Michael Pack. In the first week of the new USAGM leadership, Michael has fired OTF CEO Libby Liu and OTF President Laura Cunningham, and (according to a document released by Libby) is apparently preparing to redirect OTF funding away from the current diverse set of open-source tools in favor of a small set of tools, narrowly focused on censorship circumvention, including the closed-source scam projects “Freegate” and “Ultrasurf”.
Developers of Internet Freedom software, including but not limited to Namecoin, are on the known target lists of intelligence agencies of repressive governments. The open-source nature of our tools is a prerequisite for users to verify that we have not backdoored the software (e.g. to get dissidents killed). Furthermore, our own safety as developers is dependent on those intelligence agencies being aware that trying to coerce us to add a backdoor would be futile due to our software’s open-source nature.
For this reason, Namecoin doesn’t just settle for releasing our code under an OSI/FSF-approved license; we lead by example and push forward the front lines of openness. For example:
- We strive for reproducible builds in all software we release.
- We use computers with open-source firmware such as the Asus C201 and the Raptor Talos II for as much of our workflow as possible.
- We contribute patches to upstream software infrastructure for reproducible builds (e.g. the Gitian and rbm tools used by Tor include patches we authored).
- We contribute code to software projects improving support for platforms with open-source firmware (e.g. we contribute patches to PrawnOS, we reverse-engineered the Talos II NIC firmware, and we are in the process of porting Tor Browser to ARM and POWER).
Let us be very clear: software projects that claim to enable “Internet Freedom” but which do not share this commitment to open-source principles are scams. They actively endanger dissidents who are unwise enough to use them. Under no circumstances should they receive OTF funding, or any other type of taxpayer-derived funding.
In addition, the needs of dissidents are substantially more diverse than solely censorship circumvention. Software to defend against surveillance is also critical, as are security audits, bug bounty programs, and countless other areas that OTF currently funds. If anything, OTF’s remit would benefit from expansion; narrowing their focus to solely censorship circumvention will leave critical projects in the lurch, endangering the safety of dissidents worldwide. We are particularly concerned about the harm caused by a narrow focus on censorship circumvention functionality due to the following considerations:
- Users have empirically been demonstrated to not understand the difference between anonymity and anti-censorship functionality, and giving them software that’s not safe for anonymity will result in many users using it in ways that are dangerous.
- Even in a fantasy world where 100% of the users who actually need anonymity stick with tools that are safe for that use case, an exodus of the rest of the users will leave the anonymity-requiring users with a dangerously small anonymity set. It is well-known that the reason NRL opened onion routing to the public is that an anonymity network only used by the US Navy doesn’t actually help anonymize the US Navy. For the same reason, an anonymity network used by Chinese dissidents who require anonymity to stay safe must have a large amount of cover traffic, and users who are circumventing censorship are a major source of that cover traffic.
- Censorship circumvention software that relies on security by obscurity is more likely to be censored, potentially with catastrophic timing.
- Closed-source software, even if it is not required to preserve anonymity, is likely to be vulnerable to non-anonymity security bugs due to lack of peer review. At this point we’re not even talking about repressive governments deanonymizing users, we’re talking about repressive governments obtaining remote code execution on dissidents’ machines. At that point dissidents are screwed.
- These closed-source censorship circumvention systems consider the centralized operators to be completely trusted 3rd parties. There is nothing preventing these operators from covertly collecting logs of the activity of dissidents, and selling them to the highest bidder (which will probably be the governments of the countries in which the dissidents reside). Even in the fictional scenario where these operators don’t intend to do this, an intelligence agency who compromises the operators’ infrastructure can pull off this attack without the operators’ knowledge or consent. Again, at this point dissidents are screwed.
We have signed an open letter asking Members of U.S. Congress to:
- Require USAGM to honor existing FY2019 and FY2020 spending plans to support the Open Technology Fund;
- Require all US-Government internet freedom funds to be awarded via an open, fair, competitive, and evidence-based decision process;
- Require all internet freedom technologies supported with US-Government funds to remain fully open-source in perpetuity;
- Require regular security audits for all internet freedom technologies supported with US-Government funds; and
- Pass the Open Technology Fund Authorization Act.
While it is regrettable that so much Internet Freedom infrastructure is dependent on OTF (Decentralize All The Things!), and it would be advisable for affected projects to investigate diversifying their funding sources, that cannot be done overnight. The damage done by a successful hijacking of OTF will occur overnight, and will cause lasting damage that cannot be mitigated by a long-term strategy of diversification. As such, it is critical that the decentralization community oppose the OTF takeover.
Help us save OTF from takeover. You can find more information on how to help here.
Electrum-NMC v3.3.10 Released
We’ve released Electrum-NMC v3.3.10. This release (which is still based on upstream Electrum v3.3.8) includes a few high-demand bug fixes that we wanted to get released before upstream Electrum tags v4.0.0.
Here’s what’s new since v3.3.9.1:
- From upstream Electrum:
- Build script fixes. (Backported from Electrum v4.0.0.)
- Fix connecting to non-DNS IPv6 servers on Windows. (Backported from Electrum v4.0.0.)
- Namecoin-specific:
- Features:
- Enable Renew/Configure buttons based on selection. (Patch by Jeremy Rand.)
- Bug fixes:
- Fix
name_showfault detection. (Patch by Jeremy Rand; thanks to s7r for reporting issue.) - Fix exception when right-clicking on a
name_newfor which the name identifier is unknown inUNOList. (Patch by Jeremy Rand; thanks to ghost for reporting issue.) - Fix exception handling in name registration Qt GUI. (Patch by Jeremy Rand; thanks to s7r for reporting issue.)
- Fix Mempool-based fee estimation limits. (Patch by Jeremy Rand; thanks to s7r for reporting issue.)
- Fix
- Features:
Unfortunately, due to a currently-unresolved upstream bug, we are not able to provide Android/Linux binaries at this time. Android/Linux users should remain on v3.3.9.1.
As usual, you can download it at the Beta Downloads page.
Deterministic Salts
When Namecoin was first being designed, an attack had to be dealt with: the frontrunning attack. The attack works like this:
- Julian broadcasts a transaction, indicating that he wants to buy
wikileaks.bit. - Keith sees Julian’s transaction as soon as it gets broadcasted.
- Keith infers that Julian places a significant value on
wikileaks.bit. - Keith broadcasts his own transaction, trying to buy
wikileaks.bit. - Keith bribes a miner to mine his transaction rather than Julian’s. (This could be done by using a much higher transaction fee than Julian’s transaction, or it could be done via out-of-band channels, perhaps a court order.)
- Keith now owns
wikileaks.bit, not Julian, even though Julian was the first person to try to buy it.
Astute readers will note that the fundamental problem here is that DNS-like systems are supposed to be “first-come-first-served”, but a blockchain isn’t able to meaningfully determine which transaction came first if they were both broadcasted before either was mined. Similar problems happen in Bitcoin when an attacker tries to spend the same coins to two different destination addresses at the same block height: there’s no reliable way to determine which spend came first, so it’s up to the miners to decide.
So, how was this fixed? Via commitments. When Julian wants to buy wikileaks.bit, he first broadcasts a commitment transaction. The transaction doesn’t reveal the name he wants to buy; it instead consists of a hash of two things: the name he wants to buy, and a secret randomly generated string (called a salt). Without knowing the salt and the name already, Keith can’t determine what name Julian is buying. And since the salt is randomly generated and is high in entropy, Keith can’t even mount a dictionary attack on the hash; even if Keith suspects that Julian is buying wikileaks.bit, Keith can’t verify this without knowing the salt.
After the commitment transaction has received 12 confirmations, Julian broadcasts a 2nd transaction that reveals the name and the salt. Once this 2nd transaction is mined, Julian officially owns wikileaks.bit. The key point here is that once the 2nd transaction is broadcasted, Julian only needs 1 block to be mined in order to obtain the name – but if Keith tries to register it, he’ll need to broadcast his own commitment (now that he knows the name) and wait for 12 blocks before he can register the name. In other words, the existence of the commitment gives Julian a 12-block head start against Keith, which should ensure that Julian gets the name (unless Keith has successfully bribed the miners of 12 blocks in a row, which seems unlikely).
This scheme brings important security, but it also poses a problem. Imagine the following:
- Matthew broadcasts a commitment transaction for
theintercept.bit. - Sometime in the next 12 blocks, Matthew’s hard drive dies.
- Matthew restores his wallet from his seed phrase on another machine.
- Matthew tries to register
theintercept.bitby spending the commitment transaction in his wallet. - Uh oh. Matthew’s wallet doesn’t know what the salt is! It was only on the hard drive that died. Matthew forfeits the name registration fee, and has to start over.
Can we improve this situation? Yes! The answer is deterministic salts.
On a high level, we want the wallet application to pick a salt that is reliably predictable to the wallet owner, but still unpredictable to anyone else. We homed in on the following secret knowledge:
- The private key of the address that owns the commitment transaction.
- The name being registered.
We don’t want the name to be the only input to the salt, since at that point the salt is pretty much ineffectual: remember that the purpose of the salt is to stop people who can guess the name from figuring out whether their guess is accurate! We also don’t want the private key to be the only input, because this would imply predictable salt reuse if address reuse occurs. (Yes, I know, address reuse is bad. But address reuse is typically only a privacy harm; there’s no reason to unnecessarily exacerbate the impact of address reuse by turning it into a name theft harm too.)
So, how do we combine the private key and the name to get a salt? It turns out that there’s a standard cryptographic function for this: HKDF (RFC 5869). Conveniently, HKDF is already present in both Bitcoin Core and Electrum, so no additional libraries need to be imported. Specifically, we can use the following HKDF parameters:
- Initial key material: private key
- Salt: name identifier
- Info: “Namecoin Registration Salt”
The “Info” parameter is designed to prevent cross-protocol attacks, where someone uses the same construction for two completely different purposes in order to induce a user of one protocol to compromise themselves in the other protocol.
I’ve now implemented HKDF-based deterministic salts in Electrum-NMC. For example, you can now do the following command as before:
name_new("d/example")
And you’ll get back a transaction and a salt, like before. But, you’re now free to ignore this salt, because you don’t need it anymore! You can complete the registration 12 blocks later like this:
name_firstupdate("d/example")
Note that you don’t need to enter a salt or a TXID anymore! Electrum-NMC checks each name_new UTXO in its wallet to see if the output of HKDF yields the commitment in the name_new, and if it does, Electrum-NMC uses that TXID and salt automatically. This works even if you’re running name_firstupdate after restoring the wallet from a seed on a different machine than the one that produced the name_new transaction.
Pretty cool, huh?
Thanks to s7r for the idea of deterministic salts; thanks to Ryan Castellucci for cryptographic advice; and thanks to Daniel Kraft for discussions about Namecoin Core integration.
Video Recordings of ICANN60 Joint Meeting of ICANN Board and Technical Experts Group
At Namecoin, we generally try to be good citizens in the broader community. This means that we regularly engage in analysis, peer review, and patch writing for projects that aren’t strictly part of Namecoin. In that spirit, today we are posting free-software-friendly video recordings of the Joint Meeting of the ICANN Board and the ICANN Technical Experts Group at ICANN60 in Abu Dhabi on November 1, 2017. We hope that making this session more accessible to free software users will facilitate increased peer review, analysis, and research.
This session included the following presentations:
- Alain Durand and Fernando Lopez: DOA-like Persistent Identifiers over DNS: a Prototype
- Leonard Tan: Ethereum Name Service
- Michael Palage and Pindar Wong: Distributed Ledger Technology (aka Blockchain): Evolution or Revolution
- Steve Crocker: Tamperproof Root Zone Management System
Low-Quality Free-Software-Friendly Video Recording (With Slides)
High-Quality Free-Software-Friendly Video Recording (Without Slides)
Credits
The above free-software-friendly recordings are converted from ICANN’s official recordings. Copyright ICANN; used with permission. Additional material, e.g. audio-only recordings, slides, and transcripts, can be found on ICANN’s website.
Namecoin Merchandise Now Available at Cypher Market
Namecoin-branded merchandise (e.g. T-shirts and stickers) are now for sale from our friends at Cypher Market. Not only is this a good way to spread the word about Namecoin, but Cypher Market also donates a cut of the profits to support Namecoin development.
Electrum-NMC v3.3.9.1 Released
We’ve released Electrum-NMC v3.3.9.1. This release (which is still based on upstream Electrum v3.3.8) includes a few high-demand new features and bug fixes that we wanted to get released before upstream Electrum tags v4.0.0.
Here’s what’s new since v3.3.8:
- From upstream Electrum:
- Build script fixes backported from Electrum v4.0.0.
- Namecoin-specific:
- Features:
- Add DNS builder GUI based on Namecoin Core. (Patch by Jeremy Rand; based on a Namecoin Core patch by Brandon Roberts.)
- Add more servers. (Patches by Jeremy Rand; thanks to deafboy, ccomp, and s7r for running the servers.)
- Allow pausing network on startup; unpause via an RPC command (mostly relevant for Tor Browser integration). (Patch by Jeremy Rand; thanks to Georg Koppen and mjgill89 for reporting Tor Browser issue; thanks to SomberNight for brainstorming solutions.)
- Update checkpoint. (Patch by Jeremy Rand.)
- Bug fixes:
- Return correct error code when looking up nonexistent names. Fixes issue where ncdns was recognizing this error as
SERVFAILinstead ofNXDOMAIN. (Patch by Jeremy Rand; thanks to Georg Koppen for reporting Tor Browser issue.) - Fix connectivity issues that could cause slow syncup or syncup getting stuck completely (these bugs were related to the stream isolation and parallel chain download patches). (Patches by Jeremy Rand; thanks to Georg Koppen, mjgill89, and s7r for reporting issues.)
- Fix minor error handling bugs in name registration GUI and
name_showRPC command. (Patches by Jeremy Rand; thanks to s7r for reporting issues.) - Add some additional AuxPoW checks. (Patches by Jeremy Rand.)
- Disable stream-isolated server pool if in
oneservermode (fixes a privacy leak). (Patch by Jeremy Rand; thanks to s7r for reporting issue.) - Fix missing help text for
name_showRPC command. (Patch by Jeremy Rand.) - Fix missing locale data in Python binaries. (Patch by Jeremy Rand.)
- Return correct error code when looking up nonexistent names. Fixes issue where ncdns was recognizing this error as
- Features:
As usual, you can download it at the Beta Downloads page.
Transproxy Support in ZeroNet
ZeroNet supports Namecoin as a naming layer. Unfortunately, the UX for this feature isn’t quite optimal. Specifically, the .bit domain shows up in the path of the URL rather than the hostname; the hostname is the hostname of the machine running ZeroNet (typically 127.0.0.1). Can this be improved?
In a word, yes. I’ve added transproxy support to ZeroNet, which facilitates a much better UX. This feature uses the HTTP Host header to determine which .bit site is being accessed. So if the .bit site points to 127.0.0.1, you can type in the domain into your web browser, and your browser will automagically tell ZeroNet which website to display.
As an example, here’s ZeroTalk displayed in Firefox in transproxy mode:
This screenshot was obtained by fiddling with the OS’s hosts file, but automatic ZeroNet integration could be added to ncdns in the future.
Namecoin Website Now Available via Namecoin at Namecoin.bit
The Namecoin website is now available via Namecoin at https://namecoin.bit/. The TLS certificate should work in most Namecoin-supported TLS clients, but unfortunately doesn’t yet work with Tor Browser. This will be fixed in the future.
Electrum-NMC: ETA Display for Name Registrations
Recently, I was put in contact (via a mutual friend) with a new Namecoin user, Forest Johnson, who was having some trouble registering a name with Electrum-NMC. Unlike typical software users, who tend to give up when encountering issues, Forest was kind enough to provide some excellent UX review of Electrum-NMC. One piece of that UX review was that it’s not obvious to a user that registering a name is a two-step process, and that the latter step can’t proceed until the former step has 12 confirmations. So, I’ve added an ETA indicator for name registrations to the Manage Names tab. Check it out:
Forest provided quite a bit of additional UX review; I intend to address those points in the future. Thanks Forest for making Namecoin better!
Tor 0.4.3.1-alpha Released; Includes Namecoin Stream Isolation Patch
The Tor Project has released Tor 0.4.3.1-alpha. Among the usual interesting changes, Namecoin users will be interested to note that Tor 0.4.3.1-alpha includes Namecoin’s stream isolation patch for Tor controllers such as StemNS, which paves the way for better Namecoin resolution support for Tor. Kudos to The Tor Project on getting Tor 0.4.3.1-alpha released!
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
ncdns v0.0.10.3 Released
We’ve released ncdns v0.0.10.3. Here’s what’s new since v0.0.9.2:
- DNSSEC-HSTS:
- Support Chromium and Google Chrome (patch by Jeremy Rand).
- madns:
- Support stream isolation via EDNS0 (patch by Jeremy Rand, merged by Hugo Landau).
- ncdns:
- Support stream isolation via EDNS0 (patch by Jeremy Rand).
- Use modern btcd for JSON-RPC client (patch by Jeremy Rand).
- Make TLSA support disableable at build time (patch by Jeremy Rand).
- Documentation improvements (patches by Jeremy Rand).
- Code quality improvements (patches by Jeremy Rand).
- ncdumpzone:
- Fix infinite loop when dumping with Namecoin Core 0.18.0 and higher (patch by Jeremy Rand).
- ncprop279:
- Add “Only Onion mode” (patch by Jeremy Rand).
- Support stream isolation via EDNS0 (patch by Jeremy Rand).
- Use modern btcd for JSON-RPC client (patch by Jeremy Rand).
- Make TLSA support disableable at build time (patch by Jeremy Rand).
- Code quality improvements (patches by Jeremy Rand).
- qlib:
- Fix build error on current Go compiler versions (patch by Zigmund, merged upstream by Miek Gieben).
- Support configurable timeouts (patch by Jeremy Rand, merged upstream by Miek Gieben).
- tlsrestrictnss:
- Code quality improvements (patch by Jeremy Rand).
- x509-signature-splice:
- Support multiple Go compiler versions (patch by Jeremy Rand).
- Build system:
- Bump rbm dependencies to latest releases (patches by Jeremy Rand).
- Bump NSIS dependencies to latest releases (patches by Jeremy Rand).
- Code quality improvements (patches by Jeremy Rand).
- Build reproducibility improvements (patches by Jeremy Rand).
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Video of Daniel Kraft at CloudFest 2019
As was previously announced, Daniel Kraft represented Namecoin at CloudFest 2019. Here is the video of Daniel’s talk:
What The Cryptocurrency Boom Missed: The Namecoin Story
To hear Daniel Kraft, the lead engineer of Namecoin, say it – “Bitcoin frees money, Namecoin frees DNS, identities, and other information”. Namecoin is the second oldest cryptocurrency after Bitcoin, but it is more than that. It builds a naming system that is decentralised, trustless, secure and has human-readable names. As such, it is the world’s first solution to “Zooko’s triangle”. Applications range from secure management of online identities and cryptographic keys and a decentralised alternative to the DNS and the certificate-authority infrastructure to fully decentralised multiplayer online games. Find out why cryptocurrency technology is so much more than merely an investment, and discover how it is being employed to put greater privacy and security tools into the hands of consumers.
The video recording can be viewed via youtube-dl (Debian package) (recommendation by Whonix) if you don’t trust YouTube’s JavaScript (and there’s no reason why you should trust YouTube’s JavaScript!).
36C3 Summary
As was previously announced, I (Jeremy Rand) represented Namecoin at 36C3 in Leipzig, Germany. As usual, it was an excellent event. As usual for conferences that I attend, I engaged in a large number of conversations with other attendees. Also as usual, I won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to me at conferences without worrying that off-the-cuff comments will be broadcast to the public.
Namecoin gave 2 talks, as well as a workshop, all of which were hosted by the Monero Assembly and the Critical Decentralization Cluster (CDC). Below are the slides and videos of Namecoin’s talks, as well as the notes from Namecoin’s workshop. The videos can be viewed via youtube-dl (Debian package) (recommendation by Whonix) if you don’t trust YouTube’s JavaScript (and there’s no reason why you should trust YouTube’s JavaScript!).
Lightning Talk: Intro to Namecoin
Speaker: Jeremy Rand
Namecoin is a blockchain (first project forked from Bitcoin) that implements a decentralized DNS and public key infrastructure, which is resistant to censorship, hijacking, and other tampering. This talk will explain the basics of how Namecoin works and what it can be used for.
Transcript is here (thanks to XMR.RU).
Russian translation is here (thanks to XMR.RU).
Lecture: Adventures and Experiments Adding Namecoin to Tor Browser
Speaker: Jeremy Rand
The Namecoin and Tor developers are running a new experiment: the GNU/Linux Nightly Builds of Tor Browser now have optional support for resolving Namecoin’s .bit domains. This experiment aims to provide a fix for the long-standing UX problem with .onion domains: the lack of human-meaningful names. With Namecoin, you can access onion services via nice, memorable addresses like http://federalistpapers.bit/ instead of http://7fa6xlti5joarlmkuhjaifa47ukgcwz6tfndgax45ocyn4rixm632jid.onion/ . In this talk, I’ll cover the goals of the experiment, the work that went into getting here, and the work that remains to be done.
Disclaimer: Although the work covered in this talk is a collaboration between Namecoin and Tor, this talk is solely from Namecoin’s perspective.
Transcript is here (thanks to XMR.RU).
Russian translation is here (thanks to XMR.RU).
Workshop: Demo and Discussion: Namecoin in Tor Browser
Workshop Host: Jeremy Rand
The Namecoin and Tor developers are running a new experiment: the GNU/Linux Nightly Builds of Tor Browser now have optional support for resolving Namecoin’s .bit domains. This experiment aims to provide a fix for the long-standing UX problem with .onion domains: the lack of human-meaningful names. With Namecoin, you can access onion services via nice, memorable addresses like http://federalistpapers.bit/ instead of http://7fa6xlti5joarlmkuhjaifa47ukgcwz6tfndgax45ocyn4rixm632jid.onion/ . In this workshop, you’ll be able to try it out yourself. Bring a GNU/Linux machine (bare-metal or VM are both fine). After the demo, I’d love your feedback on what our next steps should be in this area.
I highly recommend attending my talk “Adventures and Experiments Adding Namecoin to Tor Browser” prior to this workshop, but this is not a hard requirement; attendees who didn’t attend that talk are still welcome.
Disclaimer: Although the work covered in this workshop is a collaboration between Namecoin and Tor, this workshop is solely from Namecoin’s perspective.
Thanks
Huge thank you to the following groups who facilitated our participation:
We’re looking forward to 37C3 in December 2020!
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Namecoin Core 0.19.0.1 Released
Namecoin Core 0.19.0.1 has been released on the Downloads page.
Here’s what’s new since 0.18.0:
- The mempool now allows multiple updates of a single name (in a chain of transactions). This is something that is allowed in blocks already, i.e. it is just a policy change. The
name_updateRPC command still prevents such transactions from being created for now, until miners and relaying nodes have updated sufficiently. More details can be found in #322. - Numerous improvements from upstream Bitcoin Core.
Namecoin’s Jeremy Rand will be at 36C3
You might have noticed a relative quietness on this news feed and on our social media in the last few months. If you’re a particularly astute student of history, you might have noticed that something very similar happened around the same time last year, and that this was because Aerth and I were busy cooking up ncp11 for a 35C3 talk and workshop. If you’ve gotten that far, you might have gone one step further and guessed that something similar is responsible for the quietness this year. You’d be right! I (Jeremy Rand) will represent Namecoin at 36C3 (the 36th Chaos Communication Congress) in Leipzig, December 27-30. (Alas, Jonas and Cassini won’t be there this year.)
Unfortunately, we’re running very down to the wire on our content for 36C3. To the point that we are not yet sure which content we’ll be able to present. We’re doing everything in our power to try to ensure that we’ll have a kickass talk and workshop ready for you at 36C3, but it is likely that the details will not be finalized until shortly before the Congress begins. The good news is that this is for a good reason: the content we want to be able to present at 36C3 is, arguably, even cooler than ncp11 last year.
Once again, Namecoin will be hosted by the Monero Assembly, which is part of the Critical Decentralization Cluster (CDC). The schedule for CDC events isn’t yet finalized, but keep an eye on the schedule for details. We heard a rumor that talks might get recorded and live-streamed (for real this time… maybe). Also thanks go out to our friends at Replicant, who are facilitating Namecoin’s participation. We’re looking forward to the Congress!
This news post was edited on December 21 to add additional links.
DNS Builder GUI for Electrum-NMC
In November 2017, Brandon posted some WIP code for adding a DNS Builder GUI to Namecoin-Qt. To refresh your memory, it looked like this:
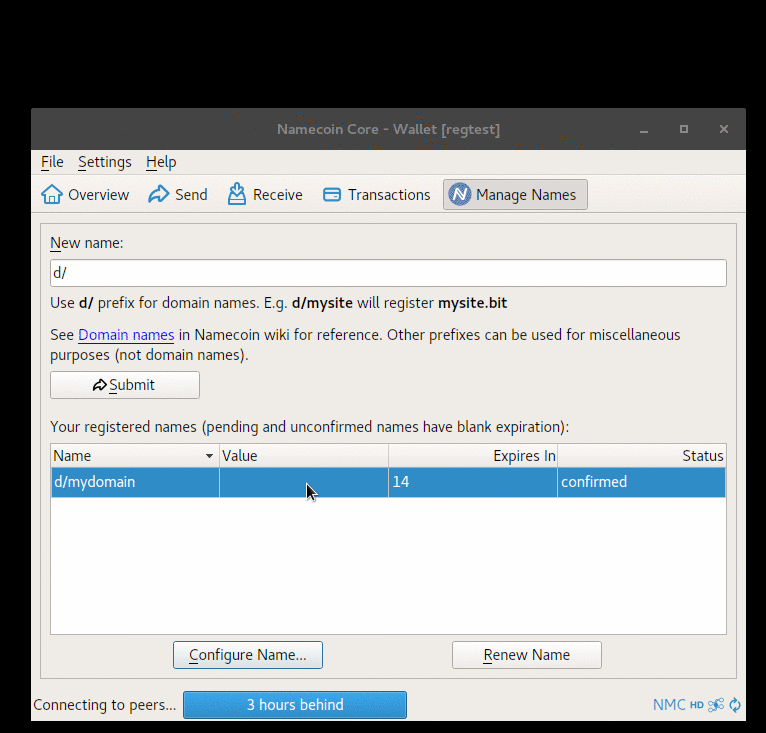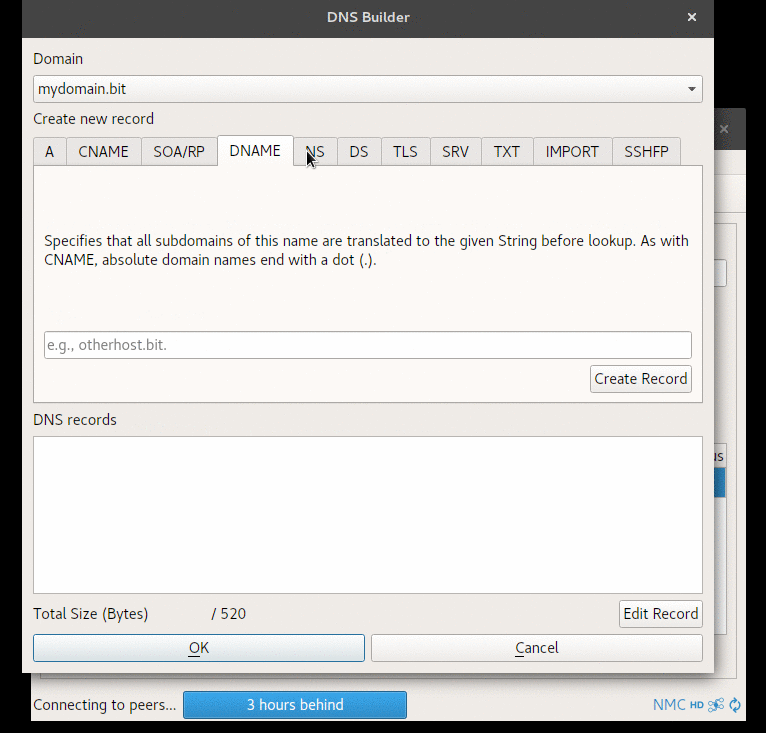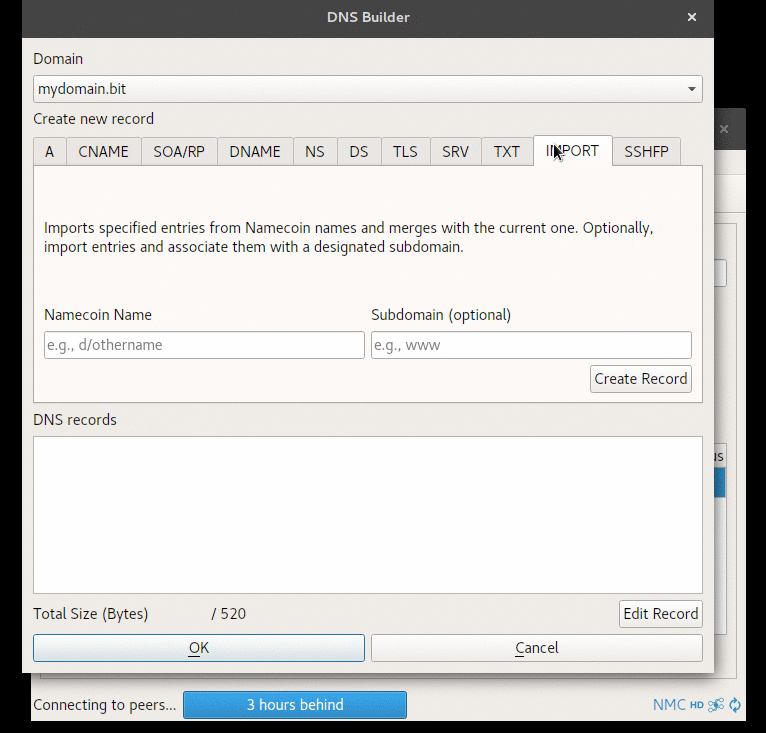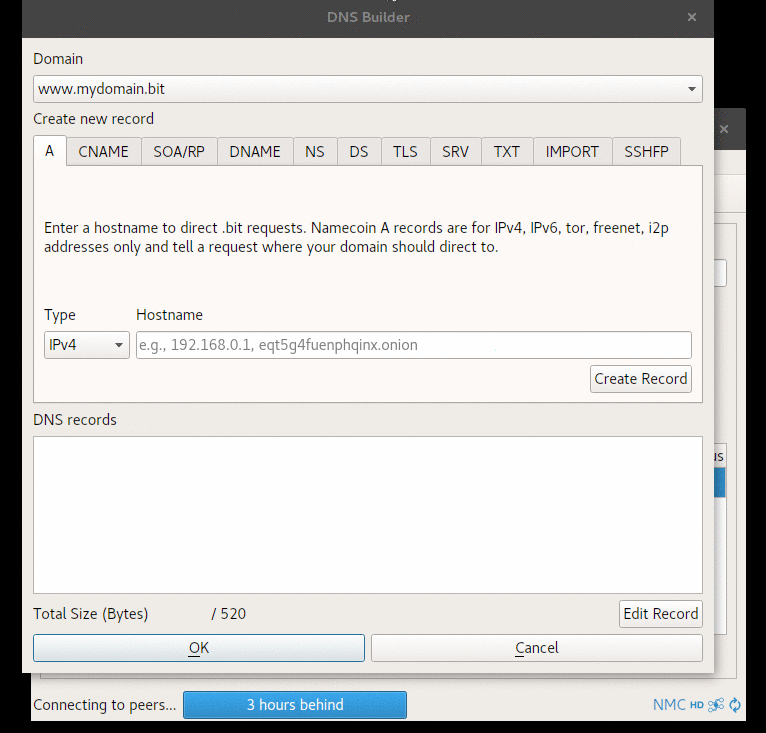
Unfortunately, merging that code to Namecoin Core is blocked by several other tasks, so it may be a while before it makes its way into a Namecoin Core release. However, in the meantime, all is not lost. Thanks to the magic of Qt GUI’s being in XML format, and therefore easy to port between C++ and Python, I’ve been spending some time porting Brandon’s DNS Builder GUI to Electrum-NMC.
Things are still a bit rough around the edges, but it’s beginning to take shape. Check out the below screenshot:
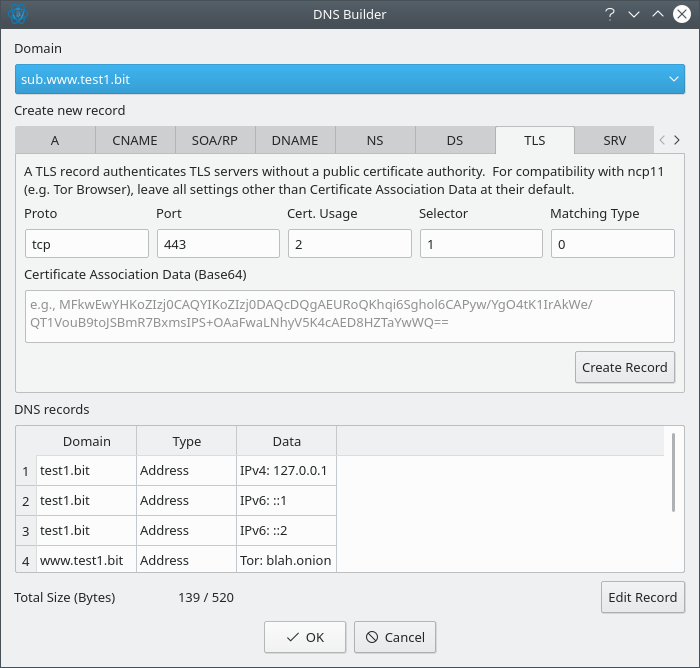
So far, the following features work:
- Creating and parsing the following record types:
- IPv4 addresses
- IPv6 addresses
- Tor onion services
- I2P eepsites
- Freenet freesites
- ZeroNet zites
- NS delegations
- DS fingerprints
- CNAME aliases
- TLS fingerprints
- SSH fingerprints
- TXT records
- SRV records
- Domain data imports
- Parsing subdomains (recursively)
- Creating and sorting subdomains
- Input validation (only verifying that integer fields are valid integers, and no real-time feedback)
- Repairing the deprecated forms of Tor and ZeroNet records
- Size optimizations, e.g. setting
"ip6"to a string instead of an array containing one string
The following features still need implementation:
- Creating and parsing the following record types:
- WHOIS info
- DNAME subtree aliases (not particularly high priority because it’s a footgun)
- Editing existing records (this is partially implemented)
- Deleting existing records
- More input validation (the sharp-eyed among you probably noticed that it allowed me to enter
blah.onionas a Tor onion service despite that string being invalid), with real-time feedback - More friendly guidance for some parameters (e.g. the “Cert. usage”, “Selector”, and “Matching Type” parameters in the TLS tab would probably be more suitable as a drop-down list or combo box)
Hopefully this work will improve the UX so that Namecoin domain owners aren’t expected to handle JSON manually.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Stream Isolation for Namecoin Name Lookups
The documentation for using Namecoin for name lookups with Tor (via ncprop279) includes a warning about stream isolation. Specifically, it states that while TCP connections issued by the application (e.g. Tor Browser) will be stream-isolated as usual, stream isolation will not be applied to whatever network traffic might be induced by the Namecoin lookup. As a result, our documentation recommends against using Electrum-NMC with ncprop279, since Electrum-NMC will produce network traffic on each lookup. Our documentation instead recommends Namecoin Core or ConsensusJ-Namecoin’s leveldbtxcache mode, neither of which produce any network traffic per lookup. However, this situation is non-ideal; Electrum-NMC has some very real advantages, and it’s a shame that we can’t recommend it for this purpose. Can we do better?
For background, stream isolation is a little-known but highly important feature in Tor, which prevents different TCP connections from different activities from sharing a single Tor circuit. Imagine if this weren’t the case. Keith, who runs an exit relay (or wiretaps one) could easily observe that Ed visited a website of a restaurant in Hawaii, and also visited the website of the WikiLeaks submission system. Keith doesn’t need to know who Ed is or what his real IP address is; Keith has learned that someone in Hawaii is likely a WikiLeaks source, which is valuable information. In other words, Ed has only achieved pseudonymity, i.e. his real name and IP address are hidden, but all of his activities are linkable to a single pseudonym. Stream isolation unlinks these activities, so that Keith instead sees that someone accessed a Hawaiian restaurant’s website and also sees that someone accessed WikiLeaks’s submission system, but doesn’t have any idea if they are the same person. Stream isolation enables users to be anonymous rather than pseudonymous.
How does stream isolation work in Tor? Applications can decide which TCP connections can share a circuit without leaking private information, and they communicate this to Tor by setting the SOCKS5 username and password fields. Tor makes sure that any two TCP connections that have different SOCKS5 username+password values will never share a circuit. (Technically I’m oversimplifying here; I’ll come back to this.) So, in order for this to work properly with Namecoin, we need to make sure that the Namecoin software is able to access the SOCKS5 username and password that the application used when talking to Tor, and pass this (or derivative data, see below) through to Tor when Electrum-NMC is doing lookups. In practice, this means that every piece of software in the chain (starting with Tor’s control port, which talks to StemNS, and ending with aiorpcX, which is the library used by Electrum-NMC to open the TCP connections via Tor’s SOCKS port) must be patched to preserve the SOCKS5 username and password that the application used, and pass it through to the next piece of software in the chain.
So, let’s look at how we handled this, starting at the end of the chain and working backwards to the beginning.
aiorpcX
aiorpcX is the network library used by Electrum. It has its own SOCKS5 implementation, which already supports username/password authentication, so you might think there’s nothing to patch here. However, observing Bitcoin Core’s behavior yields a hint for how we can improve aiorpcX.
Bitcoin Core (and, by extension, Namecoin Core) open each peer connection using a random SOCKS5 username and password. The effect is that each peer connection will go over its own Tor circuit. This has several advantages. It improves Sybil-resistance (by making it impossible for a single malicious Tor exit relay to control a Bitcoin node’s view of the blockchain). It also avoids situations where a malicious user gets a Tor exit banned by most of the Bitcoin network, and then other users who end up on that Tor exit can’t connect. These advantages are beneficial even without worrying about privacy specifically.
I submitted a patch to aiorpcX that allows applications to request that a random SOCKS5 username+password be used per connection. This makes things quite a bit cleaner. The patch has been merged by Neil.
Electrum-NMC
Patching Electrum-NMC to use the above aiorpcX feature was fairly straightforward. However, I also needed to add an RPC argument to name_show, so that the caller can specify a “stream isolation ID”, which has a similar role as the SOCKS5 username+password in the Tor SOCKS port. Electrum-NMC executes name_show with a different server connection for each unique stream isolation ID that it is passed.
You may be wondering why we’re not just passing through the stream isolation ID to aiorpcX’s SOCKS5 username; why go through the trouble of randomizing the username and then maintaining a mapping inside Electrum-NMC? The reason is that Electrum-NMC needs to preemptively open server connections before name_show is called. Otherwise, each name lookup would be delayed by an Electrum protocol handshake, which would be an unacceptable latency penalty.
These patches are also useful for non-Namecoin use cases, and accordingly I’ve also sent them upstream to Electrum, where they’re awaiting review.
btcd
btcd is best-known as an alternate implementation of a Bitcoin full node, but it’s also the primary implementation of a Bitcoin RPC client in Go. Up until recently, ncdns used an ancient 2015 fork of btcd to talk to Namecoin Core and Electrum-NMC. This fork dealt with the arguments to name_show. I wasn’t really fond of piling more and more hacks onto an ancient fork, so I looked into what would be needed to use modern btcd with Namecoin. There were only 2 features missing from current btcd that we needed: extensible commands (so that we could add name_show as an RPC method) and cookie authentication (so that the user doesn’t need to set up RPC passwords manually). Both of these were pretty easy to implement, and I’ve sent patches for both to the btcd developers. They’re both undergoing review.
With that out of the way, I was able to get the Namecoin name_show command working with current btcd (I’m currently maintaining a fork of btcd until the above 2 patches are merged), via the new ncbtcjson and ncrpcclient packages. These packages now support passing a stream isolation ID to Namecoin Core and Electrum-NMC. (Namecoin Core ignores it, since it doesn’t generate any network traffic per lookup.)
I also needed to hack Electrum-NMC a bit to make the new btcd’s stream isolation ID argument work with it. This is because Electrum, by convention, expects optional arguments to be passed in a slightly different way than Bitcoin Core, and since the stream isolation ID is an optional argument, I needed to rig Electrum-NMC to also recognize the Namecoin Core style.
ncdns
Rewriting ncdns’s integration with btcd was quite enjoyable, because modern btcd is much simpler to use than the ancient 2015 fork we were using previously. This meant that I got to rip out quite a lot of code that was no longer needed. Adding a stream isolation ID argument to ncdns’s lookup code that gets passed through to btcd was pretty easy, but there’s another important thing that was necessary. ncdns caches responses for performance reasons, and it’s important to isolate the cache based on the stream isolation ID. So, now ncdns creates a new cache for each new stream isolation ID that it sees.
madns
madns is the authoritative DNS library that ncdns uses. Even though ncprop279 doesn’t include a DNS server, it uses madns to handle various DNS protocol functionality (e.g. wildcard domains) that one would expect a naming system to handle. Making madns pass a stream isolation ID to ncdns was pretty easy (though it required breaking the madns stable API). But where would madns get the stream isolation ID from, since usually it receives requests via the DNS wire protocol?
The solution Hugo and I found was to use EDNS0, which is a protocol extension mechanism in the DNS wire protocol. I created an EDNS0 extension that allows DNS clients to specify a stream isolation ID; madns then passes it to ncdns.
This has other interesting implications. For example, a method of supporting stream isolation in the DNS wire protocol would be interesting to explore for the Tor DNS port, as well as Unbound and other locally-run DNS servers.
ncprop279
Modifying ncprop279 to pass a stream isolation ID to madns via EDNS0 was straightforward. I also had to modify the Prop279 protocol a bit so that ncprop279 knows what stream isolation ID to use. This was pretty easy.
StemNS
Making StemNS pass a stream isolation ID to ncprop279 was pretty easy. But how to calculate the stream isolation ID? Alas, simply using the SOCKS5 username+password wasn’t going to fly. Remember how I said I was oversimplifying how Tor decides which connections to isolate? In reality, there are a variety of different data fields associated with a connection made through Tor besides the SOCKS5 username/password. Other fields that are relevant include the source IP (useful if you have multiple VM’s that access a common Tor instance and you want each VM to be stream-isolated) and the destination IP/port (useful if you have an application that talks to multiple servers via Tor’s Trans port and you want each server to be stream-isolated). Additionally, Tor can be configured to enable or disable stream isolation for each of these fields independently. And did I mention that Tor can run multiple listener ports, and each of these ports can have independent stream isolation settings?
Trying to reliably compress this data into some kind of hash that we could use as a stream isolation ID seemed error-prone, so I instead copied Nick Mathewson’s English description of the logic that Tor itself uses to decide whether two given Tor streams can go over the same circuit, and I made StemNS store the relevant raw data. StemNS deletes this data every time Tor cycles to a new identity (typically every 10 minutes, though this can vary by settings, and also happens immediately if the user clicks the New Identity button), so it shouldn’t eat up too much memory. Whenever StemNS finds that a newly requested stream isn’t compatible with any of the streams previously assigned to a stream isolation ID, it makes up a new stream isolation ID and assigns the stream to that one. Not too bad.
Tor
StemNS talks to Tor via the control port protocol. Unfortunately, quite a few of the relevant fields (including the SOCKS username/password) weren’t actually available via the control port’s STREAM event, which is the event we need to hook in order to do name resolution. The control port does make the SOCKS username/password available via other events, but those events don’t fire until it’s too late to do name resolution.
So I ended up patching Tor to make all of those fields available over the control port. Because the control port protocol follows a spec, that also meant patching the spec. After a few revisions of the spec and code as per review, Nick from Tor merged my patches. Nightly builds of Tor now support the necessary control port features for StemNS to handle stream isolation properly.
Conclusion
Getting this implemented across the stack was an interesting and nontrivial endeavor, due to the large number of codebases involved, many of which involve third parties. But I think it was worth it. New release tags of the relevant codebases will hopefully be coming soon, which means we’ll finally be able to get rid of the scary warning against using Electrum-NMC with ncprop279. Considering that Electrum-NMC syncs by far the quickest of any Namecoin name lookup client, which is a big deal given Tor’s bandwidth constraints, this is a major UX win.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
DNSSEC-HSTS v0.0.2 for Google Chrome Released
We’ve released DNSSEC-HSTS v0.0.2 for Google Chrome. v0.0.2 is identical to v0.0.1 except for Chrome-related compatibility fixes; we are therefore not releasing v0.0.2 binaries for Firefox.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Building Electrum in rbm
As I’ve discussed before, Namecoin is using Tor’s rbm-based build system for our various Go projects, such as ncdns and ncp11, in order to reduce the risk of supply-chain attacks. I’m now looking into building Electrum in rbm as well. Upstream Electrum’s Python tarball binaries aren’t reproducible at all, and their Windows binaries’ reproducible builds are heavily dependent on sketchy dependencies that I’d prefer not to trust. rbm offers a potential solution.
At this time, I’ve successfully gotten rbm to build an Electrum-NMC Python tarball that behaves pretty much the same as the standard build method (including the dependency bundling) – except that it should be substantially more reproducible. The only two components that aren’t being built by my rbm descriptor are the Protobuf definition for the Payment Protocol (should be fixable easily, since I’m already building the Protobuf compiler) and the locales folder (hopefully easy to handle, I just haven’t looked at it yet).
Building the Windows binaries in rbm is something I intend to look into later, though it’s not at the top of my priority queue. Obviously, the intent is to contribute all of this work upstream to Electrum.
This work was funded by Cyphrs.
Electrum-NMC v3.3.8 Released
We’ve released Electrum-NMC v3.3.8. This release includes a large number of improvements, mostly focused on performance (both initial syncup speed and name lookup latency) and anonymity (in particular support for Tor stream isolation). Here’s what’s new since v3.3.7:
- From upstream Electrum:
- fix some bugs with recent bump fee (RBF) improvements (#5483, #5502)
- fix #5491: watch-only wallets could not bump fee in some cases
- appimage: URLs could not be opened on some desktop environments (#5425)
- faster tx signing for segwit inputs for really large txns (#5494)
- A few other minor bugfixes and usability improvements.
- Namecoin-specific:
- Fix signature creation for P2SH and SegWit names (Namecoin mainnet now supports P2SH and SegWit; these features should now work in Electrum-NMC, including in name transactions). (Patch by Daniel Kraft.)
- Fix an error that occurred when displaying the Manage Names tab if the blockchain is empty but the wallet is not. (Patch by Jeremy Rand.)
- Merkle checkpoints (improves initial syncup speed). (Patch by Jeremy Rand; based on a patch by Roger Taylor.)
- Create a
.tar.xzarchive (improves binary download size). (Patch by Jeremy Rand.) - Use random SOCKS authentication for stream isolation of connections to servers (improves performance and anonymity). (Patch by Jeremy Rand.)
- Add
stream_idargument to network RPC methods for stream isolation (improves performance and anonymity). (Patch by Jeremy Rand.) - Building Electrum-NMC without wallet functionality, GUI functionality, and BIP70 functionality is now supported (improves binary download size). (Patch by Jeremy Rand.)
- Support a Namecoin-Core-style
optionsargument inname_showRPC method (fixes compatibility with latest ncdns). (Patch by Jeremy Rand.) - Retry name lookups with different server if NXDOMAIN returned (improves censorship resistance). (Patch by Jeremy Rand.)
- Download blockchain from different servers in parallel (improves initial syncup speed). (Patch by Jeremy Rand.)
- Add
from_coinsargument to wallet RPC methods (improves anonymity). (Patch by Jeremy Rand.) - Avoid returning outdated
name_showresults while the blockchain is still syncing (improves security of key revocations). (Patch by Jeremy Rand.) - Avoid broadcasting
name_newifname_firstupdatefailed (improves reliability of name registration). (Bug reported by DogHunter; patch by Jeremy Rand.) - Avoid
NotEnoughFundserror in CoinChooser if zero buckets are sufficient (fixes a spurious error during name registration). (Bug reported by DogHunter; patch by Jeremy Rand.) - Code quality improvements. (Patches by Daniel Kraft and Jeremy Rand.)
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Namecoin will be at Oklahoma City Fall Peace Festival 2019
Namecoin will have a table at the Oklahoma City Fall Peace Festival 2019. The festival is Saturday, November 9, 2019, 10 AM - 4 PM, in the Downtown Civic Center Hall of Mirrors. If you happen to be near the Oklahoma City area, feel free to come by and say hello. I might even have some cool demos of upcoming features.
Matching tor-browser-build Conventions in ncdns-repro
As I’ve discussed before, Namecoin is using Tor’s rbm-based build system for our various Go projects, such as ncdns and ncp11, in order to reduce the risk of supply-chain attacks. Namecoin’s relevant Git repository, ncdns-repro, is heavily based on a Tor repo, tor-browser-build. As we gained more experience with using rbm, it became more clear that even trivial deviations from upstream tor-browser-build can cause interoperability headaches. So, I’ve been bringing ncdns-repro more in line with tor-browser-build conventions. In particular, two noticeable changes have been made.
First off, rbm divides the build scripts into “projects”. For example, in Tor Browser, OpenSSL is a project, as is Tor, as is Firefox, as is GCC, etc. Projects can depend on each other (for example, Tor depends on OpenSSL, and OpenSSL, Tor, and Firefox all depend on GCC). When ncdns-repro was initially created, we didn’t really think much about the project names, and on a whim decided to the projects written in Go names that reflected their full package path. For example, the Go package golang.org/x/crypto was given an rbm project name of golang.org,x,crypto in ncdns-repro. In contrast, upstream tor-browser-build gives their Go-based projects abbreviated names, e.g. the aforementioned package was given an rbm project name of goxcrypto [1]. Unfortunately, we figured out via experience that this causes problems, especially when ncdns-repro pulls in data from tor-browser-build (or vice versa) as a Git submodule, because it means that if a project from one repo wants to pull in a project from another repo as a dependency, the project names will be inconsistent.
Second, ncdns-repro stored all of the Git hashes for its projects in a root-directory-level file called hashlist, whereas upstream tor-browser-build stores them in the configuration file in each project’s directory. The intent on our end was to make it easier to enumerate all of the Git hashes, but again, experience showed that this causes problems when Git submodules are used to let tor-browser-build and ncdns-repro share configuration data.
As of now, ncdns-repro uses the same project naming conventions as tor-browser-build, and no longer uses a hashlist file. This should improve interoperability of ncdns-repro with tor-browser-build going forward.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
[1] Insert snarky reference to Mark Karpeles here.
Porting DNSSEC-HSTS to Chrome
As was discussed in my 35C3 slides, DNSSEC-HSTS is a WebExtension that prevents sslstrip attacks by using DNSSEC. DNSSEC-HSTS is already available for Firefox, but (as a WebExtension) it should be easily portable to Chrome. Not so fast: Chrome has a number of quirks that make this nontrivial.
First off, Chrome doesn’t support asynchronous blocking WebRequest, which is a feature that DNSSEC-HSTS uses in order to retrieve DNS data from a native application. I was able to work around this by converting the native messaging code used in the Firefox version into a standard HTTP request for Chrome. HTTP is substantially less secure than native messaging, but since the Chrome developers don’t seem to have any interest in security, we have to accept the reality that Chrome users will have less security than Firefox users.
Second, Chrome doesn’t support SVG images as extension logos, which was causing Chrome to reject the DNSSEC-HSTS extension. This was quite trivial to work around, since the Namecoin logo is also available as a PNG image.
Third, Chrome doesn’t support loading unpacked extensions from the system. (Chromium, as packaged by many GNU/Linux distros, does support this, but Google’s binaries do not.) I was able to work around this by packaging DNSSEC-HSTS as a CRX file. Unfortunately, I’m not aware of any existing tools for supporting detached signatures for CRX files, which means that the CRX version of DNSSEC-HSTS will probably not be possible to build reproducibly. This is unfortunate, but again, we have to accept the reality that the Chrome developers simply don’t care about security, so Chrome users are going to have less security than Firefox users.
With these changes, DNSSEC-HSTS appears to work on Chrome; the changes will be included in the next release.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC v3.3.7 Released
We’ve released Electrum-NMC v3.3.7. Here’s what’s new since v3.3.6.1:
- From upstream Electrum:
- The AppImage Linux x86_64 binary and the Windows setup.exe (so now all Windows binaries) are now built reproducibly.
- Bump fee (RBF) improvements: Implemented a new fee-bump strategy that can add new inputs, so now any tx can be fee-bumped (d0a4366). The old strategy was to decrease the value of outputs (starting with change). We will now try the new strategy first, and only use the old as a fallback (needed e.g. when spending “Max”).
- CoinChooser improvements:
- more likely to construct txs without change (when possible)
- less likely to construct txs with really small change (e864fa5)
- will now only spend negative effective value coins when beneficial for privacy (cb69aa8)
- fix long-standing bug that broke wallets with >65k addresses (#5366)
- Windows binaries: we now build the PyInstaller boot loader ourselves, as this seems to reduce anti-virus false positives (1d0f679)
- Android: (fix) BIP70 payment requests could not be paid (#5376)
- Android: allow copy-pasting partial transactions from/to clipboard
- Fix a performance regression for large wallets (c6a54f0)
- Qt: fix some high DPI issues related to text fields (37809be)
- Trezor:
- allow bypassing “too old firmware” error (#5391)
- use only the Bridge to scan devices if it is available (#5420)
- hw wallets: (known issue) on Win10-1903, some hw devices (that also have U2F functionality) can only be detected with Administrator privileges. (see #5420 and #5437) A workaround is to run as Admin, or for Trezor to install the Bridge.
- Several other minor bugfixes and usability improvements.
- Namecoin-specific:
- Fix issue affecting plugin detection. If you were encountering hardware wallet bugs, they might be fixed now.
- Various rebranding fixes.
- Various code quality improvements.
As usual, you can download it at the Beta Downloads page.
This work was funded by Cyphrs.
Fixing a gzip Reproducibility Bug in Tor Browser and rbm
As I’ve discussed before, Namecoin is using Tor’s rbm-based build system for our various Go projects, such as ncdns and ncp11, in order to reduce the risk of supply-chain attacks. Naturally, one of the important ways to test a reproducible build system is to build a binary twice in a row and see if the hashes are the same. If the hashes don’t match, then tools like Diffoscope can be used to figure out what the source of the reproducibility failure is. Now that Namecoin’s usage of rbm is reasonably stable (i.e. working binaries are produced for most of Namecoin’s software now), it’s a good time to look into how reproducible our binaries are.
So, I tried building ncdns twice to see if I got matching hashes. Alas, the hashes did not match. Plugging the results into Diffoscope yielded the information that the files within the .tar.gz archive were indeed identical, but that the time value embedded in the gzip header was nonreproducible. Given that this didn’t seem like anything I had screwed up on my end, I tried building a .tar.gz binary from upstream Tor Browser. Same issue: nonreproducible binaries due to gzip header time values.
I also observed that .tar.xz binaries weren’t affected by the issue. This would explain why upstream Tor hadn’t noticed or fixed the bug on their end – all of their end-user binaries are .tar.xz; .tar.gz is only used by Tor for intermediate binaries, which probably aren’t tested for reproducibility as thoroughly. Obviously, Namecoin could work around the issue by switching to .tar.xz for end-user binaries (I was planning to do this anyway since .tar.xz archives have much better compression), but since Namecoin likes to be a good neighbor, I figured it was a good idea to report the bug upstream to Tor.
After some discussion with Nicolas from Tor (lead developer of rbm), we converged on a 2-line patch to rbm that should resolve the issue. Once this patch is merged upstream, Namecoin binaries will be substantially closer to reproducibility, and as a bonus, the intermediate binaries produced by Tor will probably be reproducible too.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
ncdns v0.0.9.2 Released
We’ve released ncdns v0.0.9.2. List of changes in v0.0.9.2:
- All platforms:
- New build system based on The Tor Project’s rbm. This paves the way for reproducible builds.
- Add an optional mode to
generate_nmc_certthat creates a name-constrained CA cert instead of an end-entity cert. This mode is required for Tor Browser TLS support. - Add “URL list” output format to
ncdumpzone. This paves the way for a decentralized search engine for Namecoin websites. - Make Namecoin RPC timeout configurable. This improves compatibility with Tor Browser.
- Move
x509to its own repo. This improves compatibility with Tor Browser.
- Windows:
- Automatically re-run
tlsrestrictnsswhen NSS is updated; this improves TLS support for Firefox. - Upgrade dnssec-keygen to v9.13.3.
- Automatically re-run
- New projects:
- DNSSEC-HSTS v0.0.1: A WebExtension that prevents sslstrip attacks for Namecoin websites that support TLS. See my 35C3 slides for more details.
- ncp11 v0.0.1: Enables Namecoin TLS in browsers that support PKCS#11, such as Tor Browser. See my 35C3 slides for more details.
- ncprop279 v0.0.1: Enables Namecoin resolution in Tor; somewhat smaller and more efficient than dns-prop279.
- Code quality improvements.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Killing Namecoin’s Fork of Conformal’s btcd
One of the lesser-known dirty secrets of the ncdns codebase [1] is that it relies on an unmaintained fork of Conformal’s btcd, which dates back to 2015. Specifically, ncdns uses a fork of the JSON-RPC client from btcd in order to query Namecoin Core, ConsensusJ-Namecoin, or Electrum-NMC. Why did Namecoin not find upstream btcd to be sufficient?
- btcd’s RPC client expected a modern Bitcoin Core codebase to be used, and in 2015 Namecoin was somewhat behind upstream Bitcoin Core. Thus Hugo needed to add a patch to avoid compatibility issues.
- btcd’s RPC client expected JSON-RPC 1.0 to be used, and errored when it encountered JSON-RPC 2.0. Both ConsensusJ-Namecoin and Electrum-NMC use JSON-RPC 2.0, so I had to add a patch to avoid that error.
- btcd’s RPC client didn’t support cookie authentication, and Namecoin Core is easiest to set up when cookie authentication is in use. Thus Hugo had to implement cookie authentication.
To make matters more complicated, Conformal decided to rewrite btcd’s JSON-RPC client from scratch a few months after Namecoin forked it; the rewrite has a completely different API, so it wasn’t a drop-in replacement. This was yet further complicated by the fact that one of the features in the original btcd JSON-RPC client’s API allowed adding custom RPC methods for altcoins (e.g. name_show and name_scan), which ncdns relied on; the rewrite’s API doesn’t expose that functionality nearly as cleanly.
We’ve been throwing around the idea of using upstream Conformal’s btcd package for a while, but finally I decided to start implementing it. Happily, Conformal includes example code for using the new API, so it wasn’t hard to get it to talk to Namecoin Core. I submitted a patch to Conformal that exposes the API features needed for custom RPC methods (the patch was pretty easy to write, and hopefully will be merged soon). I also implemented name_show and name_scan for btcd. (ncdns also includes support for name_filter and name_sync, but these methods weren’t actually used for anything and aren’t even included in current Namecoin Core releases, so I didn’t bother implementing them.) Happily, issues (1) and (2) are no longer relevant, because ancient versions of Namecoin Core have long ago been phased out, and upstream btcd now supports JSON-RPC 2.0 without erroring. Conveniently, the new API looks very similar to a custom high-level API that ncdns had implemented itself, so I was able to kill off quite a lot of glue code in ncdns as well.
Finally, I ported Hugo’s cookie authentication code to btcd. This wasn’t particularly difficult, since most of the relevant code could be copied from ncdns into btcd without major changes. (ncdns is GPLv3+-licensed, while btcd is ISC-licensed, but Hugo is the only developer who’s touched the relevant code, and he’s authorized re-licensing that code to both MIT and ISC licenses, so licensing concerns aren’t an issue.)
Killing off the legacy Namecoin fork of btcd will be an important step toward making Namecoin more secure, since unmaintained code is a potential source of bugs and vulnerabilities. It also means we’ll benefit from whatever features Conformal has added since 2015, and whatever features they add in the future. Now we just wait for Conformal to review the patches.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Of course, nothing is really secret in the ncdns codebase, since it’s free software. That said, it’s rare for people to actually thoroughly check the dependency tree of free software they work with, which makes it a bit of a de facto secret.
Decoupling ncdns Versions from Go Compiler Versions
One of the many pieces of witchcraft that Namecoin’s TLS interoperability requires is the ability to splice a signature into an X.509 certificate without otherwise modifying the certificate. Unfortunately, while the Go standard crypto library is generally quite pleasant to use (and is certainly better-designed than most other crypto libraries such as OpenSSL), the functions relevant to splicing a signature are not exported. This is understandable, since it’s not functionality that most users have any need for. However, since Namecoin does need that functionality, my only option back when this code was being written was to fork the crypto/x509 package from Go’s standard library.
I didn’t want to be responsible for maintaining or distributing a fork of Go’s library, though. So, the best option I could come up with was to use go generate, which is a fun feature in Go’s build system. In Namecoin’s case, the ncdns build process uses go generate to copy the source code from the official crypto/x509 package into the github.com/namecoin/ncdns/x509 package, which (when combined with the single existing source code file, x509_splice.go), produces a package that’s identical to upstream crypto/x509 but with an extra exported function (CreateCertificateWithSplicedSignature) that calls out to the unexported upstream functions in order to do what we want. The benefit here is that whenever those unexported upstream functions are updated in a new Go release, Namecoin’s forked package will automatically inherit those changes without the Namecoin developers needing to do anything. In fact, in theory the same forked package will work unmodified with arbitrary versions of the Go standard library, without us needing to do anything special.
Alas, theory does not always equal practice. The most obvious scenario in which this theory will fall apart is if the unexported functions called by CreateCertificateWithSplicedSignature change their API. Upstream is well within their rights to do this, of course: they’re not exported functions, so there’s no reason to expect a stable API. However, in practice, this API changes quite rarely. The more common issue I’ve been encountering, surprisingly, is that the go generate script has trouble finding and copying the upstream library, because upstream seems to keep changing the details of where this library and its dependencies (some of which are internal-only libraries) can be found. The result is that I’ve had to rebase our fork against upstream every couple of major Go releases to keep things working well.
The problem here is that this has the effect of coupling a specific commit hash of the ncdns repository to a specific range of Go compiler versions. If Namecoin rebases against a new Go standard library version, and then issues an ncdns bug fix that’s unrelated to our x509 fork, everyone who’s downstream of us needs to update their Go compiler in order to get the bug fix. This is generally problematic since lots of downstream distributors have other considerations for when they update their compiler. It was specifically causing me problems for getting ncdns to build in Tor’s rbm-based build system, because Tor is not likely to update their Go compiler exactly when Namecoin does.
So, what to do? Well, note that there’s no fundamentally important reason for the x509 package to be a subpackage of ncdns. It ended up there by default because it was initially only used by ncdns and there wasn’t an obvious reason to create a new Git repo, but now we have a good reason to move it to its own repo: if the Git commit hash of ncdns and x509 are independent, then downstream distributors can pick the version of ncdns with whatever bug fixes they want, and independently choose the version of x509 that supports whatever Go compiler version they want. I’ve now done this. x509 now lives at github.com/namecoin/x509-signature-splice/x509 , and branches are available for every version of the Go compiler that we’ve ever supported, ranging from Go 1.5.x all the way through Go 1.13.x. (Note that the Go 1.12.x and Go 1.13.x support is new, as both of those Go releases required rebases in order for go generate to run without errors. So if you use one of those Go versions, you’ll find this work especially useful.)
The two final steps here are:
- Removing
x509from the ncdns repo and switching over to the new repo; this has now been merged. - Updating ncdns-repro to use the new ncdns version; this will happen soon.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
OpenNIC does the right thing: listens to security concerns and shuts down its centralized Namecoin inproxy
In September 2018, I published a case study about centralized inproxies and how they can cause security dangers even to competent users who think they’re using a decentralized system. Although my article wasn’t targeted at any particular entity (like all case studies, it uses a specific entity to make generalizations about a wider field), the case study used OpenNIC’s inproxy as an example. (The fact that OpenNIC ended up as the example isn’t due to any fault of OpenNIC, it’s simply that the sysadmin mentioned in the case study happened to be an OpenNIC user.) In December 2018, PRISM Break maintainer Yana Teras (who is a friend of Namecoin) independently raised similar security concerns about OpenNIC’s Namecoin inproxy, commenting in PRISM Break’s Matrix channel “i’m not too happy we recommend dns servers that resolve .bit for users, it seems to be nearly as much helpful as resolving .onion” and subsequently proposing that PRISM Break avoid recommending DNS services that include that kind of functionality.
Guess what? OpenNIC listened to the concerns of Yana and myself, and has decided to shut down their centralized Namecoin inproxy. This was probably not an easy decision, as OpenNIC’s Namecoin inproxy had been a significant usage draw for OpenNIC, and it is likely that a significant portion of OpenNIC users (who were using OpenNIC solely for its Namecoin inproxy) will move to decentralized methods and leave OpenNIC’s other TLD’s behind. Most corporate actors probably wouldn’t have done this. But it was the right decision.
I’d like to thank OpenNIC for taking Yana’s and my concerns seriously. I regularly recommend OpenNIC (the non-.bit TLD’s) to users who don’t need Namecoin’s security model but who want a regulatory environment that isn’t subject to ICANN policies; I will continue to do so. If you happen to hang around the OpenNIC community, I encourage you to thank OpenNIC for this decision as well.
This news post was intended to be posted near the beginning of July 2019, but was delayed because I was busy attending the Tor developer meeting in Stockholm. I apologize for the delay.
Namecoin Core 0.18.0 Released, Softfork Incoming at Mainnet Block Height 475,000
Namecoin Core 0.18.0 has been released on the Downloads page. This release schedules a softfork for block height 475,000 on mainnet. Contained in the softfork are:
- P2SH
- CSV
- SegWit
All three of these softfork components are already active in Bitcoin, and should be uncontroversial. We had originally discussed lowering the block weight limit as part of this softfork, but we decided to defer block weight discussion for a later date, as the extra review procedures involved in changing the block weight limit would have delayed the release, and we wanted to get the softfork activated as soon as feasible. So, for this softfork, the block weight limit is the same as that of Bitcoin.
Due to the softfork, we strongly recommend that miners, exchanges, registrars, explorers, ElectrumX servers, and all other service providers upgrade as soon as possible. End users who do not need the name management GUI are also strongly encouraged to upgrade.
At this time, the estimated activation date of the softfork is 82 days from now. However, this may vary depending on hashrate fluctuations, so do not wait until the last minute to upgrade.
See #239 for more details on the softfork.
Also included in this release:
- Windows binaries are available again.
- The
optionsargument forname_new,name_firstupdateandname_updatecan now be used to specify per-RPC encodings for names and values by setting thenameEncodingandvalueEncodingfields, respectively. name_scannow accepts an optionaloptionsargument, which can be used to specify filtering conditions (based on number of confirmations, prefix and regexp matches of a name). See #237 for more details.name_filterhas been removed. Instead,name_scanwith the newly added filtering options can be used.ismineis no longer added to RPC results if no wallet is associated to an RPC call.- Numerous improvements from upstream Bitcoin Core.
ncp11 Now Works in Tor Browser for Windows
ncp11 is now working (both positive and negative TLS certificate overrides) in Tor Browser for Windows. It turned out that the only things keeping it from working properly once it built without errors were a couple of GNU/Linux-specific file path assumptions, both of which were quite easy to fix.
Actually testing it was mildly tricky, due to the fact that I was trying to use StemNS (a fork I made of meejah’s TorNS tool) for the DNS resolution in Tor Browser, and it turns out that there was a bug in both upstream TorNS and StemNS that caused the Prop279 implementation to launch with an empty set of environment variables. In GNU/Linux, this is harmless, but (surprise, surprise) in Windows this causes a variety of horrible effects, chief among which is that cryptographic software will be unable to generate random numbers and thus will crash. I was going to find that out anyway once the Tor community started messing with StemNS, so probably a good thing that I found it early. (I wish it hadn’t taken me quite so long to figure out why things were crashing, but alas, that’s life.) StemNS now has a fix for that bug, and I’ve submitted a fix upstream to TorNS as well.
So, my estimate of what remains before we can release Tor Browser TLS support:
- Get the remaining PR’s merged to the relevant repos (in particular, ncdns-repro has a few pending PR’s that are needed for this).
- Tag a release and build/upload binaries.
- Write some documentation (should be easy to adapt from the 35C3 workshop notes).
Meanwhile, I also tried ncp11 in Firefox for Windows (same installation method as in Tor Browser), and ran into some severe trouble there. As far as I can tell, the ncp11 library is failing very early in the boot process: it doesn’t even get as far as running the init() functions in the Go code. Firefox gives a relatively useless “library failure” error, which is presumably a different code path from the “library failure” error that I’m getting in Debian when loading ncp11 into Firefox via a totally different installation method from the Tor Browser method.
Inspecting Mozilla’s CKBI library and ncp11 with the file commmand yielded 2 noticeable differences in file format:
- CKBI’s PE metadata is set to use the GUI subsystem, while ncp11 is set to use the console subsystem.
- CKBI isn’t stripped, while ncp11 is stripped.
Difference 1 was ruled out by switching ncp11’s PE metadata to use the GUI subsystem; it didn’t help. Difference 2 is certainly a possible explanation, and I’ll spend some time later checking what happens if ncp11 isn’t built with the -s linker flag. That said, I suspect that the best way to figure out what’s going wrong is to patch in some debug output to Firefox and NSS so that I can figure out what code path the “library failure” error is happening in.
However, as curious as I am to see what’s failing in Firefox, it should be noted that ncp11’s current funding from NLnet is contingent on Tor Browser support, not Firefox support, which means that I’m unlikely to spend a lot of time debugging the Firefox failure in the near future (especially since the “TLS for Tor Browser” milestone for NLnet has already gone severely over-budget due to the unexpectedly large amount of R&D needed to produce ncp11). I’ll probably resume the Firefox debugging after we’ve secured more funding for this effort.
In the meantime, Namecoin TLS support for Tor Browser is likely to be released very soon. Yay!
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ncp11 Now Builds for Windows Targets
ncp11 (our next-gen Namecoin TLS interoperability software for Firefox, Tor Browser, and other NSS-based software) now builds without errors for Windows targets, including rbm descriptors. Getting it to build was a little bit more involved than just tweaking the rbm end of things, because the PKCS#11 spec requires that structs be packed on Windows, while Go doesn’t support packed structs. So, some minor hackery was needed (I wrote a C function that converts between packed and unpacked structs). Kudos to Miek Gieben (author of the Go pkcs11 package) for his useful sample code, which made this fix quite easy to code up.
Meanwhile, qlib (our Go library for DNS queries, based on Miek’s q command-line tool) has also been fixed to build in rbm for Windows targets. This was just a matter of fixing some sloppiness that snuck into the rbm descriptors, which happened to not be causing any problems on GNU/Linux targets due to dumb luck. All of our rbm projects that depend on qlib (specifically, certdehydrate-dane-rest-api and dnssec-hsts-native) also now build for Windows targets.
It should be noted that ncp11 probably doesn’t actually work as intended on Windows and macOS targets yet. I already fixed a couple of GNU/Linux-specific assumptions in ncp11’s codebase yesterday, and there are likely to be more that will need fixing before ncp11 will actually be usable on Windows and macOS targets. Presumably these will be teased out with further testing.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
More rbm Projects Added: DNSSEC-HSTS, certdehydrate-dane-rest-api, Dependencies, and macOS Support
A few days ago I mentioned that ncp11 now builds in rbm. As you may recall, rbm is the build system used by Tor Browser; it facilitates reproducible builds, which improves the security of the build process against supply-chain attacks. I’ve now added several new projects/targets to Namecoin’s rbm descriptors:
- DNSSEC-HSTS now builds. For those of you who aren’t familiar with DNSSEC-HSTS, see my 35C3 slides.
- certdehydrate-dane-rest-api now builds. This is a backend tool that’s used by both ncp11 and DNSSEC-HSTS.
- Dependencies of the above, including:
- qlib (a library for flexible DNS queries, based on Miek Gieben’s excellent q CLI tool).
- crosssign (a library for cross-signing X.509 certificates).
- safetlsa (a library for converting DNS TLSA records into certificates that are safe to import into a TLS trust store, using dehydrated certificates and name constraints).
- ncdns can now be built as a library, not just as an executable. This was needed in order to build certdehydrate-dane-rest-api.
- ncdns now builds for macOS.
- Several library dependencies were updated; this fixes a number of bugs that existed due to accidentally using outdated dependencies. (Chief among them was a bug that broke ncdns’s ability to talk to ConsensusJ-Namecoin and Electrum-NMC.) Thanks to grringo for catching this.
I’ve also submitted a patch to upstream Tor that will hopefully allow us to make our rbm descriptors a lot cleaner. Specifically, upstream Tor has a special template for building Go libraries, but it doesn’t work for Go executables, so Go executable projects need to have a bunch of boilerplate. My patch allows the Go library template to work with executable projects as well. That patch is currently awaiting review.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ncp11 Now Builds in rbm for GNU/Linux (64-bit and 32-bit)
ncp11 is the next-gen Namecoin TLS interoperability project that Aerth and I have been cooking up in the Namecoin R&D lab for a while. (See my 35C3 slides and workshop notes for more info on it if you haven’t heard about it yet.) Last month, I mentioned that I intended to get ncp11 building in rbm. I now have ncp11 building in rbm for GNU/Linux 64-bit and 32-bit x86 targets. 32-bit support involved fixing a bug in ncdns’s usage of PKCS#11 (specifically, ncp11 was making type assumptions that are only valid on 64-bit targets, which produced a build error on 32-bit targets). I’ve tested the resulting 64-bit binary in a Debian Buster VM, and it works fine when used as a drop-in replacement for NSS’s CKBI library. (It looks like there are issues when loaded alongside CKBI, which I’ll need to debug when I have some free time, but this isn’t a release blocker, and the same issues are reproducible with the non-rbm binary I used at 35C3.)
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Tor Browser 8.5 Released; Includes Namecoin’s certutil Windows/macOS Patch
The Tor Project has released Tor Browser 8.5. Among the usual interesting changes, Namecoin users will be interested to note that Tor Browser 8.5 includes Namecoin’s certutil Windows/macOS patch, which paves the way for better Namecoin TLS support in Firefox on Windows and macOS. For the #reckless among you who want to experiment, the certutil binaries are available here (or here for those of you who can’t access onion services); specifically you want the mar-tools downloads. Kudos to The Tor Project on getting Tor Browser 8.5 released!
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC v3.3.6.1 Released
We’ve released Electrum-NMC v3.3.6.1. This release includes a fix for a PyInstaller build script issue that was introduced in v3.3.6, which unfortunately slipped by us until a few minutes after v3.3.6 was released. The only binaries affected by that issue were the Windows-specific binaries; users of the v3.3.6 Python, GNU/Linux, and Android binaries are unaffected.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Electrum-NMC v3.3.6 Released
We’ve released Electrum-NMC v3.3.6. This release includes important security fixes, and we recommend that all users upgrade. Here’s what’s new since v3.3.3.1.1:
- From upstream Electrum:
- AppImage: we now also distribute self-contained binaries for x86_64 Linux in the form of an AppImage (#5042). The Python interpreter, PyQt5, libsecp256k1, PyCryptodomex, zbar, hidapi/libusb (including hardware wallet libraries) are all bundled. Note that users of hw wallets still need to set udev rules themselves.
- hw wallets: fix a regression during transaction signing that prompts the user too many times for confirmations (commit 2729909)
- transactions now set nVersion to 2, to mimic Bitcoin Core
- fix Qt bug that made all hw wallets unusable on Windows 8.1 (#4960)
- fix bugs in wallet creation wizard that resulted in corrupted wallets being created in rare cases (#5082, #5057)
- fix compatibility with Qt 5.12 (#5109)
- The logging system has been overhauled (#5296). Logs can now also optionally be written to disk, disabled by default.
- Fix a bug in synchronizer (#5122) where client could get stuck. Also, show the progress of history sync in the GUI. (#5319)
- fix Revealer in Windows and MacOS binaries (#5027)
- fiat rate providers:
- added CoinGecko.com and CoinCap.io
- BitcoinAverage now only provides historical exchange rates for paying customers. Changed default provider to CoinGecko.com (#5188)
- hardware wallets:
- Ledger: Nano X is now recognized (#5140)
- KeepKey:
- device was not getting detected using Windows binary (#5165)
- support firmware 6.0.0+ (#5205)
- Trezor: implemented “seedless” mode (#5118)
- Coin Control in Qt: implemented freezing individual UTXOs in addition to freezing addresses (#5152)
- TrustedCoin (2FA wallets):
- better error messages (#5184)
- longer signing timeout (#5221)
- Kivy:
- fix bug with local transactions (#5156)
- allow selecting fiat rate providers without historical data (#5162)
- fix CPFP: the fees already paid by the parent were not included in the calculation, so it always overestimated (#5244)
- Testnet: there is now a warning when the client is started in testnet mode as there were a number of reports of users getting scammed through social engineering (#5295)
- CoinChooser: performance of creating transactions has been improved significantly for large wallets. (d56917f4)
- Importing/sweeping WIF keys: stricter checks (#4638, #5290)
- Electrum protocol: the client’s “user agent” has been changed from “3.3.5” to “electrum/3.3.5”. Other libraries connecting to servers can consider not “spoofing” to be Electrum. (#5246)
- Several other minor bugfixes and usability improvements.
- qt: fix crash during 2FA wallet creation (#5334)
- fix synchronizer not to keep resubscribing to addresses of already closed wallets (e415c0d9)
- fix removing addresses/keys from imported wallets (#4481)
- kivy: fix crash when aborting 2FA wallet creation (#5333)
- kivy: fix rare crash when changing exchange rate settings (#5329)
- A few other minor bugfixes and usability improvements.
- Namecoin-specific:
- Checkpointed AuxPoW truncation. This requires servers to run ElectrumX v1.9.2 or higher. All public servers have upgraded; if you run a private server, please make sure that you’ve upgraded if you want Electrum-NMC to keep working.
- Pending registrations in Manage Names tab now show the name and value rather than a blank line.
- Manage Names tab now shows an estimated expiration date in addition to a block count.
- Manage Names tab now allows copying identifiers and values to the clipboard.
- Status bar now shows a count of registered names and pending registrations next to the NMC balance.
- Set memo in name wallet commands. This improves Coin Control, which paves the way for anonymity.
- We now distribute Android APK binaries and GNU/Linux AppImage binaries (in addition to the previously existing Python tarball binaries and Windows binaries). Android and AppImage binaries are not tested in any way (they might not even boot) – please test them and let us know what’s broken.
- Notify when a new version of Electrum-NMC is available.
- Add 2 new servers.
- Remove 2 old servers that are now being decommissioned.
- Various fixes for exception handling.
- Various unit tests and fixes for AuxPoW.
- Various rebranding fixes.
- Various code quality improvements.
I want to draw attention in particular to one of the code quality improvements. Most forks of Electrum rename the electrum Python package, in order to avoid causing namespace conflicts if both Electrum and an Electrum fork are installed on the same system. Unfortunately, the result of this is that any change to import statements in upstream usually triggers a merge conflict. I brought up this subject with SomberNight from upstream Electrum, in the hopes that we could find a solution that would avoid the merge conflicts. My initial suggestion was for upstream to switch to relative imports; SomberNight shot that down due to code readability concerns, but he posted a code snippet that was a (non-working) attempt to work around the issue. Based on the rough direction of his code snippet, I managed to produce a working patch to Electrum-NMC that allows the imports to revert to the upstream version. For an idea of how much improvement this is, prior to this patch, merging one release tag’s worth of commits (i.e. about a month of commits) would typically take me a day or so. Now, it takes me about 30 minutes. Kudos to SomberNight for his excellent efforts working with me to get us to a solution that optimizes productivity for both upstream and downstream.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
ncdns rbm build scripts added support for Linux32, Win64, and Win32 targets
As Hugo mentioned previously, rbm-based build scripts for ncdns are available. rbm is the build system used by Tor Browser. This work paves the way for reproducible builds of ncdns, improves the security of the build process against supply-chain attacks, and also paves the way for Windows and macOS support in our next-gen TLS interoperability codebase, ncp11 [1]. I’ve been spending some time improving those build scripts; here’s what’s new:
- Considerable effort has gone into shrinking the diff compared to upstream tor-browser-build as much as possible. Upstream Tor has much better QA resources, so it’s important to avoid deviating from what they do unless it’s critically important.
binutilsandgccare now dependencies of Go projects that use cgo. This means that we build the compiler from a fixed version of the source code rather than using whatever compiler Debian ships with. This brings us closer in line with what upstream tor-browser-build does, probably fixes some compiler bugs, and probably improves reproducibility.- Linux cross-compiling was fixed. Currently, this means that 32-bit x86 Linux targets now build. In the future, once upstream tor-browser-build merges my (currently WIP) patch for cross-compiled Linux non-x86 targets (e.g. ARM and POWER), those targets should work fine with ncdns as well.
- Windows targets were fixed. This mostly consisted of fiddling with dependencies (ncdns uses different libraries on Linux and Windows), but also meant adding the
mingw-w64project from upstream tor-browser-build.
All of the above improvements are currently awaiting code review.
The next things I’ll be working on are:
- Fixing macOS targets. So far, all of the dependencies for ncdns build without errors, but ncdns itself fails because of an interesting bug that seems to manifest when two different cgo-enabled packages have the same name. ncdns includes a fork of the Go standard library’s
x509package; both the forked package and the original package are dependencies of the ncdns package, and it turns out that the only OS where cgo is used inx509is… macOS. We never noticed this before, because our existing ncdns macOS binaries are built without cgo (because no macOS cross-compiler was present); now that we’re building in an environment where cgo is present for macOS, we’re subject to whatever quirks impact cgo on macOS. I think this is going to be pretty easy to work around by disabling cgo for the ncdnsx509fork, but the cleanest way to do that is going to require getting a patch merged upstream totor-browser-build. - Adding an
ncdns-nsisproject, so that rbm builds the Windows installer. This is already started, but I haven’t gotten very far yet. - Adding other Namecoin Go projects, such as
crosssignnameconstraintandncp11. ncp11 is going to be especially interesting, due to its exercising of cgo code paths that almost no one uses. This should be useful in finally getting ncp11 binaries for Windows and macOS [1].
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Wait, you haven’t heard about ncp11 yet? Go check out my 35C3 slides and workshop notes about that!
35C3 Summary
As was previously announced, Jonas Ostman, Cassini, and I (Jeremy Rand) represented Namecoin at 35C3 in Leipzig, Germany. Same as last year, we had an awesome time there. As usual for conferences that we attend, we engaged in a large number of conversations with other attendees. Also as usual, I won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to me at conferences without worrying that off-the-cuff comments will be broadcast to the public. However, the first fruits of those discussions started showing up on GitHub by January 2019, so hopefully you won’t be waiting too long. I would like to give a special shout-out to Diego “rehrar” Salazar and Dimi “m2049r” Divak from the Monero community, with whom I spent quite a lot of time hanging out during the Congress – very fun people to talk to.
Namecoin gave 2 talks, as well as a workshop, all of which were hosted by the Monero Assembly and the Critical Decentralization Cluster (CDC). We’re still waiting for the CDC to post videos of Namecoin’s talks, but in the meantime, here are the slides from Namecoin’s talks, as well as the notes from Namecoin’s workshop:
Namecoin Assembly Introduction
Speaker: Jeremy Rand
As 35C3 kicked off, the CDC invited each of the Assemblies to give a short presentation introducing themselves. Although Namecoin wasn’t, officially speaking, an Assembly (we were registered as part of the Monero Assembly), the CDC very kindly treated us as our own Assembly, and therefore we got to give an introduction presentation here. This presentation was thrown together in the ~15 minutes prior to the introduction presentations beginning, but I think it did a good job of explaining what we’re about.
Lecture: Namecoin as a Decentralized Alternative to Certificate Authorities for TLS: The Next Generation
How we improved the attack surface, compatibility, and scalability of Namecoin’s replacement for the Certificate Authority system
Speaker: Jeremy Rand
Certificate authorities suck, but the proposed replacements (e.g. DNSSEC/DANE) aren’t so great either. That’s why one year ago at the 34C3 Monero Assembly, I presented Namecoin’s work on a decentralized alternative to certificate authorities for TLS. The attack surface was, in my opinion, substantially lower than any previously existing attempt. Compatibility and scalability weren’t too bad either. But we’re never satisfied, and wanted something even better. With significantly improved attack surface, compatibility, and scalability, our improved design bears little resemblance to what we had one year ago. In this talk, I’ll cover the various shortcomings in our replacement for TLS certificate authorities from one year ago, and how we fixed them.
Certificate authorities (CA’s) pose a serious threat to the TLS ecosystem. Prior proposed solutions (e.g. Convergence, DANE, HPKP, CAA, and CT) simply reshuffle the set of trusted third parties. In contrast, Namecoin solves the underlying problem: if you know a Namecoin domain name, you can find out which TLS certificates are valid for it, with a threat model and codebase nearly identical to the battle-hardened Bitcoin. One year ago at the 34C3 Monero Assembly, I presented a design (with implemented, working code) for accomplishing this in the real world of uncooperative web browsers, with best-in-class attack surface, good compatibility, and good scalability.
But there was still much that could be improved, ranging from ending our reliance on HPKP API’s (which are being phased out), to preventing the browser’s TLS implementation from leaving your browsing history on the disk, to sandboxing Namecoin’s certificate override code so that it can’t compromise non-Namecoin traffic even if exploited, to supporting Firefox and Tor Browser (both of which posed unique challenges), to name just a few. This talk will cover a wide variety of improvements we made to attack surface, compatibility, and scalability. Expect to learn lots of interesting little-known trivia about the innards of TLS implementations, which can be used for unexpected purposes in our mission to rid the world of the scourge that is certificate authorities.
Workshop: Demo + Walkthrough: Namecoin as a Decentralized Alternative to Certificate Authorities for TLS
Demo of the latest Namecoin TLS code, and install it yourself
Workshop Hosts: Jeremy Rand and Jonas Ostman
In this workshop, I’ll demo the latest Namecoin TLS code that’s covered in my talk “Namecoin as a Decentralized Alternative to Certificate Authorities for TLS: The Next Generation”. I’ll also walk you through installing it on your own machine so you can try it out for yourself. Bring a GNU/Linux VM (or, if you’re particularly brave, a GNU/Linux system that’s not a VM), and preferably have Chromium, Firefox, and Tor Browser installed (you can choose to install only a subset of those browsers if you like).
Thanks
Huge thank you to the following groups who facilitated our participation:
- The Monero Assembly
- The Critical Decentralization Cluster
- Replicant
- The anonymous person who obtained tickets for us – you know who you are, thank you!
We’re looking forward to 36C3 in December 2019!
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Daniel Kraft at Malta Blockchain Summit 2018 (Video)
As was previously announced, Namecoin Chief Scientist Daniel Kraft was a panelist at Malta Blockchain Summit 2018, on the “Permissioned vs Permissionless Blockchains” panel. A video of the panel is now available. The video can be viewed via youtube-dl (Debian package) (recommendation by Whonix) if you don’t trust YouTube’s JavaScript (and there’s no reason why you should trust YouTube’s JavaScript!).
Namecoin’s Daniel Kraft at Grazer Linuxtage 2015 (Video)
Back in 2015, Namecoin Chief Scientist Daniel Kraft gave a German-language talk at Grazer Linuxtage. A video of his talk is available for interested viewers. The video can be viewed via youtube-dl (Debian package) (recommendation by Whonix) if you don’t trust YouTube’s JavaScript (and there’s no reason why you should trust YouTube’s JavaScript!).
Progress on reproducibility of ncdns builds
As part of work to ensure that all Namecoin software can be built and distributed in a reproducible fashion, RBM build scripts for ncdns are now available. These scripts are currently experimental, but will become the preferred way to build ncdns.
The RBM build system is specifically designed to facilitate reproducible builds and is also commonly used to build Tor Browser. The RBM build scripts for ncdns build on the existing Tor Browser build system, which will ease future integration of ncdns with Tor Browser in a reproducible manner.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Electrum: Merkle Checkpoints
This post is an explanation of work originally done by Neil Booth and Roger Taylor (for ElectrumX and Electron-Cash), which Namecoin is adapting for use in Electrum and Electrum-NMC.
When I last posted about auditing Electrum-NMC’s bandwidth usage, I had managed to reduce the data transfer of the portion of the blockchain covered by a checkpoint from 3.2 MB per chunk down to 323 KB per chunk. I hinted then that there was most likely some further optimization that could be done. Today I’ll briefly describe one of them: Merkle checkpoints.
A blockchain, by its nature, is a sequence of blocks where the block at height N commits to the block at height N-1. From this fact, it follows that if you know the most recent block, you can verify the authenticity of any earlier block by recursively following those commitments until you arrive at the block you want to verify. Cryptographically knowledgeable readers will recognize this as a particularly inefficient form of a Merkle tree. For readers who aren’t familiar with Merkle trees, they’re a cryptographic construction by which a single hash can commit to a large number of hashes, via recursive commitments. Merkle trees come in a wide variety of constructions, but the most common form of a Merkle tree is a balanced binary Merkle tree. In such a tree, the proof size to connect a given hash to the root hash is logarithmic in terms of the total number of hashes committed to. Balanced binary Merkle trees are used, for example, to allow a block header to commit to the transactions in a block. A blockchain is an optimally unbalanced Merkle tree, in which the proof size is linear rather than logarithmic.
Linear proof size means that, in Electrum today, if I want to prove that header 2016 is committed to by a checkpoint on header 4031, I need to download 2016 headers, which is an unpleasantly large download of (4031 - 2016 + 1) * 80 = 161280 bytes [1]. Logarithmic proof sizes given by a balanced binary Merkle tree, by contrast, would mean downloading ceil(log2(4031)) * 32 + 80 = 464 bytes. What if the checkpoint is for height 1,000,000? In that case, it ends up as ceil(log2(1000000)) * 32 + 80 = 720 bytes. Naturally, we’d like logarithmic proof sizes rather than linear proof sizes. Using block headers themselves as Merkle roots can’t achieve this, but there’s nothing whatsoever that prevents us from taking all the historical block headers, and arranging them into a balanced binary Merkle tree. We could then use the Merkle root as a checkpoint, and thereby gain extremely small proofs that a given header is committed to by a checkpoint.
This is exactly what Neil Booth implemented in ElectrumX, as the cp_height checkpoint system, and which Roger Taylor subsequently implemented in Electron-Cash. Since Electrum-NMC’s upstream implementation is Electrum, I’ve been working on porting Roger’s Electron-Cash support for Merkle checkpoints to Electrum. At the moment, I have a pull request undergoing review for upstream Electrum. I’m hopeful that it will pass peer review soon, at which point I’ll work on merging it to Electrum-NMC.
Once Merkle checkpoints are merged to Electrum-NMC, we’ll be able to set a checkpoint on a recent height (rather than the 36-kiloblock-ago height that we currently set), without causing a severe delay on name lookups. This will be a substantial improvement to Electrum-NMC’s performance.
(However, there are additional optimizations that can be made. More on those in a future post.)
This work was funded by Cyphrs.
[1] These figures assume binary encoding, but Electrum’s protocol uses hex encoding, which effectively doubles the byte count of all of these figures.
Namecoin’s Daniel Kraft will be a speaker at CloudFest 2019
Namecoin’s Chief Scientist Daniel Kraft will be a speaker at CloudFest 2019. Daniel’s talk, What The Cryptocurrency Boom Missed: The Namecoin Story, is on March 28th at 10:55 AM in “Ballsaal Berlin”. The description of his talk is below:
To hear Daniel Kraft, the lead engineer of Namecoin, say it – “Bitcoin frees money, Namecoin frees DNS, identities, and other information”. Namecoin is the second oldest cryptocurrency after Bitcoin, but it is more than that. It builds a naming system that is decentralised, trustless, secure and has human-readable names. As such, it is the world’s first solution to “Zooko’s triangle”. Applications range from secure management of online identities and cryptographic keys and a decentralised alternative to the DNS and the certificate-authority infrastructure to fully decentralised multiplayer online games. Find out why cryptocurrency technology is so much more than merely an investment, and discover how it is being employed to put greater privacy and security tools into the hands of consumers.
ElectrumX v1.9.2 Released by Upstream, Includes Checkpointed AuxPoW Truncation
Upstream ElectrumX has released v1.9.2, which includes several Namecoin-related changes (all of which were submitted by me and merged by Neil). Here’s what’s new for Namecoin:
- Add 2 new servers.
- Use the correct default Namecoin Core RPC port; this means ElectrumX server operators won’t need to manually set the RPC port via an environment variable anymore.
- Checkpointed AuxPoW truncation.
- Use a correct
MAX_SENDby default for AuxPoW chains. The previous default of 1 MB doesn’t work with AuxPoW chains because AuxPoW headers are substantially larger than Bitcoin headers; the new default of 10 MB for AuxPoW chains allows Namecoin to sync properly. This means ElectrumX server operators won’t need to manually set theMAX_SENDvia an environment variable anymore.
ElectrumX then subsequently released some other revisions, none of which are specific to Namecoin; the latest release is currently v1.9.5. At least 2 of the 3 public Namecoin ElectrumX servers have already upgraded; as a result, I’ve merged checkpointed AuxPoW truncation into Electrum-NMC’s master branch. If you run a Namecoin ElectrumX server and haven’t yet upgraded, please consider upgrading to the latest ElectrumX release so that your users will be able to use future releases of Electrum-NMC (which will require checkpointed AuxPoW truncation) without any trouble.
(And a reminder that we need more ElectrumX instances… please consider running one if you have a server with spare resources!)
This work was funded by Cyphrs.
Electrum-NMC v3.3.3.1.1 Released
We’ve released Electrum-NMC v3.3.3.1.1. This release includes an important fix for name transactions (both wallet and lookups), and we recommend that all users upgrade. Here’s what’s new since v3.3.3.1:
- Remove mandatory wallet dependency for name_show
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Electrum-NMC v3.3.3.1 Released
We’ve released Electrum-NMC v3.3.3.1. This release includes important security fixes from upstream Electrum, and we recommend that all users upgrade. Here’s what’s new since v3.2.4b1:
- Fix accidental Namecoin rebranding in the AuxPoW branch that was causing the AuxPoW branch to error.
- Fix some tests that were failing.
- Fix broken imports in revealer plugin.
- Various fixes for the Android port.
- Rebranding fixes for the Qt GUI.
- Fix filter columns in the Manage Names tab.
- Fix compatibility of Manage Names tab with current upstream Electrum.
- Fix bug where some names were missing from the Manage Names tab.
- Fix Renew and Configure buttons in Manage Names tab.
- Fix Max button on Send tab.
- Rebranding fixes for history list.
- Rebranding fixes for exported history.
- Fix broken imports in KeepKey plugin.
- Fix broken imports in Labels plugin.
- Fix bug that prevented using Coin Control for name updates.
- Add 2 new servers.
- Improve documentation of timewarp hardfork.
- Rebranding fixes for update check.
- Fix icons.
- Windows binaries are available again.
- Improvements from upstream Electrum (including security fixes).
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
Electrum-NMC: Checkpointed AuxPoW Truncation
I posted previously about auditing Electrum-NMC’s bandwidth usage. In that post, I mentioned that there were probably optimizations that could be done to reduce the 3.2 MB per 2016 block headers that get downloaded when looking up a name that’s covered by a checkpoint. I’ve now implemented one of them: AuxPoW truncation.
Some background: AuxPoW (auxilliary proof of work) is the portion of Namecoin block headers that allows clients to verify that the PoW expended by miners on the parent chain (usually Bitcoin) applies to Namecoin as well. As a result, SPV clients such as Electrum-NMC (which verify PoW) need to download the AuxPoW data. However, the AuxPoW data in a Namecoin block header does not contribute to the block hash. As a result, the commitment in a Namecoin block header to the previous block header can be verified without having access to any AuxPoW data.
Why does this matter? AuxPoW is by far the largest part of a Namecoin block header, because it contains a coinbase transaction from the parent chain. Coinbase transactions can frequently be quite large, especially if the parent block is mined by a mining pool that’s paying a large number of miners via the coinbase transaction. If we can omit the AuxPoW data from Namecoin block headers, then that saves a lot of bytes.
Obviously, we can’t get rid of the AuxPoW data completely, since SPV validation requires PoW verification. But not all blocks are verified via SPV – blocks that are covered by a checkpoint don’t need to have their PoW checked, since the checkpoint implies validity. So, we can simply not check the AuxPoW for any blocks that are committed to by a checkpoint. And if we don’t need to check the AuxPoW for such blocks, we don’t need to download it either.
Conveniently, the Electrum protocol includes a feature that allows the client to tell the server what height its checkpoint is set to. This feature isn’t actually used yet in the Electrum client, but we can use that feature to have Electrum-NMC tell ElectrumX what height its checkpoint is set to, such that ElectrumX will then truncate AuxPoW data from the block headers it responds with. I’ve submitted a PR for ElectrumX that does exactly that: with this PR, ElectrumX truncates AuxPoW data from block headers when the client supplies a checkpoint height that is higher than the height of the block header. Neil from ElectrumX has already merged my PR; once it’s in a tagged release, I’ll push the relevant changes to Electrum-NMC as well.
What does the data transfer look like now?
- Before: 3.2 MB per 2016 headers
- After: 323 KB per 2016 headers
So that’s roughly a 90% reduction. Not bad. There are probably some additional optimizations that can still be done, but those will have to wait for another day.
This work was funded by Cyphrs.
Internet Governance Forum 2018 Summary
As was previously announced, I (Jeremy Rand) represented Namecoin at Internet Governance Forum 2018 in Paris.
My panel at IGF (moderated by Chiara Petrioli from Università degli Studi di Roma La Sapienza) went reasonably well, and a quite diverse set of perspectives were represented. I suspect that a lot of the attendees had never been exposed to the cypherpunk philosophy of “trusted third parties are security holes” (credit to Nick Szabo for that phrasing), and I hope I did a good job of providing that exposure so that maybe we’ll have some new allies. As with ICANN58, I continued my adherence to the Fluffypony way of answering questions: don’t hype things, and always be quick to admit disadvantages. This worked well at ICANN, and I think it worked well at IGF. (Special thanks to the guy from Verisign who asked a question in the Q&A that will shortly be immortalized in the Namecoin.org FAQ!)
IGF has published a transcript[1], a video recording, and a report. The transcript and report should work fine in Tor Browser at High Security settings; the video recording can be viewed via youtube-dl (Debian package) (recommendation by Whonix) if you don’t trust YouTube’s JavaScript (and there’s no reason why you should trust YouTube’s JavaScript!). I’ve also posted my slides.
The next day, I was on a panel hosted by Jean-Christophe Finidori. This one was a bit more in my comfort zone, as the attendees were mostly blockchain enthusiasts, and there were a lot of quite sophisticated questions about the details of Namecoin’s design. Unfortunately, I’m not aware of any recordings of this event.
Of course, I had lots of other meetings while I was in Paris, but as usual, I won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to me at conferences without worrying that off-the-cuff comments will be broadcast to the public. That said, the result of one of those conversations is likely to be posted very soon.
Thanks to Chiara and Jean-Christophe for inviting me; I enjoyed visiting Paris!
[1] Reading the official transcript makes me realize how lucky I am that I’m not hearing-impaired. Hearing-impaired people are going to have a miserable time trying to understand the transcript.
Namecoin’s Jeremy Rand and Jonas Ostman will be at 35C3
You might have noticed that we’ve been a bit quiet on this news feed as well as social media for the last month. Not to worry, there’s a reason: same as last year, I (Jeremy Rand) and Jonas Ostman will represent Namecoin at 35C3 (the 35th Chaos Communication Congress) in Leipzig, December 27-30. And this time, our R&D lab has been very busy cooking up some cool stuff for 35C3, which is why we haven’t posted much in the last month.
Once again, we’ll be hosted by the Monero Assembly. The schedule for Monero Assembly events isn’t yet finalized, but keep an eye on the schedule for details. We heard a rumor that talks might get recorded and live-streamed. We’re looking forward to the Congress!
Electrum-NMC v3.2.4b1 Beta Released
We’ve released Electrum-NMC v3.2.4b1. This is a beta release (even more so than the other downloads on the Beta Downloads page); expect a higher risk of bugs than usual. (As one example of a bug due to it being a beta, it doesn’t build for Windows without errors, so this release is for GNU/Linux users only.) Here’s what’s new:
- Name support.
- Checkpoint at height 385055.
- Fix macOS build issue.
- Code quality improvements.
- From upstream Electrum: the Safe-T mini hardware wallet from Archos is now supported.
- Other improvements from upstream Electrum.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund and Cyphrs.
ElectrumX v1.8.8 Released by Upstream, Includes Name Script Support
Upstream ElectrumX has released v1.8.8, which includes name script support. (ElectrumX then subsequently released some other minor revisions, which seem to mostly be bug fixes; the latest release is currently v1.8.12.) If you run a Namecoin ElectrumX server, please consider upgrading to the latest ElectrumX release so that your users will be able to use name scripts.
(And a reminder that we need more ElectrumX instances… please consider running one if you have a server with spare resources!)
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC: Checkpoints
I decided to spend some time auditing Electrum-NMC’s bandwidth usage, to see if any optimizations were possible and/or needed. Using the excellent nethogs tool by Arnout Engelen, I determined that Electrum-NMC’s initial syncup downloads 672 MB, which is quite a lot. Clearly some optimizations would be highly welcome.
Upstream Electrum avoids downloading most of the Bitcoin blockchain’s headers via checkpoints. Basically, a checkpoint consists of a hardcoded block hash (and a difficulty target), specifically one for each difficulty retargeting period (2016 blocks). Electrum doesn’t typically download any headers that are between two checkpoints; instead it only downloads such headers if it needs to verify a transaction from one of those blocks. This reduces bandwidth usage considerably. Electrum’s debug console can generate a checkpoint file (assuming that you’re connected to a trustworthy ElectrumX server; I’m using my own ElectrumX server connected to my own Namecoin Core node, so my server is indeed trustworthy to me). Electrum-NMC hadn’t yet gotten around to setting any checkpoints, due to it being a lower priority than getting name transactions working. But now that name transactions pretty much work, I was able to try out checkpoints.
Interestingly, after I set checkpoints through about 38 kiloblocks ago (more on why I chose that below), Electrum-NMC started reporting blockchain validation errors, most of which seemed to be related to missing headers. After quite a bit of debugging, I figured out why this was happening: in Bitcoin, calculating the new difficulty target requires some information from the first and last block header for a given retargeting period. Electrum’s checkpoints supply this information. However, this is actually not mathematically correct behavior, and exposes the blockchain to what’s called a timewarp attack. A timewarp attack can only be successfully pulled off by an attacker who can already do a 51% attack, so the attack is difficult, but if it’s successfully done, the attacker can make the difficulty continually drop, thus allowing them to mint more coins than the expected subsidy per 2 weeks. Because a timewarp attack is difficult to pull off, and because fixing it constitutes a hardfork, Bitcoin never actually fixed that vulnerability. Namecoin, however, did fix it, at the same time that we hardforked to enable merged mining. How does the timewarp fix work? Well, it actually needs a block header from the previous retargeting period in order to calculate the new target. Guess what, Electrum’s checkpoints do not supply such information (which would be useless in Bitcoin). And thus, the target calculation code in Electrum-NMC was complaining that the header from the previous retargeting period wasn’t present.
After quite a bit of trying to find a way to solve the issue without highly invasive changes, I eventually stumbled on an easy hack. I did a one-line change of the code that reports the number of checkpoints available, so that if n checkpoints exist, Electrum-NMC calculates the block height to download under the impression that n-1 checkpoints exist. This means that Electrum-NMC will actually download the final checkpoint’s set of 2016 block headers before it moves on to the uncheckpointed headers. As a result, it actually will have the previous retargeting period’s headers available when it tries to calculate the new difficulty target. It’s a stupid hack, but it definitely seems to work.
So, with checkpoints set through 38 kiloblocks ago, I measured Electrum-NMC’s bandwidth usage with nethogs again, and this time it had dropped to 66 MB of downloaded data. Not bad!
But why did I set the last checkpoint at 38 kiloblocks ago? Well, if we’re doing name lookups, we always want to have block headers for the last 36 kiloblocks, since unexpired names could be anywhere within that range. As an experiment, I tried setting a checkpoint at circa 3 kiloblocks ago, and found that Electrum-NMC’s bandwidth usage dropped to 4.9 MB of downloaded data during initial syncup. However, trying to do a name lookup resulted in a “missing header” error. Not much of a surprise there. However, upstream Electrum handles this situation just fine when verifying currency transactions – if you try to verify a currency transaction that’s behind a checkpoint, Electrum just downloads the necessary headers before trying to verify it. I quickly figured out where that code was, and adapted it to work with the name_show console command. With this change, if a name is behind a checkpoint, the lookup succeeds – but if you haven’t already downloaded the relevant headers, Electrum-NMC downloads 2016 headers (about 3.2 MB according to nethogs) before verifying the name.
For now, I don’t intend to put checkpoints beyond 38 kiloblocks ago into Electrum-NMC, because downloading 3.2 MB to do a lookup adds noticeable delay. There are probably some ways this amount of data can be optimized significantly, but that’ll have to wait for another day. That said, 66 MB instead of 672 MB is pretty nice savings.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ConsensusJ WalletAppKit Support Merged by Upstream; ConsensusJ-Namecoin v0.3.2.1 Released
One of the main reasons that ConsensusJ-Namecoin is still in the Beta Downloads section of Namecoin.org is that it carries several patches against upstream ConsensusJ that haven’t yet been upstreamed. This presents two resultant issues:
- There are fewer eyes on the ConsensusJ-Namecoin code.
- ConsensusJ-Namecoin takes some extra time to benefit from new code from upstream, because I need to manually rebase against that new code (and fix whatever conflicts might show up).
Each of these issues reduces the security of ConsensusJ-Namecoin, which means we should fix them by getting our patches upstreamed. We’ve been making some progress on this recently, and last month we saw some additional progress, as I’ve submitted the WalletAppKit support from ConsensusJ-Namecoin to upstream, and upstream has merged it. Mommy, what’s a WalletAppKit? The BitcoinJ library, on which ConsensusJ is based, includes quite a few different modes of operation. The most well-known mode is a mode that downloads blockchain headers and does SPV validation of them. A lesser-known mode simply opens P2P connections to other Bitcoin nodes and lets the user figure out what to do with those P2P connections. The latter mode (known as PeerGroup) is utilized as a component of the former mode (known as WalletAppKit). Prior to my pull request, upstream ConsensusJ’s daemons (bitcoinj-daemon and namecoinj-daemon) used PeerGroup mode, and simply assumed (for the purposes of the bitcoind-style RPC API) that the peers they’ve connected to are telling the truth. ConsensusJ-Namecoin, meanwhile, uses WalletAppKit mode, so that we can be reasonably confident (within SPV’s threat model [1]) that the name transactions we’re given are actually from the chain with the most work.
As expected, upstream ConsensusJ developer Sean Gilligan noticed some things that could be improved as part of the code review process (which is exactly why we want to get this stuff upstreamed). I made the relevant changes, and the code is merged. Now that WalletAppKit is merged, the most likely next candidate for upstreaming will be the name_show RPC call, and associated backend code. It’s likely that the name_show upstreaming will focus on leveldbtxcache mode, for a few reasons:
leveldbtxcachemode is by far the most secure SPV mode for Namecoin name lookups (substantially more secure than any SPV clients that exist in the Bitcoin world).leveldbtxcachemode has much faster lookups than the otherlibdohj-namecoinname lookup methods, which use an API server.- The API server that
libdohj-namecoinuses by default when not inleveldbtxcachemode is WebBTC, which has been down for maintenance for quite a while. Also, WebBTC is problematic due to its lack of consensus safety (it re-implements the consensus rules instead of relying on Namecoin Core’s consensus implementation, and this has caused it to chainfork from the Bitcoin chain before). - The API-server security model isn’t actually a bad one (it’s a lot easier to Sybil the P2P network than to impersonate an API server), but I tend to think that Electrum is a better (and more standardized) approach to the API-server security model than the
libdohj-namecoinimplementation. It’s conceivable that we could combine the two approaches in the future (maybe makelibdohj-namecoinquery an Electrum instance in addition to the P2P network?), but this is not exactly a high priority for our R&D budget given thatleveldbtxcachemode isn’t in any immediate danger of encountering scaling problems.
Hopefully we’ll see more progress on this front in the near future. In the meantime, I’ve released ConsensusJ-Namecoin v0.3.2.1 (on the Beta Downloads page as usual), which incorporates the latest improvements from upstream ConsensusJ (including Sean’s code review of my WalletAppKit support).
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] The SPV threat model makes a security assumption that the chain with the most work is also a valid chain. This is, of course, not guaranteed to be a correct assumption, although there are some game-theoretic reasons to believe that as long as an economically strong fraction of the network is using full nodes, then SPV is safe for everyone else. You should definitely run a full node for your Namecoin resolution if you have the ability to do so; you’ll be more secure yourself, and you’ll also be making the network more secure for anyone who’s using an SPV node.
Namecoin’s Jeremy Rand will be a speaker at Internet Governance Forum 2018
I (Jeremy Rand) will be a speaker at Internet Governance Forum 2018, November 12 - November 14, in Paris (chartered by the UN and hosted at the UNESCO headquarters). I’ll be speaking on the “DNS enhancements and alternatives for the Future Internet” panel at 9:00 AM - 10:30 AM (local time) on Monday, November 12. Huge thanks to Chiara Petrioli from Università degli Studi di Roma La Sapienza for inviting me!
While I’m in Paris, I’ll also be on an “Internet of Trust” panel at 6:30 PM - 8:30 PM (local time) on Tuesday, November 13, hosted by Jean-Christophe Finidori. Thanks to Jean-Christophe for inviting me!
Decentralized Web Summit 2018 Summary
As was previously announced, I (Jeremy Rand) represented Namecoin at Decentralized Web Summit 2018 in San Francisco.
This time, the focus of my attendance was less on giving talks and more about talking with other attendees about possible collaborations. As usual, I won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to me at conferences without worrying that off-the-cuff comments will be broadcast to the public.
That said, I did give a lightning talk. You can view the official recording page (JavaScript required, yuck!), or you can view the video file itself (no JavaScript required; my lightning talk is at 24:15 - 32:08).
Thanks to Internet Archive for inviting me, we’re looking forward to the next event!
New York Times’ Allegation of Saudi Intelligence Targeting Namecoin Developer Is Consistent with 2013 Reporting by Moxie Marlinspike
The New York Times published what appears to be a highly interesting scoop on October 20, 2018. The New York Times article alleges that the government behind the State Sponsored Actors attack on circa 40 Twitter users (most of whom, including me, were free software developers and privacy activists) was none other than Saudi Arabia. Those of us who were notified of the attack in 2015 have been trying to find out more ever since, with no luck until now.
As a precaution against censorship risk, the relevant subsection of the article is reproduced below:
A Suspected Mole Inside Twitter
Twitter executives first became aware of a possible plot to infiltrate user accounts at the end of 2015, when Western intelligence officials told them that the Saudis were grooming an employee, Ali Alzabarah, to spy on the accounts of dissidents and others, according to five people briefed on the matter. They requested anonymity because they were not authorized to speak publicly.
Mr. Alzabarah had joined Twitter in 2013 and had risen through the ranks to an engineering position that gave him access to the personal information and account activity of Twitter’s users, including phone numbers and I.P. addresses, unique identifiers for devices connected to the internet.
The intelligence officials told the Twitter executives that Mr. Alzabarah had grown closer to Saudi intelligence operatives, who eventually persuaded him to peer into several user accounts, according to three of the people briefed on the matter.
Caught off guard by the government outreach, the Twitter executives placed Mr. Alzabarah on administrative leave, questioned him and conducted a forensic analysis to determine what information he may have accessed. They could not find evidence that he had handed over Twitter data to the Saudi government, but they nonetheless fired him in December 2015.
Mr. Alzabarah returned to Saudi Arabia shortly after, taking few possessions with him. He now works with the Saudi government, a person briefed on the matter said.
A spokesman for Twitter declined to comment. Mr. Alzabarah did not respond to requests for comment, nor did Saudi officials.
On Dec. 11, 2015, Twitter sent out safety notices to the owners of a few dozen accounts Mr. Alzabarah had accessed. Among them were security and privacy researchers, surveillance specialists, policy academics and journalists. A number of them worked for the Tor project, an organization that trains activists and reporters on how to protect their privacy. Citizens in countries with repressive governments have long used Tor to circumvent firewalls and evade government surveillance.
“As a precaution, we are alerting you that your Twitter account is one of a small group of accounts that may have been targeted by state-sponsored actors,” the emails from Twitter said.
Before I go any further, it’s important to remember that the New York Times’s source for these claims appears to be anonymous intelligence officials, and caution is warranted when evaluating claims by anonymous intelligence officials (cough cough Iraq cough cough).
That said, let’s assume for the purpose of argument that the New York Times’s allegation is correct, and Saudi Arabia was behind the attack. What’s the motive? It’s certainly plausible that Saudi Arabia would have an interest in Tor developers, but how did I get targeted? Between 2013 and 2015 (when Alzabarah allegedly worked at Twitter), there were three main things I was spending my time on:
- Console game hacking research for my undergraduate honors thesis. Highly unlikely that Saudi Arabia would care about this.
- Machine learning, ranking, and privacy research for the YaCy search engine, which would later evolve into my master’s thesis. I suppose it’s technically possible that Saudi Arabia would find this interesting (since censorship resistance and privacy are known to annoy the Saudi government), but this work was relatively low-profile (it was only discussed within my classes at my university, a couple of IRC channels with small audiences, and a couple of posts on the YaCy forum). Furthermore, no code was publicly available during this time period (which probably decreased any possible Saudi interest), and YaCy was simply too immature to credibly be considered a threat at that time (and probably even now).
- TLS PKI research for Namecoin. Specifically, my fork of Moxie Marlinspike’s Convergence (a tool for customizing TLS certificate validation in Firefox) was created in 2013, my TLS PKI research with Namecoin continued through the present day, and this research received a decent amount of public attention (including being presented at a poster session at Google’s New York office in 2013, and being the subject of a fundraising campaign in 2014).
Yeah, about that last one. It’s pretty clearly the one that would be most likely to attract attention from a state-sponsored actor (since it prevents state actors from compromising TLS certificate authorities in order to intercept encrypted communications), but why Saudi Arabia? I had been previously speculating that the involved state might be Iran, seeing as they’ve been publicly accused of compromising TLS certificate authorities in the past. I was not aware of any similar cases where Saudi Arabia was caught doing this.
However, then I ran across a highly interesting article from the aforementioned Moxie Marlinspike dated May 13, 2013. Again, as a precaution against censorship risk, the relevant parts are reproduced below:
Last week I was contacted by an agent of Mobily, one of two telecoms operating in Saudi Arabia, about a surveillance project that they’re working on in that country. Having published two reasonably popular MITM tools, it’s not uncommon for me to get emails requesting that I help people with their interception projects. I typically don’t respond, but this one (an email titled “Solution for monitoring encrypted data on telecom”) caught my eye.
I was interested to know more about what they were up to, so I wrote back and asked. After a week of correspondence, I learned that they are organizing a program to intercept mobile application data, with specific interest in monitoring:
- Mobile Twitter
- Viber
- Line
I was told that the project is being managed by Yasser D. Alruhaily, Executive Manager of the Network & Information Security Department at Mobily. The project’s requirements come from “the regulator” (which I assume means the government of Saudi Arabia). The requirements are the ability to both monitor and block mobile data communication, and apparently they already have blocking setup.
[snip]
One of the design documents that they volunteered specifically called out compelling a CA in the jurisdiction of the UAE or Saudi Arabia to produce SSL certificates that they could use for interception.
[snip]
Their level of sophistication didn’t strike me as particularly impressive, and their existing design document was pretty confused in a number of places, but Mobily is a company with over 5 billion in revenue, so I’m sure that they’ll eventually figure something out.
So, let’s look at some things that I found notable about this:
- Saudi Arabia was interested in doing TLS interception via a malicious CA. There’s your motive.
- The email exchange between Mobily and Moxie about interest in doing TLS interception was in 2013, the same year that Alzabarah allegedly began working for Twitter.
- I don’t know how long it’s expected to take a “confused” and “[not] particularly impressive” development team at a well-funded telecom to design TLS interception infrastructure, but it seems totally plausible that this Mobily project, or related projects at other Saudi telecoms or the Saudi government, continued through a significant portion of Alzabarah’s alleged employment at Twitter, possibly as late as when Alzabarah allegedly obtained access to user data in his engineering position at Twitter.
- Moxie is the original author of Convergence, but stopped maintaining it in 2012. My fork was created in 2013, and by 2014 my fork was the only maintained fork (after Mike Kazantsev stopped maintaining his Convergence-Extra fork). So anyone who was interested in Moxie’s work with TLS may very well have also been aware of me.
- Surveillance of Twitter is specifically mentioned in the email exchange between Mobily and Moxie.
So, as far as I can tell, the New York Times’s allegation that Saudi intelligence targeted my Twitter account seems to be quite consistent with the 2013 reporting by Moxie.
That said, there is an unexplained loose end. Most major browsers implemented TLS certificate pinning since 2013, and certificate pinning would probably have made it quite obvious if Saudi Arabia were using rogue TLS certificates to intercept communications with a large site like Twitter. Ditto for certificate transparency. So, even if Saudi intelligence was pursuing this project in 2013, it would be surprising if they’re still doing so.
If anyone has further information about the State Sponsored Actors attack, I strongly encourage you to share it with journalists. In particular, anonymously sending primary source documents to WikiLeaks would be a highly beneficial action.
cross_sign_name_constraint_tool v0.0.3 and tlsrestrict_nss_tool v0.0.3 Released
We’ve released cross_sign_name_constraint_tool v0.0.3 and tlsrestrict_nss_tool v0.0.3. Here’s what’s new:
- Both
cross_sign_name_constraint_toolandtlsrestrict_nss_tool:- Properly handle input CA’s that don’t have a CommonName.
- Code quality improvements.
tlsrestrict_nss_toolonly:- Compatibility fixes for Windows:
- Stop using
cpto enable CKBI visibility, since no such command exists on Windows. - Pass cert nicknames in NSS
certutilbatch files instead of as command-line args, because Windows doesn’t handle Unicode command-line args correctly.
- Stop using
- Error when CKBI appears to be empty; this is usually a symptom of missing libraries.
- Communicate with
certutilvia PEM instead of DER; this should reduce the risk of concatenated certs not having a clearly defined boundary. - Fix compatibility with Go 1.11 and higher.
- Fix cert deletion on Fedora 28 and higher (and probably various other platforms too).
- Partial support for bundling both 32-bit and 64-bit
certutilon Windows. - Partial support for continuously syncing an NSS DB on Windows whenever CKBI is updated (not yet ready for use; will be included in a future ncdns release).
- Code quality improvements.
- Compatibility fixes for Windows:
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin’s Daniel Kraft will be a speaker at Malta Blockchain Summit 2018
Namecoin’s Chief Scientist Daniel Kraft will be a speaker at Malta Blockchain Summit 2018, October 31 - November 3. Daniel is on the “Permissioned vs Permissionless Blockchains” panel at 9:30-9:50 on November 2.
ElectrumX: Name Script Support Merged by Upstream
A few months ago I wrote about name script support in ElectrumX. Neil from ElectrumX has now merged that code into ElectrumX master branch. I’ve also notified the operator of the public ElectrumX Namecoin instance, so hopefully soon it will be possible to use Electrum-NMC’s name script support with the default public ElectrumX instance. Kudos to Neil for accepting the pull request!
(This is probably a good time to remind readers that we need more ElectrumX instances… please consider running one if you have a server with spare resources!)
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC: Name Registration GUI
Now that Electrum-NMC GUI support for updating names is a thing, it’s time to advance to name registration GUI support.
Whereas the Renew Name and Configure Name... buttons each map directly to a single sequence of two console commands (name_update followed by broadcast), which makes their implementation relatively straightforward, registering a name is more complicated, due to the two-step procedure in which a salted commitment (name_new) is broadcast 12 blocks before the name registration itself (name_firstupdate) in order to prevent frontrunning attacks. Given that the name registration procedure was going to be a bit complicated, it seemed like a good idea to create a new console command for this purpose, so that the GUI can maintain a simple mapping to console commands.
In fact, I ended up creating a few different console commands. The first console command (queuetransaction) is used for storing transactions in the wallet that are intended to be broadcasted in the future once a trigger condition has occurred. An entry in the transaction queue consists of:
- Either a transaction ID or a name identifier
- A depth (in blocks)
- A raw transaction
When the specified transaction ID (or the most recent transaction for the specified name identifier) attains sufficient confirmations in the blockchain, the raw transaction will be broadcasted. In order to register a name, the following transaction queue entry would be used:
- Transaction ID of
name_new - Depth of 12 blocks
- Raw transaction of
name_firstupdate
There are some other use cases for the transaction queue, such as automatically renewing names when they’re approaching expiration, or automatically registering a name if/when its previous owner lets them expire. For now, we’ll focus on name registration.
Next up was a console command updatequeuedtransactions, which examines each of the transaction queue entries, and broadcasts and unqueues each of the entries whose trigger condition has been achieved. This wasn’t too complicated, although I did do some deliberating on when exactly to unqueue a transaction. In theory, an ElectrumX server could claim to have broadcasted a transaction but not actually do so, and if Electrum-NMC unqueues a transaction in this case, then the transaction will never actually get mined. A sledgehammer-style workaround here would be to try to re-broadcast each block until Electrum-NMC sees an SPV proof indicating that the transaction has, say, 12 confirmations (indicating that it very likely did get broadcasted and mined). However, I ended up deciding that this kind of attack is simply out of scope for the transaction queue, since the attack can apply equally well to arbitrary other transactions that get broadcasted. Solving this attack is probably something better done in upstream Electrum than by whatever hacky and poorly peer-reviewed approach we’d take in Electrum-NMC. So, we unqueue the transaction as soon as it’s broadcast. Easy enough.
updatequeuedtransactions is cool, but we want this to happen every block, automatically. So the next step was to add a hook that calls updatequeuedtransactions whenever a new block arrives. This should have been simple, but I quickly noticed that whenever this hook resulted in broadcasting a transaction, an assertion error would get logged, and the transaction would never broadcast. A quick inspection showed that the broadcast console command should never be called from the network thread, and the hook was indeed being called from the network thread (where the incoming block event came from). After a little bit of tinkering, I determined that the simplest approach was just to re-emit the incoming block event to the GUI thread, and then call updatequeuedtransactions from the GUI thread’s event.
Okay, so the groundwork is laid, now to actually implement a console command for name registration. In theory, this should be easy: it should consist of name_new, broadcast, name_firstupdate, and queuetransaction, right? Actually, things are a lot more complicated, because if any of the currency inputs to the name_firstupdate transaction get spent in the 12-block interval before it gets broadcasted, then the name_firstupdate will be rejected as a double-spend. Hypothetically, I could have fixed this by abusing the address-freezing functionality of Electrum, but there’s a better way: pure name transactions.
Pure name transactions are a highly interesting form of Namecoin transaction, where currency is embedded inside a name instead of being kept in a separate input/output. This works because the 0.01 NMC cost of registering a name is actually enforced as a minimum amount of a name output, not an exact amount. You can put, for example, 0.03 NMC into a name output, and you can later withdraw the excess 0.02 NMC by spending that name output. As long as the amount never drops below the 0.01 NMC minimum, the Namecoin consensus rules don’t care. There are two major use cases for pure name transactions:
- Reducing transaction size. Obviously, 1 input and 1 output will yield a smaller transaction than 2 inputs and 2 outputs, which reduces blockchain bloat and transaction fees. (As far as I know, this use case was first described in a discussion at ICANN58 about Namecoin scalability.)
- Keeping coins organized. If you’ve ever tried to renew more than 25 names in Namecoin Core at once, you might have noticed that you got an error about a long chain of unconfirmed transactions. This happens because each renewal uses a currency input that’s the currency output of the previous renewal, forming a long chain of transactions. The Namecoin Core error happens because Namecoin Core considers it risky to have a chain of more than 25 unconfirmed transactions (if the first one never got confirmed, all the others would be stuck too). However, with pure name transactions, each name has its own currency coins, which are temporarily earmarked for use with that name, so operations with different names can’t interfere with each other.
The latter use case is what we’ll use here. We create a name_new transaction with no currency outputs, but whose name output has an extra 0.005 NMC attached to it. When we create the name_firstupdate transaction, we instruct Electrum-NMC’s coin selection algorithm to only use the name_new input, and to pay any fees out of the extra 0.005 NMC. (Coincidentally, I’m pretty sure that Mikhail’s Namecoin-Qt client, from the era before Namecoin Core, did the same thing.) As a result, we can be confident that no accidental double-spends will occur, because we definitely won’t be spending the name_new output before we broadcast the name_firstupdate transaction. Interestingly, making this work actually needed some minor changes to the Electrum-NMC coin selection algorithm, because parts of the coin selector are not designed to work properly with zero currency inputs being selected. (Which is understandable, since such a transaction would never be possible in Bitcoin.)
With that, we have a single console command, name_autoregister, which does what we want, so now it’s time to create a GUI for it. This was relatively uneventful, but it’s notable that I decided to have a separate Buy Names tab instead of putting the registration widgets on the existing Manage Names tab. The reasoning for this is that the Buy Names tab is a convenient place to show other widgets that don’t exist yet, such as giving you the opportunity to atomically trade NMC for a name if the name you want is already registered.
And now, here’s your regular fix of screenshots:
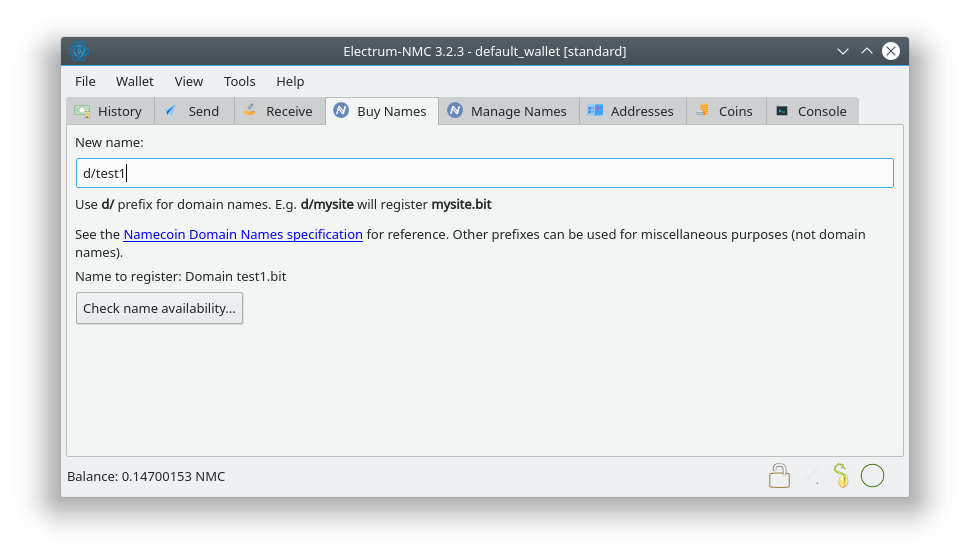
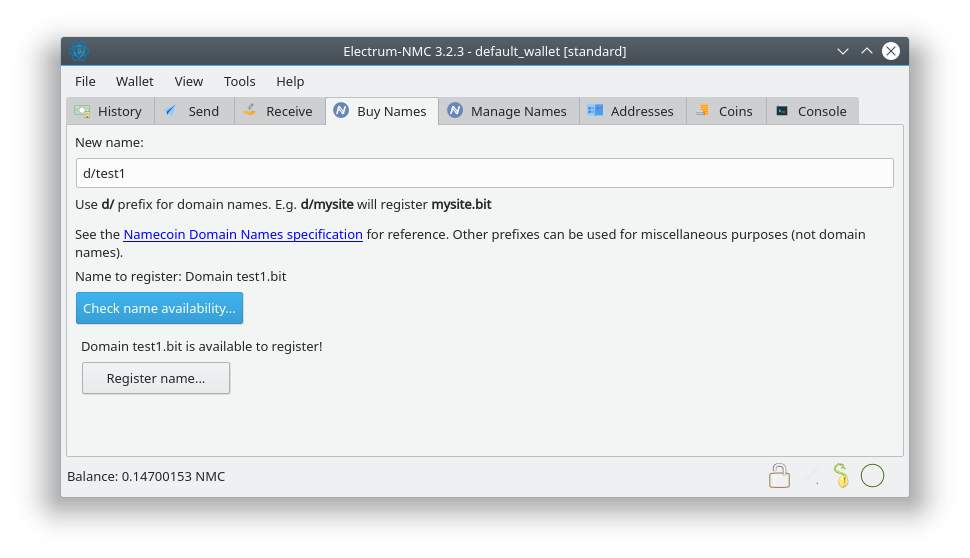
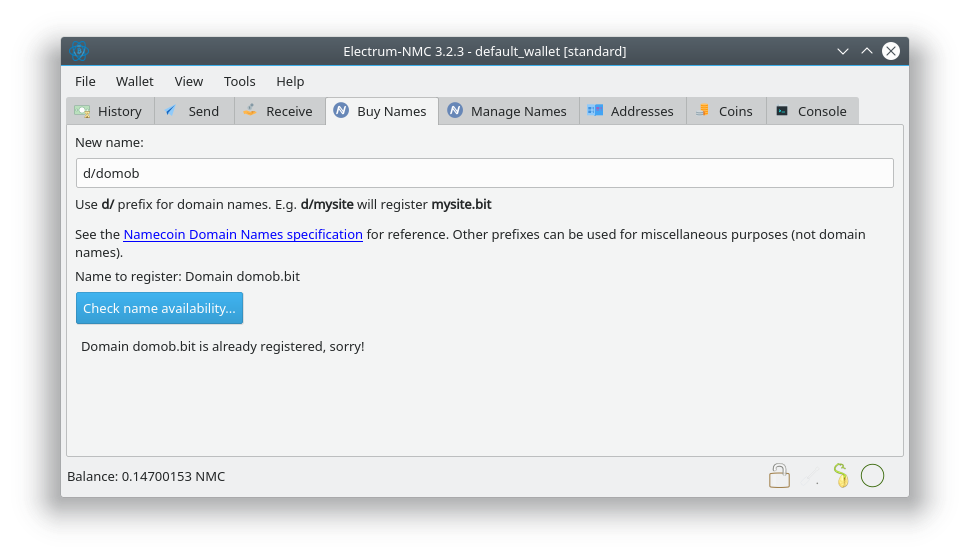
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
NSS certutil Windows/macOS rbm Build Scripts Merged by The Tor Project
As I mentioned earlier, I submitted some patches to The Tor Project for building NSS certutil binaries for Windows and macOS as part of Tor Browser’s rbm build scripts. I’m happy to report that after a (quite well-justified) delay, and after some (quite reasonable) mild edits were requested and made, the Tor developers have merged my patches.
This has benefits to multiple parties. It benefits Namecoin since it means we get trustworthy certutil binaries for our Namecoin TLS releases [1]. It benefits the broader NSS ecosystem on Windows and macOS, since (among other things) it means that Firefox users on Windows and macOS won’t need to download random binaries linked from StackExchange or forums, or self-compile NSS, just in order to add certificates to their trust store from the command line. (Based on the number of such forum threads I found via a cursory web search, there are a lot of such users.) It benefits Tor, since it means that users who wouldn’t otherwise be interacting with the Tor ecosystem will now have a reason to do so, which gives Tor some free publicity. And it benefits the reproducible build ecosystem, because many users who previously assumed they’d either have to risk downloading malware or build from source will now be learning about the benefits of reproducible builds for the first time (and will hopefully start demanding similar security guarantees from the developers of other software they use).
This is why, at Namecoin, we try to get our work upstreamed as much as possible – we aim for maximum public benefit across the ecosystem, rather than maintaining forks of software for our own limited use cases. Kudos to the Tor devs for the excellent code review experience. I’m looking forward to getting more patches upstreamed to Tor in the future.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Of course, this is partially negated by the fact that some ongoing R&D happening at Namecoin suggests that we may be able to ditch the certutil dependency, in favor of some other approaches with less attack surface. But I’ll save that for another post.
Electrum-NMC: Name Update GUI
I previously wrote about creating name transactions in the Electrum-NMC console. Next up, adding GUI support.
The new Renew Name and Configure Name... buttons use the previously discussed name_update command as their backend, which makes implementation relatively simple, since it’s not difficult for GUI functions to access console commands. I facilitated the Renew Name command by making the value parameter of name_update optional; if not supplied, it will be set to the current value of the name.
However, this introduces an interesting attack scenario: if an ElectrumX server falsely reports the current value of a name you own and you click the Renew button, you would be tricked into signing a name_update transaction that contains the malicious value. Therefore, to mitigate this scenario, value is only optional if the latest transaction for the name has at least 12 confirmations. I can’t picture any way that this mitigation would cause real-world UX problems; presumably no one wants to renew a name that was already last updated fewer than 12 blocks ago.
One nice UX improvement in Electrum-NMC compared to Namecoin-Qt is that you can renew multiple names at once: just select more than one name in the Manage Names tab, and then click Renew Name. Implementing this was a bit tricky, because Electrum’s coin selection algorithm doesn’t normally notice that a coin has been spent until it receives a copy from the ElectrumX server, which is usually a few seconds after we broadcast it to the ElectrumX server. As a result, the coin selection algorithm would try to double-spend the same currency input for each name renewal. I fixed this by calling addtransaction(tx) (which adds a transaction to the wallet) immediately after broadcast(tx) returns success, before moving on to the the next name to renew.
It should be noted that renewing multiple names at once will probably reveal to blockchain deanonymizers that the affected names have common ownership. So, while this feature is potentially useful, it should be used with care.
The Configure Name... button and associated dialog were relatively uneventful in terms of bugs. That said, it did occur to me that it might be better to re-use Namecoin-Qt’s .ui form files for this purpose instead of re-implementing the dialog in Python. Unfortunately, Namecoin-Qt’s form files are a bit too specific to Bitcoin Core (e.g. they incorporate widgets that only exist in Bitcoin Core, which have different implementations in Electrum). I think it would be plausible to improve the abstraction of Namecoin-Qt’s form files so that we could re-use them in Electrum-NMC and save on duplicated GUI effort; hopefully something will happen there after higher-priority tasks are dealt with in the Namecoin-Qt codebase.
And now, screenshots!
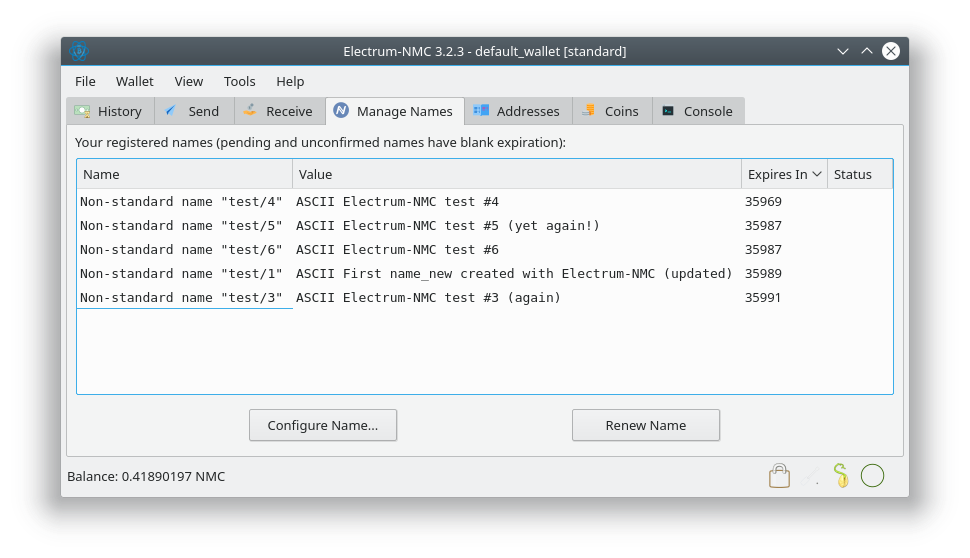
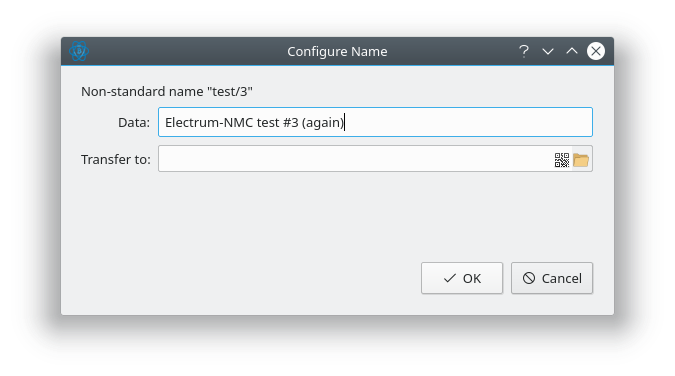
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC: Name Transaction Creation
In a previous article, I wrote about the “reading” side of Electrum-NMC’s name script support (i.e. detecting and displaying name transactions in the wallet, and doing name lookups). Obviously, the logical next step is the “writing” side, i.e. creating name transactions.
I started out by trying to implement name_new. Electrum’s command API is quite flexible (yet quite user-friendly), so most of the relevant functionality was fairly straightforward to implement by adding slight modifications to the existing transaction creation commands. These modifications essentially just add an extra output to the transaction that has a non-null name operation. I did, however, need to add some extra functionality to the accounting, to adjust for the fact that a name_new transaction destroys 0.01 NMC by permanently locking it inside an output. (Usually, it’s desirable to treat that locked namecent as zero for display purposes, but when funding a transaction, treating it as zero would produce Bad Things ™.)
Electrum’s API philosophy differs from that of Bitcoin Core, in that while Bitcoin Core wallet commands tend to broadcast the result automatically, Electrum wallet commands tend to simply return a transaction, which you’re expected to broadcast with the broadcast command. I’m following this approach for the name wallet commands. Creating the name_new transaction completed rather easily without errors; however, when I tried to broadcast the name_new transaction, it was rejected by my Namecoin Core node that serves as the backend for my ElectrumX instance. I inspected my Namecoin Core node’s debug.log, and quickly found the issue: I had forgotten to set the transaction’s nVersion field to the value that permits name operations. Namecoin requires all name operations to appear in transactions with an nVersion field of 0x7100, which is a value that doesn’t show up in Bitcoin at all. I decided not to modify the transaction construction API’s in Electrum to allow manual setting of the nVersion field per command (end users don’t want to think about these details), and instead decided that it was easier to simply add a couple of lines to the Transaction class so that if you supply it with an output that has a name operation attached to it, the resulting transaction will automatically have its nVersion modified.
With that fix, I could create name_new transactions and broadcast them. I sent a name_new from Electrum-NMC to my Namecoin Core wallet and also created one that stayed within Electrum-NMC. The underlying logic here was two-fold: (1) I wanted to make sure that both explicitly-specified recipient addresses and automatically-generated local addresses worked properly, and (2) if an issue happened while trying to spend the name_new outputs with Electrum-NMC, I wanted to be able to quickly compare the results with Namecoin Core so that I would know whether the problem was with the code trying to spend the output or with the code that created the output.
While both name_new transactions were reaching their required 12 blocks of confirmations, I implemented name_firstupdate support. This was a little bit more interesting, because it meant I had to explicitly add a mandatory name input (the name_new) in addition to a mandatory name output (the name_firstupdate). Electrum makes it very easy to add mandatory outputs, since that’s commonplace in Bitcoinland. Adding mandatory inputs, however, is not exactly straightforward. I ended up modifying a few of the coin selection algorithms to allow specifying mandatory inputs that would be applied before any other inputs are added, and while I wish it could be done with fewer changes, I’m reasonably happy with the result.
Creating the name_firstupdate transaction was relatively easy to do from Electrum-NMC without errors. Unfortunately, once again the transaction was rejected by my ElectrumX instance’s Namecoin Core node. This time the error was a lot less intelligible; the error had something to do with the signature check failing, but it wasn’t clear to me exactly what the problem was. To narrow down the issue, I tried spending the name_new that I had sent to my Namecoin Core wallet into a name_firstupdate, and that one worked fine. So clearly the issue was in the name_firstupdate code in Electrum-NMC, and not anything broken in the name_new that was already created. I ended up copying the invalid transaction into Namecoin Core’s decoderawtransaction RPC method, and then pasting the hex-encoded script into Bitcoin IDE to simulate exactly what was happening. And it definitely was clear that something was wrong: the hash that the signature signed didn’t match the hash it was supposed to be signing.
This seemed rather weird, since I hadn’t touched any of the signature code. After some grep-fu of the Electrum codebase, I figured out what had happened. In Bitcoin transactions, the signatures cover the scriptPubKeys of the previous transaction outputs. This shouldn’t be a problem, but Electrum tries to be clever in order to avoid actually looking up the previous transactions. Electrum actually guesses the previous scriptPubKey based on the scriptSig. This actually works fine for the transaction types that one normally finds in Bitcoinland. However, in Namecoin, name operations are prefixed to the scriptPubKey, and nothing about that name prefix (even whether one exists at all) can be inferred from the scriptSig that spends the name output. As a result, the previous scriptPubKey that was being signed didn’t have a name prefix at all, which of course caused the hashes to mismatch.
Modifying the wallet code to pass through name operations to the data structures that the scriptPubKey-guessing code has access to wasn’t particularly painful, nor was modifying the scriptPubKey-guessing code to prefix the correct name script when needed. With that out of the way, a name_firstupdate from Electrum-NMC was able to broadcast successfully.
name_update was comparatively simple. The main change needed for this one was that while name_firstupdate specified the mandatory name input by TXID, name_update specifies it by name identifier. Adding this functionality to the coin selection algorithms wasn’t particularly unpleasant. And thus, I was able to create and broadcast a name_update transaction as well. Yay!
The next future step is probably to hook these commands into the GUI.
And, with that out of the way, here are some transactions I created with Electrum-NMC’s console:
name_newcreated by Electrum-NMC, sent to Namecoin Corename_firstupdatecreated by Namecoin Core, spending thename_newcreated by Electrum-NMCname_firstupdatecreated by Electrum-NMCname_updatecreated by Electrum-NMC
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
Halving Day (Block 420000)
Block number 420000 (hash 145f72ea59018ca4117015e3c25a2ed24e22e67c948841dd46a200db11d778be) was mined at 2018-10-04 01:10:19 +0000 by Slush Pool with a block reward of 12.5 NMC plus fees. From all of us at Namecoin, Happy Halving Day, everyone!
Electrum-NMC: Name Script Deserialization (Round 2: Name History Display, Name Lookups, and Manage Names Tab)
I previously wrote about some work on making Electrum-NMC handle name scripts. In the last few days I hacked on that code some more.
As you may have noticed from the screenshot in the previous article, I’m initially testing this code with watching-only wallets, since there are fewer moving parts there and I don’t have to worry about constructing and signing transactions. When looking for addresses to add to the watching-only wallet, I usually just look through the Cyphrs block explorer and take the first few name transactions that show up of each desired type. Interestingly, I noticed that a subset of the name transactions I picked from the explorer this time weren’t visible in the Electrum-NMC GUI. Some querying of my ElectrumX server indicated that the transactions were definitely being delivered to Electrum-NMC, and inspecting Electrum-NMC’s wallet file showed that the transactions were definitely being added to the wallet. But for some reason, Electrum-NMC wasn’t displaying them.
After quite a lot of tracing through the code, I figured out that the transactions in question had name scripts that weren’t successfully being recognized as name scripts. Some more tracing led me to figure out that the code was failing to parse any name_anyupdate script whose value was the empty string. Turns out that upstream Electrum has a wildcard-like script matching function that can detect arbitrary data pushes (which I was using) – but for some reason they don’t treat OP_0 as a data push for the purpose of that wildcard matching. Pushing the empty string to the stack is implemented by… you guessed it, OP_0. I filed a GitHub issue with upstream Electrum about this, and it looks like they’ve fixed it upstream (quite quickly, too). While I was waiting for them to fix it, I did implement a (very hacky) workaround in Electrum-NMC’s name script parser, but that workaround will most likely be removed (yay!) when I next merge from upstream Electrum. Kudos to the upstream Electrum devs on this; they’ve consistently been quite helpful (and quick) at implementing fixes that make life easier for downstream projects like Electrum-NMC.
I had previously implemented some special UI code for displaying that a name transaction is a transfer operation. This is a UX improvement over Namecoin Core, which confusingly displays both incoming and outgoing name transfers identically to name updates. I had defined a name transfer as “a name transaction for which the wallet owns a name input XOR the wallet owns a name output”. Do you see a problem here? Yeah, that definition matches all name_new transactions where the wallet owns the output, because name_new transactions don’t have a name input. D’oh. Fixed that.
Up next was displaying the name identifiers in the UI. Again, I’m trying to improve on Namecoin Core’s UX here. For example, I prefer to make d/wikileaks show up as wikileaks.bit. My code also recognizes invalid d/ names, e.g. names with uppercase characters, and indicates that they’re not valid domain names. Ditto for id/ names. In addition, if the namespace is unknown or the identifier isn’t valid under the namespace rules, I actually check whether the identifier consists entirely of ASCII printable characters. If it does, I print it in ASCII; if it doesn’t, I print it in hex. Similar checks are in place for values. The Namecoin consensus rules have always allowed binary data to exist in identifiers and values, but the UI for this functionality was pretty much always missing. Electrum-NMC should handle this kind of thing without trouble. One practical example of how this could be used in the future is storing values as CBOR rather than JSON. CBOR is substantially more compact, especially when encoding binary data like TLS certificates, which means moar scaling and moar savings on transaction fees. (CBOR also seems to be a common choice by the DNS community, including people at IETF and ICANN.)
Then, I implemented the name_show console command. For readers unfamiliar with the Namecoin Core RPC API, name_show is the command that .bit resolvers like ncdns use to look up name data from Namecoin Core and ConsensusJ-Namecoin. My name_show implementation in Electrum-NMC includes SPV verification, just like Electrum’s history tab. Every output JSON field from Namecoin Core is present, although currently none of the optional input fields are supported. It probably wouldn’t be very difficult to hook this into ncdns. However, it should be noted that Electrum’s SPV verification is a weaker security model than ConsensusJ-Namecoin’s leveldbtxcache SPV security model. In addition, there’s only one public Namecoin ElectrumX server instance, so the concept of the “chain with most work” isn’t exactly meaningful. Even so, it’s vastly more secure than centralized inproxies like OpenNIC, and it might be useful for some people. Hopefully more people will step up to run public Namecoin ElectrumX servers so that the SPV security model can actually work as intended.
Finally, I implemented a first pass at the Manage Names tab. Display of the name identifier, value, and expiration block count are working. This was a lot easier than implementing from scratch would be, because the Manage Names tab (referred to in the code as the UNO List widget) is actually just a subclass of the Coins tab (referred to in the code as the UTXO List widget).
So, with that explanation out of the way, here’s what you really came here for: screenshots!
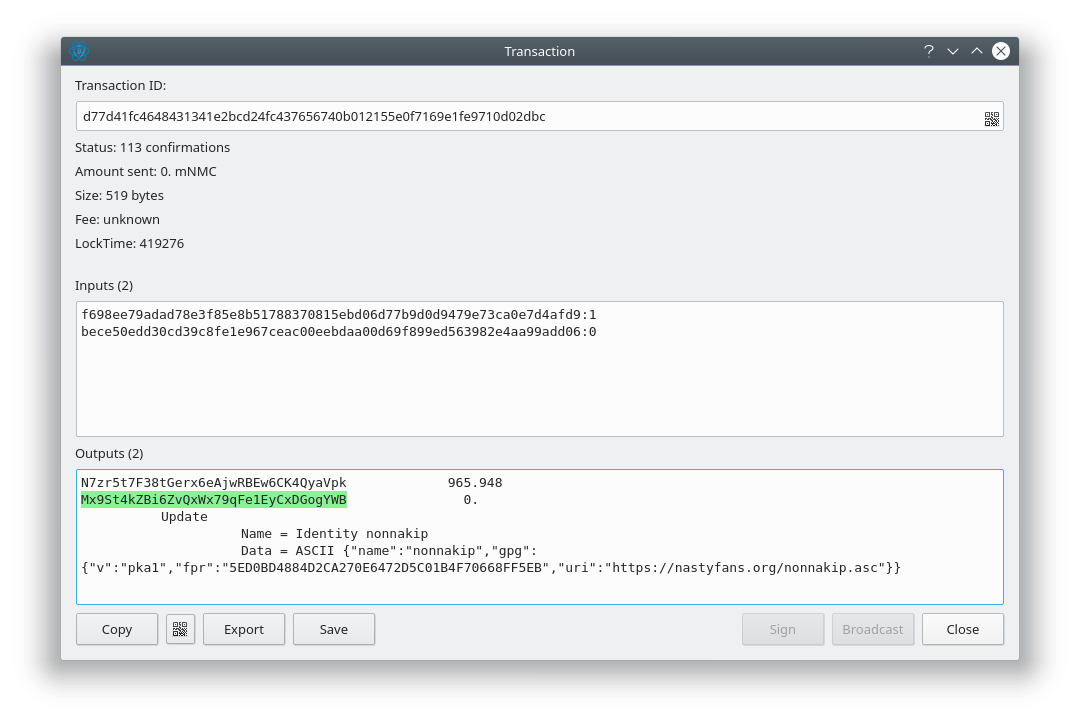
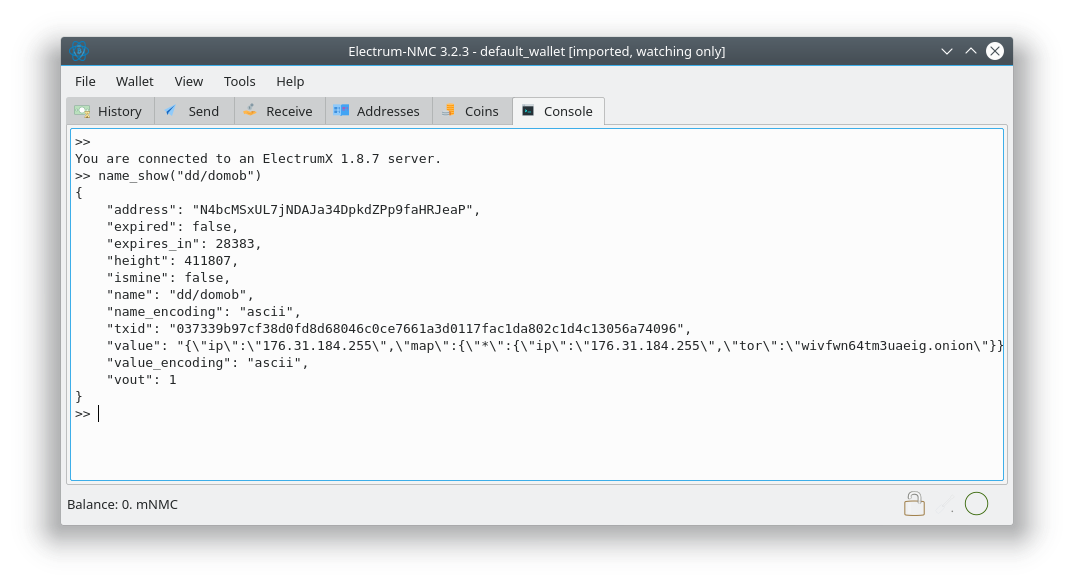
This work was funded by Cyphrs and NLnet Foundation’s Internet Hardening Fund.
NSS certutil Windows rbm Build Scripts Submitted Upstream to The Tor Project
Previously, I covered cross-compiling NSS certutil for Windows via Tor’s rbm build scripts. Since I like to be a good neighbor, I’ve since reached out to the very nice people at Tor, and have submitted a patch to get this merged upstream. I’ve already received a Concept ACK, although they cautioned me that they’re quite busy with other Tor Browser things at the moment and it may take a while for them to review my patch. The Tor people requested that I consider adding macOS support as well; I’ve done so and that patch is also submitted to Tor for review.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
How Centralized Inproxies Make Everyone Less Safe (A Case Study)
Readers who have followed Namecoin for a while know that I’ve been sharply critical of centralized inproxies since I joined Namecoin development in 2013. For readers who are unfamiliar with the concept, a centralized inproxy is a piece of infrastructure (run by a trusted third party) that allows users who aren’t part of a P2P network to access resources that are hosted inside that P2P network. You can think of it as analogous to a web wallet in the Bitcoin world, except that whereas web wallets are for people who own .bit websites, centralized inproxies are for people who view .bit websites. Centralized inproxies introduce security problems that are likely to be obvious to anyone familiar with the history of Bitcoin web wallets (I’m among the people who were around when MyBitcoin existed but refused to use it; we were proven right when MyBitcoin exit-scammed).
However, for reasons that elude me, the concept of centralized inproxies seems to have an irritatingly persistent set of proponents. It’s rare that a month goes by without having some rando on the Internet ask us to endorse, collaborate with, or develop a centralized inproxy (it’s only the 18th of this month as I write the first draft of this article, and it’s already happened twice this month). I’ve personally been accused of trying to kill Namecoin via stagnation because I don’t support centralized inproxies. The degree to which the advocacy for centralized inproxies is actually organic is dubious at best (there is evidence that at least one particularly loud and aggressive proponent of the concept has been motivated by undisclosed financial incentives). However, regardless of how inorganic it may be, we encounter the request often enough that we actually added an entry to our FAQ about why we don’t support centralized inproxies. In this post, I’d like to draw attention to the “Security concerns” section of that FAQ entry, specifically the 3rd bullet point:
- ISP’s would be in a position to censor names without easy detection.
- ISP’s would be in a position to serve fraudulent PKI data (e.g. TLSA records), which would enable ISP’s to easily wiretap users and infect users with malware.
- Either of the above security concerns would even endanger users who are running Namecoin locally, because it would make it much more difficult to detect misconfigured systems that are accidentally leaking Namecoin queries to the ISP.
The 3rd bullet point is intended as a debunking of the disturbingly common claim that “The security drawbacks only affect users who have opted into the centralized inproxy, and we would encourage users who care about security to install Namecoin locally.” Even though I’ve been citing this concern for years, I had mostly been citing it in the sense of “This is going to burn someone eventually if centralized inproxies become widespread”; I hadn’t been citing it in the sense of “I personally have seen this happen in the wild.”
Which brings us to a case study that I accidentally initiated recently.
I was recently setting up a VM for Namecoin-related testing purposes. In particular, this VM was to be used for some search-engine-related research (those of you who saw my science fair exhibit at the 2018 Decentralized Web Summit will be able to guess what I was doing). I have a relatively standard procedure for setting up Namecoin VM’s, but admittedly I don’t do it very often. I was particularly rusty in this case because I usually set up a Namecoin VM in Qubes/Xen, while this time I was using Debian/KVM (this is because my search engine needed a lot of RAM, meaning it was running on my Talos, and Qubes/Xen doesn’t run on the Talos yet). Somehow, I managed to goof up the setup of the VM, and Namecoin resolution wasn’t actually running on it when I thought it was. However, at the time I didn’t know this; it definitely looked like Namecoin was working. I proceeded to do my search engine testing, and eventually (after about 30 minutes of clicking .bit links continuously) I noticed something odd. I had clicked on a .bit link that I recalled (from previous testing many months prior) was misconfigured by the name owner, and therefore didn’t work in standards-compliant Namecoin implementations – but the name in question did work in buggy inproxies like OpenNIC. And, lo and behold, the link loaded without any errors in my VM. My initial impression was to figure that maybe the name owner finally got around to fixing their broken name. But I was curious to see when the change had been made, so I checked the name in the Cyphrs block explorer to see the transaction history of the name. Hmm, that’s odd, no such fix ever was deployed.
At this point, I was suspicious, so I started testing my network configuration. And I discovered, to my surprise, that my .bit DNS traffic wasn’t being routed through ncdns and Namecoin Core – a network sysadmin upstream of my machine’s network connection had set their DNS to use OpenNIC’s resolver, and my .bit DNS traffic was being resolved by OpenNIC.
Let’s look at some mitigating factors that helped me notice as quickly as I did:
- I was visiting a wide variety of
.bitsites from that VM; most users won’t be visiting many.bitsites. - I already had memorized a few
.bitdomains that had a broken configuration, and already knew that OpenNIC had incorrect handling of that broken configuration; most users have no idea how to identify a broken domain name configuration on sight (and certainly won’t have memorized a set of domains that have such configurations), and won’t have any knowledge of whatever obscure standards-compliance quirks exist in specific inproxy implementations. - I knew how to use a block explorer as a debugging tool; most users of Namecoin don’t use block explorers, just like most users of the DNS don’t use DNS “looking glass” tools.
- I was able to walk down the hall to check with the network sysadmin, and knew exactly what question to ask him: “Is your network using OpenNIC’s DNS resolvers?” Most users have never heard of OpenNIC, nor would they have any idea to ask such a question, nor would they necessarily be able to easily contact their network sysadmin, nor would they necessarily have a network sysadmin who would know the answer.
Despite these substantial mitigating factors, it took me at least a half hour to notice. That’s half an hour of web traffic that was trivially vulnerable to censorship and hijacking. Would a typical user notice this kind of misconfiguration within a month? I’m skeptical that they would.
Now consider the threat models that a significant portion of the Internet’s users deal with. For many Internet users (e.g. activists and dissidents), having the government be able to censor and hijack their traffic for a month without detection can easily lead to kidnapping, torture, and death. There is a strong reason why the .onion suTLD designation requires that DNS infrastructure (in particular, the ICANN root servers) return NXDOMAIN for all .onion domain names, rather than permitting ICANN or DNS infrastructure operators to run inproxies for .onion. That reason is that it is important for users of misconfigured systems to quickly notice that something is broken, rather than to have the system silently fall back to an insecure behavior that still looks on the surface like it works. IETF and ICANN are doing exactly the right thing by making sure that .onion stays secure so that at-risk users don’t get murdered. The draft spec for adding .bit as a suTLD (along with I2P’s .i2p and GNUnet’s .gnu) made the same guarantees (and ICANN is currently doing the right thing for .bit by not having allocated it as a DNS TLD).
For me, the experience of accidentally using a centralized inproxy was primarily a waste of under an hour of my time, and a bit of embarrassment. (Also, my network sysadmin promptly dropped OpenNIC from his configuration when I told him of the incident.) But I hope that the community can take this as a learning opportunity, to better appreciate the inevitability of something catastrophic eventually happening if centralized inproxies are allowed to proliferate. Let’s not be the project that ends up getting one of our users killed as collateral damage in a quest for rapidly-deployed ease-of-use.
Namecoin Core 0.16.3 Released
Namecoin Core 0.16.3 has been released on the Downloads page.
ConsensusJ-Namecoin v0.3.1 Released
We’ve released ConsensusJ-Namecoin v0.3.1. Here’s what’s new:
- Some of the Namecoin-specific code has been merged upstream to ConsensusJ, and has therefore benefited from more peer review.
- Improvements from upstream ConsensusJ.
As usual, you can download it at the Beta Downloads page.
Electrum-NMC v3.2.2.2 Released
We’ve released Electrum-NMC v3.2.2.2. Here’s what’s new:
- Fix exchange rate display.
- Fix a few places where the UI still said “Bitcoin” instead of “Namecoin”.
- Building for macOS might work now (no official macOS binaries yet, though).
- Code quality improvements.
- Build script fix from upstream Electrum.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ncdns v0.0.8 Released
We’ve released ncdns v0.0.8. But the previous release was v0.0.6, what happened to v0.0.7, you ask? Well, since we’re a human rights project, we didn’t want to stain our release with a reference to the criminal organization that overthrew the democratically elected Iranian government, so v0.0.7 got skipped. [1] List of changes in v0.0.8:
- TLS interoperability:
- Firefox TLS certificate positive overrides via
cert_override.txtare now built into ncdns; manually runningncdumpzoneis no longer needed. Some config file settings must be set manually for this to work.
- Firefox TLS certificate positive overrides via
- DNS interoperability:
- Fix support for DNAME records (AKA the Namecoin
translatefield) in madns / ncdns.
- Fix support for DNAME records (AKA the Namecoin
- Tor interoperability:
- Fix support for DNAME records (AKA the Namecoin
translatefield) indns-prop279.
- Fix support for DNAME records (AKA the Namecoin
- Tools:
generate_nmc_cert: Rebase against Go v1.8.3 standard library.generate_nmc_cert: Use P256 curve by default.ncdumpzone: Useeasyconfiginstead ofkingpin; this allows config files to be used withncdumpzone.
- Windows:
- Upgrade dnssec-keygen to v9.13.2.
- Upgrade DNSSEC-Trigger to v0.17.
- Fix default
$APPDATApath for Namecoin Core. This should fix a bug where Namecoin Core would crash with a permission error on 2nd run if Namecoin Core was installed for the first time via ncdns. - Disable cookie authentication when ConsensusJ-Namecoin is selected. This should fix a bug where ncdns couldn’t connect to ConsensusJ-Namecoin.
- Detect if Visual C++ 2010 Redistributable Package is missing. This should fix a bug where ConsensusJ-Namecoin would crash on startup.
- NetBSD:
- NetBSD/ARM binaries are now available again.
- Build system:
- Upgrade Go to v1.10.3.
- Miscellaneous:
- Many code quality improvements.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] Actually, I screwed up the release scripts and didn’t notice until after v0.0.7 was already tagged, so v0.0.7 was unreleaseable. But I like the above reason better.
ncdns NSIS Installer UX: Detection of Visual C++ 2010 Redistributable Package
If you’ve used ConsensusJ-Namecoin (our lightweight SPV name lookup client), you’ve probably noticed that we instruct users (on the Download page) to install the Microsoft Visual C++ 2010 Redistributable Package. Failing to do this will result in the LevelDB library failing to load, which ends up causing some incredibly misleading error messages, after which namecoinj-daemon will terminate. Unfortunately, in the Real World™, users don’t reliably follow instructions. (Confession: I’ve failed to follow this instruction when setting up test VM’s before, and took quite a while to figure out what was broken.)
But how to improve the UX here? Distributing the relevant package is legally questionable, so we can’t do that. However, an alternative is to make the ncdns NSIS installer (which handles user-friendly installation on Windows) detect whether the package is already installed, and display a more user-friendly error during installation so that users know what’s wrong and how to fix it.
We already handle this concept to some extent. For example, here’s what the NSIS installer displays when Java isn’t already installed:
Compare this to the typical display when Java is installed:
So, over the last day or so, I hacked on the ncdns NSIS script to make it detect the Microsoft Visual C++ 2010 Redistributable Package (like we already do for Java), and refuse to install ConsensusJ-Namecoin if it’s not found:
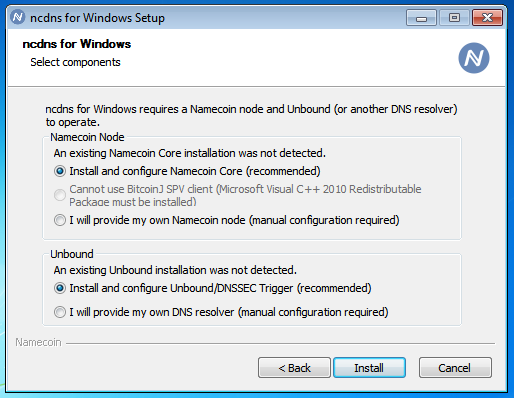
This was an excellent excuse for me to get some more experience with NSIS. Hopefully it saves some users from head-banging confusion.
(It should be noted, of course, that the “right way” to solve this is to actually make ConsensusJ-Namecoin not require any non-free Microsoft dependencies. This is something we’ll probably look into as we move towards reproducible builds. That said, Windows users are already trusting non-free Microsoft code, so this isn’t as big a deal as one might think.)
This work was funded by NLnet Foundation’s Internet Hardening Fund.
cross_sign_name_constraint_tool Drops Support for Go v1.9.x; Users Who Self-Built It With Go v1.9.x Should Update Immediately
cross_sign_name_constraint_tool, as you may remember, is a Namecoin-developed tool that applies name constraints to a certificate authority, without requiring any permission from that CA. It can be used to prevent malicious CA’s from issuing certificates for Namecoin domain names, even if those CA’s are trusted for DNS domain names. cross_sign_name_constraint_tool (or its underlying library) is used by other Namecoin projects, such as tlsrestrict_nss_tool (which integrates cross_sign_name_constraint_tool with the NSS cert store used by Firefox and the GNU/Linux version of Chromium) and ncdns (which will soon make tlsrestrict_nss_tool easy to use on Windows). cross_sign_name_constraint_tool’s official binaries are produced using Go v1.10.x. Recently, I happened to notice a bug in Go v1.9.x (which is fixed in Go v1.10.0 and higher) that causes cross_sign_name_constraint_tool to fail with an error like this:
Error generating cross-signed CA: Couldn't unmarshal original certificate: asn1: structure error: tags don't match (2 vs {class:0 tag:16 length:13 isCompound:true}) {optional:false explicit:false application:false defaultValue:<nil> tag:<nil> stringType:0 timeType:0 set:false omitEmpty:false} @21
The error only occurs with a small subset of CA certificates; the specific CA that triggered this error for me was Verisign Class 3 Public Primary Certification Authority - G3 (which is trusted by Fedora).
This bug doesn’t affect users of our official binaries, because the official binaries weren’t built with an affected Go version. My WIP ncdns PR for automatically integrating tlsrestrict_nss_tool would have made such an error very obvious: it causes ncdns to stop resolving .bit domains when such an error is observed, so there’s no risk to users from name constraints being incompletely applied. However, users who built their own cross_sign_name_constraint_tool or tlsrestrict_nss_tool using Go 1.9.x, and who failed to notice a prominent error message when running it, would potentially be left incompletely protected from the threats that cross_sign_name_constraint_tool is designed to protect against.
If you’re running a self-built cross_sign_name_constraint_tool or tlsrestrict_nss_tool that was built with Go 1.9.x, I strongly recommend that you rebuild with Go 1.10.x and re-apply your desired name constraints. I don’t have any reason to believe that any CA has exploited this in the wild. (Any CA who tried to exploit it would probably have been detected by certificate transparency.) And remember, cross_sign_name_constraint_tool is designed to protect against attacks that users of the DNS are completely vulnerable to – this bug is not a downgrade from the security model of the DNS. (Indeed, even with this bug, affected users were still protected from a random subset of their system’s trusted CA’s, so security in this aspect was still somewhat higher than that of the DNS.)
I’ve submitted a test case to cross_sign_name_constraint_tool, which will ensure that anyone who tries to build it with an affected Go version will receive a test failure. ncdns will also be updated to use Go 1.10.x prior to the release that integrates tlsrestrict_nss_tool.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC: Name Script Deserialization
I previously wrote about making ElectrumX (the server) handle name scripts. Now that that’s out of the way, the next step is making Electrum-NMC (the client) handle name scripts as well. I now have Electrum-NMC deserializing name scripts.
Most of the details of this work are fairly mundane implementation details that probably won’t interest most readers. So, instead, how about a screenshot?
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin’s Jeremy Rand will be at Decentralized Web Summit 2018
Namecoin developer Jeremy Rand will attend Decentralized Web Summit 2018 in San Francisco, July 31 - August 2, hosted by the Internet Archive. Namecoin will be at the Science Fair and will give a Lightning Talk (schedule TBA). We’re also open to meetups and hacking sessions independent of the official DWS schedule, so if you’re attending DWS (or if you’re in the SF area) and would like to chat or hack, get in touch with us! We’re looking forward to the Summit!
ElectrumX: Name Scripts
ElectrumX is the server component of Electrum. Unlike the client component, which requires forking to enable altcoins, ElectrumX has altcoin support by default, including Namecoin [1]. ElectrumX already supports the AuxPoW features of Namecoin (which is why only Electrum-NMC needed modifications for that), but name script support required some tweaks to ElectrumX.
The main issue here is that the Electrum protocol requires Electrum to supply scriptPubKey hashes to ElectrumX, for which ElectrumX will then reply with transaction ID’s. This works great when the scriptPubKey can be easily determined by the client (a Bitcoin address can be deterministically converted to a scriptPubKey), but in Namecoin, a scriptPubKey for a name output contains some extra data that Electrum-NMC won’t know ahead of time. Specifically, a name_update scriptPubKey includes the OP_NAME_UPDATE opcode, the name identifier, the name value, an OP_2DROP and OP_DROP opcode to empty the opcode, identifier, and value from the stack, and then a standard Bitcoin scriptPubKey that corresponds to the address that owns the name. (A name_firstupdate scriptPubKey contains even more stuff.) An Electrum-NMC client that wants to look up transactions by address won’t know the name identifier, and an Electrum-NMC client that wants to look up transactions by name identifier won’t know the address of the owner. As a result, we need to mess with things.
The approach I took was to tweak Namecoin’s altcoin definition in ElectrumX to do a few things:
- When hashing a scriptPubKey, first detect whether the scriptPubKey is a name script, and strip away the name script prefix if present. This leaves only a standard Bitcoin-style scriptPubKey that can be looked up via the standard Electrum protocol.
- Add a secondary method of hashing a scriptPubKey, which detects
name_anyupdatescripts, and rewrites them into a standard form that’s well-suited to name lookups (more on that below). - When indexing transactions, index the results of both the usual hashing method and the secondary method, so that we can reuse ElectrumX’s transaction index for both address lookups and name identifier lookups.
How does this standard form work? Here are the things it changes:
name_firstupdatescripts are converted toname_updatescripts; the extra data thatname_firstupdatescripts contain is stripped.- The name value is replaced with an empty string. (Technically this means that we use
OP_0instead of the usual push operation.) - The Bitcoin-style scriptPubKey after the
OP_DROPis replaced withOP_RETURN. (Technically this would be interpreted as an unspendable scriptPubKey.)
What are the advantages of this approach?
- Name scripts can be looked up by identifier using the standard Electrum protocol commands; no changes to Electrum’s protocol are needed.
name_firstupdateandname_updatecan both be looked up by the same Electrum protocol command.- The scripts being hashed are unambiguously name scripts, and are not going to appear by accident in other contexts. It is, of course, certainly possible to deliberately produce a name script whose address is another name script followed by
OP_RETURN, but Electrum’s protocol isn’t intended to prevent deliberate collisions anyway. Any such weird transactions will be detectable when they’re downloaded by Electrum-NMC, just like other colliding scripts. UsingOP_RETURNas the scriptPubKey also makes it expensive for spammers to produce such collisions, because it means you need to destroy a name (thereby forfeiting your name registration fee) for each collision that you produce. - The script hash doesn’t trivially reveal what name is being looked up; it only reveals a hash. This improves privacy and security when the name being looked up doesn’t actually exist yet in the blockchain (e.g. if you’re checking whether a name you want to register already exists). It should be noted, however, that constructing a rainbow table for this hash function is straightforward, so if it’s critical that the names you’re looking up not be revealed to the ElectrumX server, you’re better off doing lookups via ConsensusJ-Namecoin’s
leveldbtxcachemode instead of the Electrum protocol. On the other hand, ElectrumX can’t actually determine whether the names being looked up are being used for DNS resolution or for registration purposes, so this might disincentivise ElectrumX servers from trying to frontrun registrations, since there’ll be a hell of a lot of noise from DNS-resolution-sourced lookups.
Generally speaking, ElectrumX’s altcoin abstractions were very pleasant to work with (kudos to Neil Booth and the other ElectrumX contributors on this!), and making these changes wasn’t too hard. Test results:
- ElectrumX takes noticeably longer to sync from Namecoin Core with these changes, but in practical terms the difference isn’t a problem: it’s 33 minutes instead of 12 minutes on my Talos II. (There might be ways to optimize the speed; I haven’t tried to do any optimizations yet.)
- Looking up name transaction ID’s by address can be done via the Electrum-NMC console with no changes to Electrum-NMC.
- Looking up name transaction ID’s by name identifier can be done via the Electrum-NMC console via the (present in upstream but undocumented)
network.get_history_for_scripthashcommand. However, this requires manually constructing a standard-form scriptPubKey hash from the name identifier, which isn’t exactly a fun process for those of us who don’t consider Bitcoin script as a native language. - Looking up unconfirmed name transactions doesn’t yet work, because my patch to ElectrumX doesn’t yet cover the UTXO index, only the history index. I haven’t tried to fix this yet, and I might not bother for a while, since unconfirmed name transactions aren’t really trustworthy unless you’re verifying signatures relative to older transactions for that name (such a technique was first proposed years ago by Ryan Castellucci, but to my knowledge no one has actually deployed it yet).
- The procedure for obtaining full transactions from transaction ID’s, and for obtaining Merkle proofs for those transactions, is considered out of scope for this work, because Electrum’s protocol already supports this, and shouldn’t need anything name-specific. However, it might be interesting to combine those commands with the script hash lookup commands into a single wire protocol command to reduce latency (an interesting area of future work).
- The procedure for parsing name transactions (either for wallet or name lookup purposes) after ElectrumX returns them is considered out of scope for this work, because that should be done by Electrum-NMC; this work only covers changes to ElectrumX. The needed changes to Electrum-NMC will come later.
I intend to submit these changes to upstream ElectrumX as a PR.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] I actually don’t like to refer to Namecoin as an “altcoin”, since the term means an “alternative” to Bitcoin, and Namecoin doesn’t aim to achieve any of the use cases that Bitcoin does. However, on a purely technical level, the process of adding Namecoin support to ElectrumX wasn’t any different from most altcoins such as Dogecoin, so the umbrella of “altcoin support” does include Namecoin, as much as I dislike the public-relations implications of that label.
Electrum-NMC v3.2.2 Released
We’ve released Electrum-NMC v3.2.2. Here’s what’s new:
- Trezor support.
- Support AuxPoW and timewarp hardforks. (AuxPoW is still experimental, but it does successfully sync now.)
- Fix running the GNU/Linux release without installing first.
- Improvements from upstream Electrum.
Please note that due to a bugfix that was needed for Trezor support, any coins stored in wallets from older versions of Electrum-NMC will probably be inaccessible from this version. We recommend that you empty your old Electrum-NMC wallets into Namecoin Core prior to installing this version, and then recreate your Electrum-NMC wallets after installing this version.
As usual, you can download it at the Beta Downloads page.
This work was funded by Cyphrs.
Electrum-NMC: AuxPoW Verification
Previously, I covered AuxPoW deserialization in Electrum-NMC. The next steps are on-disk serialization/deserialization, and verifying the deserialized AuxPoW. These are now implemented.
It turned out that on-disk serialization/deserialization was a lot easier than anticipated, because Electrum only writes headers to disk after they’ve been verified, and it never reverifies them. So it was sufficient to simply strip the AuxPoW portion of the headers prior to writing them to disk, and to tweak the header deserialization code so that it won’t error when it encounters AuxPoW-enabled headers that don’t have AuxPoW data (this is secure since even if such headers are successfully deserialized, they would never pass verification if verification were attempted).
Next up, AuxPoW verification!
AuxPoW verification code was already present in Electrum-DOGE, and it was relatively straightforward to port over to the current Electrum codebase. In the process, however, I noticed that Electrum-DOGE has a dependency on a library called btcutils. I can’t find that library’s source code on GitHub, nor does the PyPI page indicate a Git repository, an issue tracker, or even a license. At worst, this might indicate a GPL violation in Electrum-DOGE; at best, this indicates that the library has probably never been audited and is unwise to rely on. As a result, I re-implemented from scratch the single function in that library that Electrum-DOGE was using.
After implementing AuxPoW verification in Electrum-NMC, I received a bits mismatch error during blockchain verification (some time after AuxPoW activated). This was, of course, due to the “time warp” difficulty retargeting hardfork that Namecoin adopted long ago. (Since I was the author of the time warp hardfork support in libdohj, fixing this in Electrum-NMC was quite straightforward.)
Next, I noticed that verification of AuxPoW headers was incredibly slow. Some use of profiling tools revealed a number of bottlenecks (mostly relatively boring stuff like unneeded hex/binary conversions and unneeded copy operations), which I fixed.
At this point, I decided to do a full sync from scratch to see if it verified the entire blockchain. Unfortunately, it failed at chunk 77, due to an error from the ElectrumX server indicating that the response exceeded the server’s configured 5 MB limit. I infer that there were a bunch of unusually large Bitcoin coinbase transactions around that point in Bitcoin’s history. Luckily, the operator of the public Namecoin ElectrumX server quickly replied to my email and raised the limit. At this point, Electrum-NMC was able to fully sync.
In terms of performance, Electrum-NMC on my Talos II is able to sync from scratch in about 6 minutes, without using any checkpoints (other than the genesis checkpoint).
Since Namecoin is a good neighbor, I’m maintaining an auxpow branch in the Electrum-NMC Git repository, which is identical to upstream Electrum except that AuxPoW support is added. This may be useful to other AuxPoW-based cryptocurrencies who want a starting point for porting Electrum to their cryptocurrency. (Daniel already does something similar for Namecoin Core.)
It should be noted that I haven’t carefully audited the components inherited from Electrum-DOGE, so the AuxPoW support in Electrum-NMC should not be relied on in critical applications – it would not be surprising if Electrum-DOGE’s AuxPoW code is slightly consensus-incompatible with Namecoin Core. Verifying that is on my to-do list.
The next step in Electrum-NMC is adding support for name scripts. That will be covered in a future post.
This work was funded by Cyphrs.
The Great Namecoin Mining Brownout of June 17-20, 2018: Postmortem
Recently, many Namecoin mining pools experienced an outage, causing transaction confirmation to slow down to 2.1 blocks/hour. We’ve fixed the issue, and mining is back to normal. This post summarizes what we know about the outage.
The Cause
On June 17, an unknown person appears to have built a pair of name_new and name_firstupdate transactions with the raw transaction API, and broadcast them both to the Namecoin P2P network at the same time. This is not something that the normal Namecoin Core GUI or RPC API will let you do, because revealing your name_firstupdate transaction before the name_new has been confirmed allows 3rd parties to front-run your registration. However, there’s nothing that prevents users from doing this via the raw transaction API. Namecoin Core’s consensus rules require name_firstupdate transactions to wait 12 blocks after name_new before they can be mined; any name_firstupdate transactions whose name_new input doesn’t yet have 12 confirmations will be admitted to the memory pool but will not be mined. Unfortunately, there was a bug in Namecoin Core’s mining code: while it was correctly choosing not to mine name_firstupdate transactions whose name_new input had between 1 and 11 (inclusive) confirmations, it was erroneously trying to mine name_firstupdate transactions whose name_new input had zero confirmations. As a result, getblocktemplate was building an invalid block, and then returning an error upon detecting that the block was invalid, which DoSed the mining pools.
Our Initial Response
Cassini reported on June 18 that, during the prior 24 hours, only ViaBTC and BTC.COM had mined any Namecoin blocks. He wasn’t sure what the cause of the outage was, but he did note that it didn’t seem to be related to BTC versus BCH mining, since ViaBTC was still using both parent chains for Namecoin mining as usual. The obvious thing to do was to contact the mining pools to figure out whether they were seeing any errors on their end. Jeremy began contacting the mining pools. While we were waiting for mining pools to respond, we tried to analyze possible failure modes. Cassini speculated that maybe an accidental consensus fork had occurred, and wondered whether the two pools who were still online had changed anything about their setup recently (e.g. updating their Bitcoin Core or Namecoin Core client). Jeremy noted that clearly the pools who were still online hadn’t accidentally activated a hardfork, since Jeremy’s Namecoin Core node from 2 years ago was still accepting their blocks. To verify whether an accidental softfork had been activated, Jeremy asked Redblade7 (who runs a Namecoin seed node) to check the output of namecoin-cli getchaintips. The output revealed that no forks had been observed since June 3 (and that fork was only a single orphaned block), which made it clear that no softfork had occurred. (In addition, the two pools who were still up composed a minority of the usual hashrate, which again pointed to this not being an accidental softfork.)
Response from Miners
Wang Chun from F2Pool was the first mining pool operator to get back to us; he said F2Pool was investigating the issue from their side. Shortly afterward, F2Pool’s mining came back online and mined 6 blocks. Shortly afterward, crackfoo of zpool posted on GitHub saying that he was repeatedly getting getblocktemplate errors that day. crackfoo posted this in a GitHub issue that was fairly old: mining pools had occasionally been receiving that error for well over a year, but it had been difficult to reproduce. However, the last post in that thread prior to crackfoo’s was from Yihao Peng of BTC.COM on June 17, saying that he had gotten the error that day and had fixed it by clearing his memory pool. Yihao Peng’s post was the first one that provided debug logs, which allowed us to analyze what was happening. Daniel quickly figured out that the issue was caused by the unconfirmed name_new and name_firstupdate pair, and Jeremy speculated that this was probably the reason for the outage.
Immediate Fixes
crackfoo asked whether there was any way to exclude the name_firstupdate from block creation as a temporary fix while we were waiting for a Namecoin Core update. Jeremy suggested using the prioritisetransaction RPC call to prevent the name_firstupdate from being included in blocks. Jeremy then tested this locally, and verified that it fixed mining; Jeremy sent out a message to the Alerts mailing list notifying mining pools that they could restore service by doing this. Jeremy also suggested using prioritisetransaction to accelerate the name_new transaction, since once it got mined, the problem would go away (even for mining pools who didn’t do anything). Yihao Peng from BTC.COM offered to do so, and successfully mined the name_new transaction on June 20. At this point, we observed the rest of the mining pools come back online.
Proper Fixes
Daniel has fixed the relevant behavior in Namecoin Core’s block construction code; the fix is present in both the master and 0.16 branches. Miners are encouraged to upgrade so that this situation can’t happen again.
Analysis
Obviously, any kind of mining disruption is a bad thing, since it causes transactions to confirm more slowly and also increases exposure of the Namecoin network to potential 51% attacks. In particular, when only 2 mining pools are mining blocks for a period of a day, the larger of the two pools obviously has the capacity to double-spend transactions. We’re not aware of any reason to believe that any double-spend attacks occurred, which is consistent with our general experience that the Namecoin mining pools behave ethically and try to help us fix issues. (AuxPoW researchers Paul Sztorc and Alexey Zamyatin have come to similar conclusions about Namecoin mining pools.) In particular, BTC.COM (the pool that would have been capable of double-spending) was also the pool who reported debug logs to us and accelerated the name_new transaction to fix the problem for the other pools.
Generally speaking, our incident response went quite well. In particular, service stayed up and running throughout the 3-day incident, although it took ~3x longer to get transactions to confirm than usual. Compared to the previous notable outage, from 2014, where the network was totally unusable for 2 weeks, things certainly went a lot better this time around. However, we wouldn’t be doing our jobs if we didn’t propose some additional steps we can take to further improve:
- Streamline the process of contacting mining pools. We already have an alerts mailing list that was set up long ago, but the alerts list is ill-suited to cases where we suspect a problem with a particular mining pool and don’t want to spam the other pools with noise. Improving this is already on our radar, due to some upcoming softforks (yes, we’re finally activating P2SH and SegWit soon!) on which we need to closely coordinate with mining pools (and other service providers, such as exchanges, registrars, block explorers, ElectrumX operators, inproxies like OpenNIC, and analytic websites like CoinMarketCap, BitName.ru, and Blockchain-DNS.info).
- Automated monitoring. Significant progress was made on this since the 2014 outage. In particular, we have a free software script that can calculate hashrate distribution, and Cassini runs this script regularly. However, that script is not maintained as well as it should be (both Cassini and Jeremy have some private changes that haven’t yet been merged due to lack of time to devote to it), and it would be beneficial to document exactly how to run the script in an automated fashion, with things like email or Matrix alerts when suspicious events occur. We’re currently in the middle of re-evaluating our CI infrastructure (yes, we are aware of the GitHub buyout by a PRISM member and ICE supplier, and we’re not happy about it), and this is definitely one area that we’ll be exploring. Coincidentally, several of our developers recently obtained a Talos II from Raptor Computing Systems (yes, they are awesome, you should support Raptor), so this may give us additional infrastructure options.
And, to complement the above, some things that aren’t critically needed for this particular issue:
- Quick release of binaries for emergency fixes. While this would be highly useful for other reasons (and we’re exploring this possibility for CI infrastructure), we’ve been sufficiently successful at making Namecoin Core build reliably from source that the mining pools usually build Namecoin Core themselves. At the time of the 2014 outage, Namecoin was a pain in the rear to build and a lot of mining pools were using our binaries. Not a problem anymore.
- Adopt support for Matt Corallo’s decentralized pooled mining protocol. While this would have substantial benefits in terms of both total hashrate and hashrate diversity, the problem at the root of this issue is a matter of (1) effective communication with miners and (2) attentive miners, both of which are made mildly worse by a more diverse hashrate distribution. We do intend to pursue this as a long-term goal (it’s a hardfork, meaning that adopting it is a major bother), and we think it’s highly important for Namecoin to improve in this area, even though a more diverse hashrate is less effective for communication and attentiveness.
- Contingency plans for developers who are busy with external obligations. Although more redundancy is always helpful, we currently have some developers who have sufficient funding for Namecoin to be their primary project. This was not the case in 2014, when our primary responders were dealing with unrelated business trips or school coursework. As a result, response to critical issues is substantially more reliable now than it was 4 years ago. Don’t get me wrong, we still need more developers, and we still would benefit from more funding – but things are clearly moving in the right direction.
Thanks
The following people helped respond to the outage:
- Cassini
- Jeremy Rand
- Daniel Kraft
- Yihao Peng (BTC.COM)
- crackfoo (zpool)
- Wang Chun (F2Pool)
- Redblade7
- Luke Dashjr
Electrum-NMC: AuxPoW Deserialization
Namecoin’s merged mining, which allows miners to simultaneously mine a parent chain (usually Bitcoin) and any number of child chains (e.g. Namecoin and Huntercoin), is made possible by AuxPoW (auxilliary proof of work). AuxPoW is a clever trick (first proposed by Bitcoin founder Satoshi Nakamoto, and first implemented by Namecoin founder Vincent Durham) that allows a block in the parent chain to commit to a block in any number of child chains, such that the child block can reference the parent block’s PoW and thereby prove that the PoW committed to both the parent and child block. AuxPoW doesn’t impose any changes for the parent chain’s consensus rules, but it does constitute a hardfork for the child chain (even for lightweight SPV clients of the child chain). As a result, making Electrum-NMC validate PoW properly requires patching Electrum to support AuxPoW.
Recently I started hacking on Electrum-NMC to support AuxPoW. This is not an entirely new problem; a previous Electrum fork (Electrum-DOGE) already tried to implement AuxPoW. Unfortunately, Electrum-DOGE’s code quality is not exactly up to my standards, and besides that, it’s a fork of a 3.5-year-old version of Electrum. Electrum has evolved substantially since then, to the point that a straightforward merge isn’t possible. Additionally, it’s not clear how many people have actually audited Electrum-DOGE for correctness. That said, Electrum-DOGE’s implementation is definitely a useful reference for determining how to do AuxPoW in Electrum.
Upon adding some debug output to Electrum-NMC, I observed that the first error that showed up was in deserializing block headers. This makes sense, since in Bitcoin, all block headers are exactly 80 bytes, whereas in Namecoin, the 80 bytes are optionally followed by a variable-length AuxPoW header, which includes things such as the parent block’s header, the parent block’s coinbase transaction (variable length), and two Merkle branches (also variable length). Electrum-DOGE’s code for deserializing block headers wasn’t directly mergeable, but it definitely was sufficient reference material to implement AuxPoW header deserialization in Electrum-NMC.
The next error that showed up was related to deserializing chunks of block headers. Electrum groups block headers into chunks, where each chunk corresponds to a difficulty period (2016 block headers). Electrum was, of course, assuming in the chunking code that a chunk was exactly 2016 * 80 bytes, which wasn’t going to work with AuxPoW. Fixing this was straightforward enough that I did so without using Electrum-DOGE as a reference (the chunking code has evolved enough in the last 3.5 years that using Electrum-DOGE as a reference would probably have taken more time than reimplementing from scratch).
The next step is dealing with serialization/deserialization of block headers to/from disk. Naturally, Electrum’s block header storage format assumes 80-byte headers, so fixing that will take some work.
There’s also a licensing side effect of using Electrum-DOGE as a reference. Electrum’s license used to be GPLv3+, but since then they’ve relicensed to MIT. Electrum-DOGE was forked from Electrum before the license change, and Electrum-DOGE’s authors never relicensed. As a result, the code I wrote that’s based on Electrum-DOGE’s codebase is a derivative work of GPLv3+-licensed code. All of the code from upstream Electrum, as well as all of Namecoin’s changes to Electrum and Electrum-DOGE, are still MIT-licensed, but the full combined work that constitutes Electrum-NMC is GPLv3-licensed. This isn’t really a huge problem (GPLv3+ is a perfectly fine free software license, and I wasn’t intending to submit any of the AuxPoW code upstream anyway), but it’s definitely noteworthy.
More Electrum AuxPoW work will be covered in future posts.
This work was funded by Cyphrs.
Electrum-NMC v3.1.3-beta1 Released
We’ve released Electrum-NMC v3.1.3-beta1. This release supports Namecoin currency transactions, but does not yet support AuxPoW or name transactions. This release is based on work by both ahmedbodi and myself.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Electrum-NMC: Code Review and Rebase
Last year, Ahmed posted about his progress porting Electrum to Namecoin. Electrum-NMC has been on the back burner for me lately, due to the TLS and BitcoinJ efforts taking up most of my time. However, today I found time to inspect Ahmed’s branch.
Three main things were on my agenda:
- Code review of the existing changes. Generally I don’t like to move code to the GitHub Namecoin organization unless I’ve actually reviewed it for sanity. I made a few tweaks and bugfixes to Ahmed’s code, but for the most part the code review went smoothly.
- Rebase against current master branch of Electrum. This actually went surprisingly well, given that Ahmed’s branch is about 11 months old. The vast majority of the merge conflicts were due to the
electrumpackage being renamed toelectrum-nmc, which causes unfortunate merge conflicts every time upstream messes with theimportstatements at the top of a Python file. Unfortunately I don’t know of any way around this, and a cursory check of altcoin Electrum ports shows that they do the same thing, so I guess we’re going to live with it. The good news is that those types of merge conflicts are very easy to manually resolve. - Additional rebranding beyond what Ahmed’s branch does. In particular, I swapped out the ElectrumX Bitcoin server addresses and replaced them with ElectrumX Namecoin server addresses. (Right now there’s only 1 public ElectrumX Namecoin server. We need more of them — if you’d like to help us, please consider starting up an ElectrumX Namecoin server and sending a PR to ElectrumX that adds your server to the public list.) I also swapped out the Bitcoin block explorers and replaced them with Namecoin explorers. (I also gave the Namecoin explorers names that include scary warnings for the subset of explorers that are wiretapped by CloudFlare, discriminate against Tor users, don’t support names, or are non-libre.)
The resulting code is now on GitHub. I’ve successfully sent some coins from Namecoin Core to Electrum-NMC and back without any difficulty.
Regarding next steps, I’ll defer to Ahmed’s post:
On the roadmap now are:
- Extend electrumX NMC Support to allow for full veritification of AuxPow
- Modify new electrum client to verify the new AuxPow
- Add Name handling support to electrum
Hopefully these won’t be incredibly difficult. I might post binaries of the current codebase before I try to tackle these (but note that I’m not familiar with the Electrum packaging scripts yet, so there’s a good chance that I’ll break something and/or find something that I broke earlier).
This work was funded by NLnet Foundation’s Internet Hardening Fund.
More Fun with tlsrestrict_nss_tool on Windows
Last episode: When we last left our hero, tlsrestrict_nss_tool had a few unfixed bugs that made it unusable on Windows. Everyone believed those bugs would be the final ones. Were they? And now, the conclusion to our 2-part special:
Spoiler alert: no, of course they weren’t the final bugs! Obviously Murphy needs to keep showing up, otherwise life as an engineer would be boring, right?
Anyway, so I fixed the 3 known bugs:
- Use of
cp - No warning when CKBI is empty.
- Broken Unicode in nicknames.
And at this point, things almost worked. Specifically, I could apply a name constraint that blacklisted .org, and accordingly the Namecoin website showed an error, while Technoethical still worked. Seems good enough, right? I certainly thought so, at least enough to announce on #namecoin-dev that I believed it was working. Except then I had that insane urge to try to torture-test it a bit more. So I ran tlsrestrict_nss_tool a 2nd time against the same NSS DB and the same CKBI library. The expected behavior is that it will examine the CKBI and NSS DB, and decide that no additional cross-signing is needed. Unfortunately, I instead was treated to a fatal error due to an ASN.1 parse error, specifically due to trailing data.
I’ve seen this error before, and it’s usually triggered by an NSS quirk. NSS doesn’t actually keep track of each certificate uniquely. If you put 2 certificates in an NSS DB that have the same Subject, and you ask certutil to give you one of them (doesn’t matter which), certutil will actually give you both of them, concatenated. This happens regularly in our usage, because the cross-signed CA and the (distrusted) original CA have the same Subject (by design).
Further examination of the logs showed that the errors were showing up while trying to handle certs that had a very odd characteristic: their names looked like what you would get from concatenating the Namecoin prefix with an empty string instead of with the name of the certificate. Given that I had just spent time fixing issues with Unicode encoding of certificate names, this seemed to be a likely culprit.
So, I made 2 (overdue anyway) changes to the codebase:
- Switch from DER to PEM encoding when communicating with certutil. DER doesn’t have boundaries when you concatenate certificates, while PEM does. Using PEM should make debugging a lot easier when multiple certs show up with the same name.
- When dumping a PEM cert from the NSS DB, explicitly check for multiple PEM certs, and if more than one is present, try to guess which one is correct by checking for the Namecoin prefix in its Subject CommonName and Issuer CommonName (this will be unambiguous under typical conditions). If more than one cert is present that matches the expected prefixes, throw an error and log all of the PEM certs that showed up in the dump.
So, with those changes added, I ran it again, and quickly got an error telling me that 9 certs were being returned in a single dump. How odd. Conveniently, the log told me what certificate it was trying to dump when this happened: “Namecoin Restricted CKBI Intermediate CA for ePKI Root Certification Authority”. This didn’t look like a Unicode issue at all – that name is entirely Latin. So I Googled for “ePKI Root Certification Authority”, and quickly facepalmed. That root CA doesn’t have a CommonName! Suddenly the symptoms made sense. The root and intermediate CA’s that are created by cross_sign_name_constraint_tool prepend a Namecoin string to the CommonName of the input CA and discard the rest of the input CA’s Subject, meaning that if multiple input CA’s have a blank CommonName, their resulting Namecoin root and intermediate CA’s will end up with colliding Subjects. Fail.
The fix, of course, is to append the SHA256 fingerprint of the input CA to the Subject CommonName of the root and intermediate Namecoin CA’s. This ensures that we’ll get a unique Subject per input certificate.
And now, it works. Repeated runs of tlsrestrict_nss_tool work as they should. Kind of irritating to spend so much time chasing a silly fail like that, but on the bright side the switch to PEM resulted in cleaner code.
Next, I’ll be integrating tlsrestrict_nss_tool into ncdns. Hopefully this will expose any remaining weirdness.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Testing tlsrestrict_nss_tool on Windows
Now that we got NSS certutil reproducibly cross-compiled for Windows, initial testing has begun on tlsrestrict_nss_tool for Windows.
Besides the obvious and rather boring fail that tlsrestrict_nss_tool was trying to execute cp, which of course isn’t going to work on Windows (that particular code segment is a relic from quick prototyping that wasn’t ever intended to stay in the codebase), two more interesting issues were identified:
- rbm builds
certutilwith the Visual C++ 2010 runtime, so runningcertutilwithout that runtime installed produces an obvious error. However, in order to properly detect the built-in certificates (“CKBI”) that Firefox ships with,tlsrestrict_nss_toolmakescertutilload the CKBI module that Firefox distributes (not the CKBI module thatcertutilwas built with). This means that, whencertutilis asked to load Firefox’s CKBI module, the Visual C++ runtime used by Firefox’s CKBI module also needs to be present. Which happens to be Visual C++ 2015. Without that,certutillooks like it’s working – but the moment the Firefox CKBI module is loaded intocertutil,certutilexits with a missing DLL error. However, the situation is worsened by the fact that, as far as I can tell, a missing DLL error in Windows doesn’t impact the exit code. Sotlsrestrict_nss_tooldoesn’t actually know thetcertutilencountered an error; it just thinks it succeeded, and happened to produce no output. What happens ifcertutilproduces no output when dumping the CKBI list? Well,tlsrestrict_nss_tooljust figures that you’re using a Firefox build that doesn’t have any default trusted CA’s! This is bad enough when you first runtlsrestrict_nss_tool, since it will basically be a no-op. But even worse, if you did have the Visual C++ dependency from Firefox, but then Firefox upgraded it, then the next time you try to runtlsrestrict_nss_tool, all of the name constraints that were previously added will get deleted, becausetlsrestrict_nss_toolfigures that those CA’s have vanished. How sad. The fix here is probably to maketlsrestrict_nss_toolexplicitly error if the CKBI module appears to have 0 certificates in it. Such a scenario pretty much always indicates that something has gone horribly wrong involving the CKBI module, and it’s generally best to treat it as an error. certutil’s certificate dumping functions require selecting a certificate by its nickname. What’s a nickname? In practice, for the CKBI module it seems to be the CommonName of the certificate. The nickname is passed tocertutilvia a command line flag. What could possibly go wrong here? Certificate nicknames can be arbitrary text, including Unicode. What happens when you pass Unicode as a command line argument in Windows? Nothing good happens, that’s for sure. In my testing, Windows will corrupt all of the non-ASCII characters, which results incertutilreceiving a corrupted nickname to look up (and it correctly replies that no such nickname exists in the database). The fix here is to usecertutil’s “batch command” feature.certutilallows you to put a sequence of commands into a.txtfile, and you can pass that.txtfile’s path tocertutilwith a command line flag;certutilwill then run all of those commands. Since the.txtfile isn’t parsed by Windows’s broken command line text decoder, Unicode inside the.txtfile passes through unharmed.
Now, I haven’t actually fixed these bugs yet. But, progress is progress. Hopefully fixes will be coming very soon.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Reproducible Builds of NSS certutil via Cross-Compiling with rbm
In a previous post where I introduced tlsrestrict_nss_tool, I mentioned that NSS’s certutil doesn’t have official binaries for Windows, and that “At some point, we’ll probably need to start cross-compiling NSS ourselves, although I admit I’m not sure I’m going to enjoy that.” Well, we’ve reached that point, and it was an interesting adventure.
Initially, I looked at the NSS build docs themselves, and was rather annoyed to find that there’s no documentation about how to cross-compile NSS. To make matters worse, the only results I could find by Startpaging were people saying that they couldn’t figure out how to cross-compile NSS (including some well-known software projects’ developers).
However, it just so happens that there’s a very high-profile free software project whom I was certain is definitely cross-compiling NSS: The Tor Project. Tor cross-compiles Firefox (including NSS) as part of their Tor Browser build scripts, so it seemed near-certain that their build scripts could be modified to build certutil. However, Tor’s build scripts are rather nonstandard, since they build everything with rbm. rbm is a container-based build system that’s superficially similar to the Gitian build system that Bitcoin Core and Namecoin Core use (indeed, The Tor Project used to use Gitian before they migrated to rbm). I’ve been intending to get my feet wet with rbm for quite a while now, so this seemed like a great excuse to play with rbm a bit.
First off, I wanted to build Firefox in rbm without any changes. This was actually quite easy – The Tor Project’s documentation is quite good, and I didn’t run into any snags (besides the issue that I initially assigned too little storage to the VM where I was doing this – The Tor Project should probably document the expected storage requirements). The build command I used was:
./rbm/rbm build firefox --target nightly --target torbrowser-windows-i686
Next, I looked at Tor’s Firefox build script… and I was delighted to see that Tor is already building certutil. In fact, you can download certutil binaries from The Tor Project’s download server right now! (You want the mar-tools-*.zip packages.) Except… their build script discards the certutil binaries for all non-GNU/Linux targets. How sad.
Modifying the build script to also output certutil.exe for Windows was reasonably straightforward – rbm even worked without erroring on the first try. I did, however, need to try for a few iterations to make sure that I was outputting all of the needed .dll files. However, once I had all the required .dll files, a rather odd symptom occurred when I tested it on a Windows machine. When I ran certutil.exe from a command prompt, it would immediately exit without printing anything. Stranger, when I double-clicked certutil.exe in Windows Explorer, it didn’t even pop up with a command prompt window before it exited. In addition, I noticed that if I passed command line arguments to certutil.exe telling it to create a new database, it actually did create the database – but it still didn’t display any output.
This seemed to indicate that something was wrong not with certutil.exe’s actual functionality, but with its PE metadata: Windows was probably treating it as a GUI application rather than a console application. Checking the PE metadata confirmed this: Tor’s build scripts were producing a certutil.exe whose PE metadata was marking it as a GUI application. Some more quick searching revealed a StackOverflow post providing a short Python2 script that could edit that part of the PE metadata. I ran that script against certutil.exe… and now certutil.exe works properly. Yay!
The lack of certutil.exe binaries was one of the major blockers for releasing negative TLS certificate overrides for Firefox on Windows. Now that this barrier is behind us, I can get around to testing tlsrestrict_nss_tool on Windows, and hopefully do a release (with NSIS installer support). And as a side bonus, certutil.exe builds reproducibly, and I’ve now gotten some experience with rbm (meaning that reproducible builds for ncdns and our other Go software may be coming soon).
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Integrating ncdumpzone’s Firefox TLS Mode into ncdns
I discussed in a previous post some experimental work on making ncdumpzone output a Firefox certificate override list. At that time, the procedure wasn’t exactly user-friendly: you’d need to run ncdumpzone from a terminal, redirect the output to a file, close Firefox, delete whatever existing .bit entries existed in the existing Firefox certificate override file, append the ncdumpzone output to that file, and relaunch Firefox. I’ve now integrated some code into ncdns that can automate this procedure.
One of the trickier components of this was detecting whether Firefox was open. Firefox’s documentation claims that it uses a lockfile, but as far as I can tell Firefox doesn’t actually delete its lockfile when it exits (and I’ve seen similar reports from other people). Eventually, I decided to just watch the contents of my Firefox profile directory (sorted by Last Modified date) as Firefox opened and closed, and I noticed that Firefox’s sqlite databases produce some temporary files (specifically, files with the .sqlite-wal and .sqlite-shm extension) that are only present when Firefox is open. So that’s a decent hack to detect that Firefox is open.
Given that, ncdns now creates 2 extra threads: watchZone and watchProfile. watchZone dumps the .bit zone with ncdumpzone every 10 minutes, and makes that data available to watchProfile. (Right now, ncdumpzone is called as a separate process, which isn’t exactly ideal – a future revision will probably refactor ncdumpzone into a library so that we can avoid this inefficiency.) watchProfile waits for Firefox to exit (it checks at 1 Hz), and then loads Firefox’s cert_override.txt into memory, removes any existing .bit lines, appends the data from watchZone, and writes the result back to Firefox’s cert_override.txt.
These 2 new threads in ncdns are deliberately designed to kill ncdns if they encounter any unexpected errors. This is because, if we stop syncing the .bit zone to the Firefox override list, Firefox will continue trusting .bit certs that might be revoked in Namecoin. Therefore, it is important that, in such a situation, .bit domains must stop resolving until the issue is corrected. Forcing ncdns to exit seems to be the least complex way to reliably achieve this.
These changes significantly improve the UX of positive TLS certificate overrides for Firefox. A pull request to ncdns should be coming soon.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Fixing DNAME records in madns and dns-prop279
One of the more obscure DNS record types is DNAME (AKA the Namecoin "translate" JSON field), which is basically a DNS redirect for an entire subtree. For example, currently radio.bit. has a DNAME record pointing to biteater.dtdns.net., which means that any subdomain (e.g. batman.radio.bit.) becomes a CNAME redirect (e.g. to batman.biteater.dtdns.net.).
DNAME is not exactly a favorite of mine in the context of Namecoin, because it’s easy to misuse it in a way that assigns trust for a Namecoin domain name to 3rd party keys whom Namecoin is intended to not trust (e.g. if you DNAME radio.bit. to a DNS domain name, you’re also assigning control of the TLSA records for _443._tcp.radio.bit. to whatever DNSSEC keys have the ability to sign for that DNS domain name, which probably includes a DNS registrar, a DNS registry, and the ICANN root key). That said, DNAME is part of the DNS, and so it should work in Namecoin, even though there aren’t likely to be many good uses for it in Namecoin.
Which is why I was surprised to notice when I tested DNAME today that it wasn’t actually working as intended in ncdns or dns-prop279. Some digging revealed that madns (the authoritative DNS server library that ncdns utilizes) didn’t actually have any DNAME support; the place in the code where it should have gone was just marked “TODO”. This was a great excuse for me to get my feet wet with the madns codebase (Hugo usually handles that code), so I jumped in.
In the process of adding DNAME support to madns, I got to read RFC 6672, and noticed that it very much looks like Namecoin’s d/ (domain names JSON) spec is not quite compliant with the RFC. Specifically, the Namecoin spec says that a DNAME at radio.bit. suppresses all other records at radio.bit., whereas the RFC says that other record types can coexist at radio.bit., with the sole exception of CNAME records. I’ve filed a bug to get the Namecoin spec brought in line with the RFC.
Once I got madns supporting DNAME properly, that meant I could test dns-prop279 with DNAME. Except testing quickly showed that dns-prop279 was crashing when it encountered a DNAME. A quick check of the stack trace showed that I had made a minor screw-up in the error checking in dns-prop279 (specifically, dns-prop279 is asking for a CNAME, but doesn’t properly handle the case where it receives both a DNAME and a CNAME). A quick bugfix later, and dns-prop279 was correctly handling DNAME.
The fixes are expected to be included in the next release of ncdns and dns-prop279.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
(Side note: some readers might have noticed that I was posting less frequently over the past month or so. That’s because my master’s thesis defense was on May 3, and as a result I spent most of the last month getting ready for that. I passed my defense, so things should be back to normal soon.)
cross_sign_name_constraint_tool v0.0.2 and tlsrestrict_nss_tool v0.0.2 Released
We’ve released cross_sign_name_constraint_tool v0.0.2 and tlsrestrict_nss_tool v0.0.2. These implement the functionality described in my previous post on Integrating Cross-Signing with Name Constraints into NSS (and the earlier posts that that post links to).
With this release, in theory Namecoin TLS negative overrides are supported in anything that uses NSS’s trust store (including Firefox on all OS’s, and Chromium on GNU/Linux, without requiring HPKP).
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ncdns v0.0.6 Released
We’ve released ncdns v0.0.6. List of changes:
- Windows installer:
- Bump ConsensusJ-Namecoin dependency to v0.2.7.
- Bump Dnssec-Trigger dependency to v0.15. (Patch by Jeremy Rand.)
- Bump dnssec-keygen dependency to v9.12.1. (Patch by Jeremy Rand.)
- Code quality improvements. (Patch by Hugo Landau; reported by Jeremy Rand.)
- NetBSD:
- Disable NetBSD/ARM builds due to an upstream bug. NetBSD/ARM builds will return later. (Patch by Jeremy Rand.)
- All OS’s:
- certinject: Add support for NSS trust stores; this enables positive TLS overrides in Chromium on GNU/Linux (and probably various other software that uses NSS for certificate validation. (Patch by Jeremy Rand.)
- ncdumpzone: Add
cert_override.txtoutput format; this enables positive TLS overrides in Firefox (and probably various other software based on Firefox). (Patch by Jeremy Rand.) - Fix TLSA records served over DNS (for the lucky users using software that supports DANE). (Patch by Jeremy Rand; reported by Jefferson Carpenter.)
- Bundle miekg’s
q. (Patch by Jeremy Rand.) - Bundle
dns-prop279. (Patch by Jeremy Rand.) - Change default Namecoin RPC host from
localhostto127.0.0.1; should fix some RPC errors on Windows. (Patch by Jeremy Rand.) - Code quality improvements. (Patch by Jeremy Rand.)
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ConsensusJ-Namecoin v0.2.7 Binaries Available
Binaries of ConsensusJ-Namecoin (the Namecoin lightweight SPV lookup client) v0.2.7 are now released on the Beta Downloads page page. This is based on the source code that was released earlier. Notable new things in this release:
leveldbtxcachemode is merged to upstream libdohj, and has therefore had the benefit of more peer review.leveldbtxcachemode now only stores the name scriptPubKey, not the entire transaction. This significantly improves syncup time and storage usage. (Currently, it uses around 65 MB of storage, which includes both the name database and the block headers.)- Many dependency version bumps.
As usual, ConsensusJ-Namecoin is experimental. Namecoin Core is still substantially more secure against most threat models.
Integrating Cross-Signing with Name Constraints into NSS
At the end of my previous post about porting cross-signing with name constraints to Go, I mentioned that the next phase was to automate the procedure of applying the constraints to all root CA’s in NSS, instead of needing to manually dump CA’s one-by-one from NSS, run them through my Go tool (currently named cross_sign_name_constraint_tool, because I’ve exhausted my witty software naming quota on another project[1]), and import them back into NSS. I’m happy to report that this next phase is essentially complete, and in my testing I blacklisted certificates for the .org TLD regardless of which built-in root CA they chained to (without any impact on other TLD’s).
My previous post went into quite a bit of technical detail (more so than a typical post of mine), mainly because the details of getting Go to cross-sign with name constraints with minimal attack surface were actually rather illuminating. In contrast, most of the technical details I could provide for this phase are rather boring (in my opinion, at least), so this post will be more high-level and somewhat shorter than the previous post. (And no code snippets this time!)
Early on, I had to make a design decision about how to interact with NSS. There were 3 main options available:
- Pipe data through
certutil. - Link with the NSS shared libraries via cgo.
- Do something weird with sqlite. (This category actually includes a wide variety of strange things, including using sqlite’s command line utility, using sqlite with cgo, and using horrifying
LD_PRELOADhooks to intercept NSS’s interaction with sqlite.)
Given that I haven’t used sqlite in several years, and that I’ve never actually used cgo, but I use certutil on a daily (if not hourly) basis these days, it was pretty clear that option 1 was going to be the most effective usage of my development time. And it actually came together surprisingly fast, into a command-line tool that I call tlsrestrict_nss_tool (note the naming similarity to tlsrestrict_chromium_tool – the functionality is analogous). A few of the more “interesting” things I ended up dealing with:
- Using
certutilto retrieve a list of all certificate nicknames in a database looks like it returns an error. I say “looks like” because there’s actually no error. The standard output contains all the data I asked for, and the standard error is empty. But for some reasoncertutilreturns exit code 1 (indicating an error), not exit code 0 (indicating success), for this particular operation. The exit codes for other operations incertutildon’t exhibit this issue. I ended up just having my code treat exit code 1 as exit code 0 for this particular operation, which seems to work okay. - When an NSS database contains 2 different certificates that contain the same Subject and Public Key, NSS actually can’t keep track of which is which. The metadata stays consistent, but when you ask for the DER-encoded certificate data for 1 of the certificates, NSS decides to give you both of them. Concatenated together. This led to me writing some generally horrifying code that tries to check for the presence of a certificate by doing both a prefix and suffix match against a byte slice (since I don’t have any idea what order the certificates will be concatenated in). It’s probably somewhat safer to change
tlsrestrict_nss_toolto use PEM encoding rather than DER, since it’s easier to detect boundaries of concatenated PEM blocks. I’ll probably do this next time I’m cleaning up the code. - I accidentally applied a name constraint excluding
.bitinstead of.orgthe first time it ran successfully, and while trying to undo my mistake, I realized I hadn’t ever considered how to uninstall all of these extra certificates. Back when I was just dealing with a single CA, it was easy to uninstall them viacertutilby hand, but at this scale it’s not feasible to do that. So I ended up adding an extra uninstall mode. It turned out to be relatively straightforward – apparently my design was flexible enough that this functionality wasn’t hard to add, even though I had never explicitly thought about how I would do it. Whew! - The big one. Applying the name constraint to the entire NSS built-in certificate list (starting with a mostly-stock database) took 6 minutes and 48 seconds. I strongly suspect that most of this overhead is because NSS doesn’t support sqlite batching, so for every certificate that gets cross-signed, something like 7 sqlite transactions are issued. On the bright side, my code is smart enough to not attempt to cross-sign certificates for which an existing cross-signature is already present, so the 2nd time you run it, it only takes 20 seconds (which is mostly spent dumping the existing certificates in order to verify that no changes are needed). Of course, if the trust bits get changed in the built-in list (or if the DER encoded value of a built-in certificate changes), the old cross-signature will be removed, and a new cross-signature will be added. (Technically there are probably some interesting race conditions here, and properly fixing that is on my to-do list.)
Anyway, once the 6 minutes and 48 seconds to run tlsrestrict_nss_tool had elapsed, I launched Firefox (this was being done with a Firefox NSS sqlite database on Fedora), and was pleased to see as soon as Firefox booted, I immediately got a certificate error – Firefox’s home page was set to https://start.fedoraproject.org/, and .org was the excluded domain in the name constraint that I configured for the test. I tested various .org and .com websites with a variety of root CA’s, and the result was consistent: all .org sites showed a certificate error, while .com websites worked fine. For example, when I looked at the certificate chain for StartPage, Firefox reported that the trust anchor was named Namecoin Restricted CKBI Root CA for COMODO RSA Certification Authority, indicating that the name constraints had indeed taken effect.
I think the code is now at the point where I’ll soon be pushing it to GitHub, and maybe doing some binary releases for people who want to brick their NSS database and lose their client certificate private keys try it out in a VM and report how it works. All that said, a few interesting caveats remain:
tlsrestrict_nss_toolonly applies name constraints to certificates from Mozilla’s CKBI (built-in certificates) module. If you’re in the business of manually importing extra root CA’s, I’m currently assuming that one of the following is true:- You’re deliberately intercepting your traffic for debug purposes, and therefore don’t want the name constraint to apply.
- You’re capable of using
cross_sign_name_constraint_toolto manually add the name constraint before you import a root CA. - You’ve read this warning and ignored it, and therefore when you get pwned by Iranian intelligence agencies, I’m not responsible.
tlsrestrict_nss_toolhas the side effect of making trust anchors from the CKBI module no longer appear to be from the CKBI module. Why does this matter? Many key pinning implementations only enforce key pins against CKBI trust anchors. (This is actually the trick we wereabusinginnovatively utilizing withtlsrestrict_chromium_tool, but now it’s working against us rather than in our favor.) Mitigating factors:- Chromium-based browsers are scrapping HPKP soon, so if your security model is dependent on HPKP working in Chromium, you might want to re-evaluate soon.
- Chromium’s HPKP was already completely broken on Fedora due to a Chromium bug. It turns out that p11-kit, which Fedora uses as a drop-in replacement for CKBI, utilizes an NSS feature to indicate that it should be treated as CKBI, but Chromium didn’t use that NSS feature properly, and the Chromium devs had minimal interest in fixing it. Chromium’s devs explained this decision by saying that HPKP is a best-effort feature, and that HPKP failure is not considered a security issue in Chromium. (The bug was eventually fixed on December 28, 2017, approximately 9 months after it was reported to Chromium.) So again, if your security model is dependent on HPKP working in Chromium, you might want to re-evaluate, because the Chromium devs don’t agree with you.
- Firefox’s HPKP can be optionally configured via
about:configto enforce even for non-CKBI trust anchors. If you’re not deliberately intercepting your own traffic, you probably should enable this mode. - It’s arguably an NSS certutil bug that the CKBI-emulating flag that p11-kit uses can’t be read/set by certutil. Mozilla should probably fix that sometime.
- Once I port
tlsrestrict_nss_tooltotlsrestrict_p11_toolor something like that (i.e. port from NSS to p11-kit), it should be straightforward to mimic CKBI on Fedora, in the same way that p11-kit’s default CA’s mimic CKBI. This should at least be recognized by Firefox (but not by Chromium, see above).
- Using
tlsrestrict_nss_toolrequires that you have acertutilbinary. This is easily obtainable in most GNU/Linux distributions (in Fedora, it’s thenss-toolspackage), but I have no idea how easy it is to get acertutilbinary on Windows and macOS. (No, thecertutilprogram that Windows includes as part of CryptoAPI is not the same thing.) Mozilla doesn’t distributecertutilbinaries. At some point, we’ll probably need to start cross-compiling NSS ourselves, although I admit I’m not sure I’m going to enjoy that. tlsrestrict_nss_toolonly works for NSS applications that actually use a certificate database. Notably, Tor Browser doesn’t use a certificate database, because such a feature forms a fingerprinting risk. (To my knowledge, Tor Browser exclusively uses the NSS CKBI module.) Long term, we could probablyadd a bunch of attack surfacework around this issue by replacing Tor Browser’s CKBI module with p11-kit’s drop-in replacement. p11-kit is read-only, so in theory it can’t be used as a cookie like NSS’s certificate database can. But if you customize your CKBI module’s behavior in any significant way, you’re definitely altering your browser fingerprint. Assuming that all Namecoin users of Tor Browser do this the same way, it’s not really a problem, since the ability to access.bitdomains will already alter your browser fingerprint, and replacing CKBI with p11-kit shouldn’t cause any extra anonymity set partitioning beyond that. But it’s definitely not something that should be done lightly.- Right now,
tlsrestrict_nss_toolonly supports sqlite databases in NSS. The older BerkeleyDB databases might be possible to support in the future, but since everything is moving toward sqlite anyway, adding BerkeleyDB support is not exactly high on my priority list.
Despite these minor caveats, this is an excellent step forward for Namecoin TLS on a variety of applications and OS’s.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
[1] I might have written a program late last year for my master’s thesis, given it a name that is simultaneously (1) an obscure Harry Potter joke, (2) an anonymity technology joke, and (3) a Latin and Greek joke, and then devoted about 2-3 pages of my master’s thesis to explaining and elaborating on the compound joke. I probably didn’t do that though; that might constitute trolling my university, and I certainly wouldn’t do that, would I?
Cross-Signing with Name Constraints Ported to Go
In my previous post about achieving negative certificate overrides using cross-signing and name constraints, I discussed how the technique could make Namecoin-authenticated TLS possible in any TLS application that uses p11-kit or NSS for its certificate storage. However, the proof-of-concept implementation I discussed in that post was definitely not a secure implementation (nor was the code sane to look at), due to the usage of OpenSSL’s command line utility (glued to itself with Bash) for performing the cross-signing. I’m happy to report that I’ve ported the OpenSSL+Bash-based code to Go.
Creating a self-signed root CA in Go is relatively easy (there’s example code for it in the Go standard library, which happens to be the code on which Namecoin’s generate_nmc_cert tool is heavily based). Signing an existing certificate with that root CA is also pretty straightforward. The standard library’s x509 package in Go 1.9 and higher supports creating a CA with the name constraint features we want (earlier versions of Go’s x509 package only supported a whitelist of domain names; we want a blacklist, which is newly added in 1.9). Right now, ncdns is built with Go 1.8.3 due to a planned effort to use The Tor Project’s reproducible build scripts (which currently use Go 1.8.3), but this code will be used in a standalone tool that doesn’t need to be compiled into ncdns, so using Go 1.9 or higher isn’t a problem. (That said, ncdns does have pending PR’s for upgrading to Go 1.9 and Go 1.10, which will be merged when The Tor Project updates their build scripts accordingly.)
The tricky part here is that Go’s standard library’s x509 package does a lot of parsing and converting of the data in certificates, and a large amount of parsing/conversion of the CA certificate that we’re cross-signing introduces an increased risk of something in the certificate being altered in a way that affects certificate validation. This could result in unwanted errors showing up for websites (including non-Namecoin websites), which would be bad enough, but it could also result in certificates being incorrectly accepted – which would mean, among other horrible things, that MITM attacks could be performed, including against non-Namecoin websites.
As one example of bad things that can happen if too much parsing is done, OpenSSL’s command-line tool doesn’t include x509v3 extensions by default when cross-signing. x509v3 extensions are responsible for lots of things, including Basic Constraints (removing this would allow a CA to issue certs via intermediates that might not be valid), Name Constraints (we certainly don’t want to remove all the existing name constraints when we add a .bit-excluding name constraint), and Key Usage and Extended Key Usage (which would make the CA valid for purposes that browsers aren’t supposed to trust it for, e.g. making the CA valid for signing executable code instead of just signing TLS certificates). While I suspect that Go is at least mildly more sane than OpenSSL’s default settings, what I really wanted was a way to simply pass-through as much of the original root CA’s certificate as possible when cross-signing it.
Here’s the Go struct that’s returned when an x509 certificate’s raw DER form is passed to the ParseCertificate function in the standard library’s x509 package:
// A Certificate represents an X.509 certificate.
type Certificate struct {
Raw []byte // Complete ASN.1 DER content (certificate, signature algorithm and signature).
RawTBSCertificate []byte // Certificate part of raw ASN.1 DER content.
RawSubjectPublicKeyInfo []byte // DER encoded SubjectPublicKeyInfo.
RawSubject []byte // DER encoded Subject
RawIssuer []byte // DER encoded Issuer
Signature []byte
SignatureAlgorithm SignatureAlgorithm
PublicKeyAlgorithm PublicKeyAlgorithm
PublicKey interface{}
Version int
SerialNumber *big.Int
Issuer pkix.Name
Subject pkix.Name
NotBefore, NotAfter time.Time // Validity bounds.
KeyUsage KeyUsage
// Extensions contains raw X.509 extensions. When parsing certificates,
// this can be used to extract non-critical extensions that are not
// parsed by this package. When marshaling certificates, the Extensions
// field is ignored, see ExtraExtensions.
Extensions []pkix.Extension
// ExtraExtensions contains extensions to be copied, raw, into any
// marshaled certificates. Values override any extensions that would
// otherwise be produced based on the other fields. The ExtraExtensions
// field is not populated when parsing certificates, see Extensions.
ExtraExtensions []pkix.Extension
// UnhandledCriticalExtensions contains a list of extension IDs that
// were not (fully) processed when parsing. Verify will fail if this
// slice is non-empty, unless verification is delegated to an OS
// library which understands all the critical extensions.
//
// Users can access these extensions using Extensions and can remove
// elements from this slice if they believe that they have been
// handled.
UnhandledCriticalExtensions []asn1.ObjectIdentifier
ExtKeyUsage []ExtKeyUsage // Sequence of extended key usages.
UnknownExtKeyUsage []asn1.ObjectIdentifier // Encountered extended key usages unknown to this package.
// BasicConstraintsValid indicates whether IsCA, MaxPathLen,
// and MaxPathLenZero are valid.
BasicConstraintsValid bool
IsCA bool
// MaxPathLen and MaxPathLenZero indicate the presence and
// value of the BasicConstraints' "pathLenConstraint".
//
// When parsing a certificate, a positive non-zero MaxPathLen
// means that the field was specified, -1 means it was unset,
// and MaxPathLenZero being true mean that the field was
// explicitly set to zero. The case of MaxPathLen==0 with MaxPathLenZero==false
// should be treated equivalent to -1 (unset).
//
// When generating a certificate, an unset pathLenConstraint
// can be requested with either MaxPathLen == -1 or using the
// zero value for both MaxPathLen and MaxPathLenZero.
MaxPathLen int
// MaxPathLenZero indicates that BasicConstraintsValid==true
// and MaxPathLen==0 should be interpreted as an actual
// maximum path length of zero. Otherwise, that combination is
// interpreted as MaxPathLen not being set.
MaxPathLenZero bool
SubjectKeyId []byte
AuthorityKeyId []byte
// RFC 5280, 4.2.2.1 (Authority Information Access)
OCSPServer []string
IssuingCertificateURL []string
// Subject Alternate Name values
DNSNames []string
EmailAddresses []string
IPAddresses []net.IP
URIs []*url.URL
// Name constraints
PermittedDNSDomainsCritical bool // if true then the name constraints are marked critical.
PermittedDNSDomains []string
ExcludedDNSDomains []string
PermittedIPRanges []*net.IPNet
ExcludedIPRanges []*net.IPNet
PermittedEmailAddresses []string
ExcludedEmailAddresses []string
PermittedURIDomains []string
ExcludedURIDomains []string
// CRL Distribution Points
CRLDistributionPoints []string
PolicyIdentifiers []asn1.ObjectIdentifier
}
Holy crap, that’s a lot of parsing that’s clearly happening. Among other things, we can even see special types being used for date/time values, IP addresses, and URL’s. I definitely don’t want all that stuff being added to the attack surface of my cross-signing code – it seems almost certain that some mutation would end up happening, and it would be insane to try to audit the safety of whatever mutation occurs.
However, under the hood, after the above monstrosity is serialized and is ready to be signed, a far more manageable set of structs is used by the x509 package for the actual signing procedure:
// These structures reflect the ASN.1 structure of X.509 certificates.:
type certificate struct {
Raw asn1.RawContent
TBSCertificate tbsCertificate
SignatureAlgorithm pkix.AlgorithmIdentifier
SignatureValue asn1.BitString
}
type tbsCertificate struct {
Raw asn1.RawContent
Version int `asn1:"optional,explicit,default:0,tag:0"`
SerialNumber *big.Int
SignatureAlgorithm pkix.AlgorithmIdentifier
Issuer asn1.RawValue
Validity validity
Subject asn1.RawValue
PublicKey publicKeyInfo
UniqueId asn1.BitString `asn1:"optional,tag:1"`
SubjectUniqueId asn1.BitString `asn1:"optional,tag:2"`
Extensions []pkix.Extension `asn1:"optional,explicit,tag:3"`
}
Readers unfamiliar with Go programming should note that in Go, structs whose name has an uppercase first letter are public (accessible by code outside the Go standard library’s x509 package), while structs whose name has a lowercase first letter are private (only accessible from the Go standard library’s x509 package). These more manageable structs are private, so we can’t access them directly. But, the important thing to note is that when a raw DER-encoded byte array is parsed into a crazy-complicated Certificate, as well as when a crazy-complicated Certificate is signed (resulting in a raw DER-encoded byte array), these private structs (certificate and tbsCertificate) are used as intermediate steps, and are actually processed by the asn1 package (not the x509 package) when converting to and from raw DER-encoded byte arrays.
The first field (Raw) of each struct simply holds the unparsed binary ASN.1 representation of that struct, and we can generally ignore it. I suspect that the tbs in tbsCertificate stands for “to be signed”, since it contains all of the certificate data that the signature covers (in other words, everything except the signature). The only 5 fields that we actually will want to replace when cross-signing are the following:
- In
certificate:SignatureAlgorithmSignatureValue
- In
tbsCertificate:SerialNumberSignatureAlgorithmIssuer
When a field is of type asn1.RawValue, it means that Go won’t try to parse its content in any way (it’s just a binary blob). This is exactly the behavior we want for all the fields that we pass-through. Unfortunately, tbsCertificate has a bunch of other fields besides the above 5 replaced fields that aren’t of the type asn1.RawValue. What can we do about that? Well, since these are private structs to the x509 package, we’re clearly going to have to copy their definitions anyway – so how about we simplify them while we’re at it? Below are my modified structs:
// These are modified from the x509 package; they store any field that isn't
// replaced by cross-signing as an asn1.RawValue.
type certificate struct {
Raw asn1.RawContent
TBSCertificate tbsCertificate
SignatureAlgorithm asn1.RawValue
SignatureValue asn1.BitString
}
type tbsCertificate struct {
Raw asn1.RawContent
Version asn1.RawValue `asn1:"optional,explicit,tag:0"`
SerialNumber *big.Int // Replaced by cross-signing
SignatureAlgorithm asn1.RawValue // Replaced by cross-signing
Issuer asn1.RawValue // Replaced by cross-signing
Validity asn1.RawValue
Subject asn1.RawValue
PublicKey asn1.RawValue
UniqueId asn1.RawValue `asn1:"optional,tag:1"`
SubjectUniqueId asn1.RawValue `asn1:"optional,tag:2"`
Extensions []asn1.RawValue `asn1:"optional,explicit,tag:3"`
}
From there, I created a modified version of the x509 package’s signing code, which creates a tbsCertificate by parsing the original CA certificate that we’re cross-signing (instead of populating it with serialized data from the crazy-complicated Certificate struct as the x509 package does), and then signs it (via ECDSA) and serializes it (via the asn1 package) as usual. It then outputs a DER-encoded x509 certificate that’s identical to the original root CA cert, except for the 5 fields that I listed above as relevant to cross-signing.
The end result of all this work is a Go library, and associated Go command-line tool, that accepts the following as input:
- Original DER-encoded x509 certificate of a root CA to cross-sign
- A domain name to blacklist via a name constraint (defaults to
.bit) - Subject CommonName prefixes for the root and intermediate CA’s (defaults to “Namecoin Restricted CKBI Root CA for “ and “Namecoin Restricted CKBI Intermediate CA for “), which are prepended to the cross-signed CA’s Subject CommonName when creating the root and intermediate CA’s (the intention here is to make it easy to recognize these CA’s as special based on their names)
… and outputs the following:
- DER-encoded x509 certificate of a new self-signed root CA (whose private key is destroyed)
- DER-encoded x509 certificate of a new intermediate CA (whose private key is destroyed) that has a name constraint, signed by the new root CA
- DER-encoded x509 certificate of the input root CA, cross-signed by the new intermediate CA
The root and intermediate CA’s also have a Subject SerialNumber that contains the following message:
“This certificate was created on this machine to apply a name constraint to an existing root CA. Its private key was deleted immediately after the existing root CA was cross-signed. For more information, see [TODO]”
(Of course, the Subject SerialNumber of the intermediate CA is also visible as the Issuer SerialNumber of the cross-signed CA.) The intention here is that if someone encounters one of these certificates, they’ll notice the SerialNumber message and therefore they won’t mistakenly assume that their system has been compromised by a malicious CA certificate. (The “[TODO]” will be replaced later by a URL that contains additional information and explains how to get the source code.) Kudos to Ryan Castellucci for tipping me off that the Subject SerialNumber field was well-suited to this trick.
With this Go command-line tool, I applied a name constraint blacklisting .org to the certificate of DST Root CA X3 (as in my previous post, this is the root CA that Let’s Encrypt uses), and I got 3 new certificates as output. I added those 3 certs to NSS’s sqlite database via certutil (marking the new root CA as trusted), marked the old root CA as untrusted, and tried visiting the same 2 sites that use Let’s Encrypt that I used in my previous post (Technoethical and Namecoin.org). And happily, it worked just as my old OpenSSL+Bash version did: Technoethical loaded without errors (since it’s in the .com TLD, which I didn’t blacklist), but Namecoin.org showed a TLS certificate error (since it’s in the .org TLD that I chose to blacklist).
This worked in both Chromium and Firefox on GNU/Linux. And inspecting the resulting cross-signed certificate shows that all of the x509v3 extensions, validity period, etc. from the original DST Root CA X3 are passed through intact. Yay!
So, what’s next? Right now, this still takes a single root CA as input (and the user is still responsible for passing in the input root CA, and making the needed changes to NSS’s database using the outputted CA’s). I’ve started work on a Go program that will automate this procedure for all root CA’s in NSS; I’d say it’s somewhere around 50% complete. Once it’s complete, this should allow us to continue supporting Chromium on GNU/Linux (even after Chromium removes HPKP), and it should also allow us to add support for Firefox on all OS’s (without requiring any WebExtensions support).
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin at 34C3: Slides and Videos
CCC and Chaos West have posted the videos of Namecoin’s 34C3 talks. I’ve also uploaded the corresponding slides.
- Namecoin as a Decentralized Alternative to Certificate Authorities for TLS
- Video recording by Chaos West, hosted by CCC.
- Slides hosted by Namecoin.org.
- Namecoin for Tor Onion Service Naming (And Other Darknets)
- (No video recording available.)
- Slides hosted by Namecoin.org.
- A Blueprint for Making Namecoin Anonymous
- Video recording by Chaos West, hosted by CCC.
- Slides hosted by Namecoin.org.
Again, a huge thank you to the following groups who facilitated our participation at 34C3:
We’re looking forward to 35C3!
Negative Certificate Overrides for p11-kit
Fedora stores its TLS certificates via a highly interesting software package called p11-kit. p11-kit is designed to act as “glue” between various TLS libraries, so that (for example) Firefox, Chromium, and OpenSSL all see the same trust anchors. p11-kit is useful from Namecoin’s perspective, since it means that if we can implement Namecoin support for p11-kit, we get support for all the trust stores that p11-kit supports for free. I’ve just implemented a proof-of-concept of negative Namecoin overrides for p11-kit.
As you may recall, the way our Chromium negative overrides currently work is by abusing utilizing HPKP such that public CA’s can’t sign certificates for the .bit TLD. p11-kit doesn’t support key pinning (it’s on their roadmap though!), but there is another fun mechanism we can use to achieve a similar result: name constraints. Name constraints are a feature of the x509 certificate specification that allows a CA certificate to specify constraints on what domain names it can issue certificates for. There are a few standard use cases for name constraints:
- A large organization who wants to create a lot of certificates might buy a name-constrained CA certificate from a public CA, and then use that name-constrained CA to issue more certificates for their organization. This reduces the overhead of asking a public CA to issue a lot of certificates on-demand, and doesn’t introduce any security issues because the name constraint prevents the organization from issuing certificates for domain names that they don’t control.
- A corporate intranet might create a name-constrained root CA that’s only valid for domain names that are internal to the corporate intranet. This way, employees can install the name-constrained root CA in order to access internal websites, and they don’t have to worry that the IT department might be MITM’ing their connections to the public Internet.
- A public CA might have a name constraint in their CA certificate that disallows them from issuing certificates for TLD’s that have unique regulatory requirements. For exampe, the Let’s Encrypt CA has (or at one point had) a name constraint disallowing
.mil, presumably because the U.S. military has their own procedures for issuing certificates.
The 1st use case is rarely ever used; I suspect that this is because it poses a risk to commercial CA’s’ business model. The 2nd use case is also rarely ever used; I suspect this is because many corporate IT departments want to MITM all their employees’ traffic, and most employees don’t have much negotiating power on this topic. But the 3rd case is quite interesting… if Let’s Encrypt uses a name constraint blacklisting .mil, could this be used for .bit?
Unfortunately, we obviously can’t expect all of the public CA’s to have any interest in opting into a name constraint disallowing .bit in the way that Let’s Encrypt opted into disallowing .mil. However, there is a fun trick that can solve this: cross-signed certificates. It turns out that it is possible to transform a public root CA certificate into an intermediate CA certificate, and sign that intermediate CA certificate with a root CA that we can create locally (this is called cross-signing). We can then remove the original root CA from the cert store, add our local root CA and the cross-signed CA to the cert store, and everything will work just like it did before. This is helpful because any name constraints that a CA certificate contains will apply to any CA certificate that it cross-signs.
Technically, the RFC 5280 specification says that root CA’s can’t have name constraints. That’s not really a problem though: it just means that we have to create a local intermediate CA (signed by the local root CA) that has the name constraint, and cross-sign the public CA with the name-constrained local intermediate CA. So the cert chain looks like this:
Local root CA (no name constraint) –> Local intermediate CA (name constraint blacklisting .bit) –> Cross-signed public CA –> (everything past here is unaffected).
Huge thanks to Crypt32 and davenpcj from Server Fault for first cluing me in that this approach would work. Unfortunately, Crypt32 didn’t provide any sample code, and the sample code from davenpcj didn’t work as-is for me (OpenSSL kept returning various errors when I tried to cross-sign, most of which seemed to be because OpenSSL didn’t like the fact that the public CA hadn’t signed an authorization for me to cross-sign their CA). I eventually managed to cobble together a Bash script using OpenSSL that did work, but I don’t think OpenSSL’s command-line tool is really the right tool for the job (OpenSSL tends to rewrite large parts of the cross-signed certificate in ways that are likely to cause compatibility and security problems). I’m probably going to rewrite this as a Go program.
Anyway, with my Bash script, I decided to apply a name constraint to DST Root CA X3, which is the root CA that Let’s Encrypt uses. The name constraint I applied blacklists the .org TLD (obviously I can’t use .bit for testing this, since no public CA’s are known to have issued a certificate for a .bit domain). And… it works! The Bash script installed the local root CA as a trust anchor for p11-kit, installed the intermediate and cross-signed CA’s as trust-neutral certificates for p11-kit, and installed a copy of the original DST Root CA X3 certificate to the p11-kit blacklist. As a result, both Chromium and Firefox still work fine with Let’s Encrypt for .com websites such as Technoethical, but return an error for .org websites such as Namecoin.org – exactly the behavior we want.
I also made a modified version of my Bash script that installs the modified CA’s into a standard NSS sqlite3 database (without p11-kit), and confirmed that this works with both Firefox and Chromium on GNU/Linux. So p11-kit probably won’t be a hard dependency of this approach, meaning that this approach is likely to work for Firefox on all OS’s, Chromium on all GNU/Linux distros, and anything else that uses NSS.
This code needs a lot of cleanup before it’s ready for release; among the ToDos are:
- Port the certificate handling code to a Go program instead of OpenSSL’s command line.
- Automatically detect which root CA’s exist in p11-kit, and apply the name constraint to all of them, instead of only using
DST Root CA X3. - Automatically detect when a public root CA is deleted from p11-kit (e.g. WoSign), and remove the name-constrained CA that corresponds to it.
- Preserve p11-kit’s attached attributes for trust anchors.
- Make the procedure idempotent.
- Test whether this works as intended for other p11-kit-supported libraries (Firefox and Chromium use NSS; p11-kit also supports OpenSSL, Java, and GnuTLS among others).
- Test whether a similar approach with name constraints can work for CryptoAPI (this would be relevant for most non-Mozilla browsers on Windows).
I’m hopeful that this work will allow us to continue supporting Chromium on GNU/Linux after Chromium removes HPKP, and that it will nicely complement the Firefox positive override support that I added to ncdumpzone.
It should be noted that this approach definitely will not work on most non-Mozilla macOS browsers, because macOS’s TLS implementation does not support name constraints. I’m not aware of any practical way to do negative overrides on macOS (besides the deprecated HPKP support in Chromium), so there’s a chance that when we get around to macOS support, we’ll just not do negative overrides for macOS (meaning that while Namecoin certificates would work on macOS without errors, malicious public CA’s would still be able to do MITM attacks against macOS users just like they can for DNS domain names). Firefox on macOS shouldn’t have this problem, since Firefox doesn’t use the OS for certificate verification.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Adding a Firefox TLS Mode to ncdumpzone
Firefox stores its list of certificate overrides in a text file. While it’s not feasible to edit this text file while Firefox is running (Firefox only loads it on startup) I’ve experimentally found that it is completely feasible to create positive overrides if you shut off Firefox while the override is being created. But is this a reasonable expectation for Namecoin? Actually yes. Here’s how we’re doing it:
Note that most Namecoin users are doing name lookups via one of the following clients:
- Namecoin Core (in full node mode)
- Namecoin Core (in pruned mode)
- libdohj-namecoin (in
leveldbtxcachemode)
These have an important feature in common: they all keep track of the UNO (unspent name output) set locally. That means that you don’t need to wait for a DNS lookup to be hooked before you process a TLSA record from the blockchain – you can process TLSA records in advance, before Firefox even boots!
Note that the above is not true for the following cases:
- libdohj-namecoin (in API server mode)
.bitdomains that are delegated to a DNSSEC server
So, what we need is a tool that walks the entire Namecoin UNO set, processes each name, and writes out some data about the TLSA records. Coincidentally, this is very similar to what ncdumpzone does. ncdumpzone is a utility distributed with ncdns. It exports a DNS zonefile of the .bit zone, which is intended for users who for some reason want to use BIND as an authoritative nameserver instead of using ncdns directly. However, with some minimal tweaking, we can make ncdumpzone export the .bit zone in some other format… such as a Firefox certificate override list format.
For example, this command:
./ncdumpzone --format=firefox-override --rpcuser=user --rpcpass=pass > firefox.txt
Resulted in the following file being saved:
nf.bit:443 OID.2.16.840.1.101.3.4.2.1 13:E7:03:D6:A2:70:1E:77:41:21:F5:84:6D:3E:0B:FD:5F:00:B7:6B:47:96:82:E3:A2:B0:54:A0:25:76:0A:1A U AAAAAAAAAAAAAAAAAAAAAA==
test.veclabs.bit:443 OID.2.16.840.1.101.3.4.2.1 66:86:29:37:ED:53:B3:CE:2B:9B:A5:30:4D:59:83:35:4C:EC:80:9A:1F:39:DC:37:87:6E:00:4B:AF:08:3E:BA U AAAAAAAAAAAAAAAAAAAAAA==
www.aoeu2code.bit:443 OID.2.16.840.1.101.3.4.2.1 13:E3:2D:1B:05:B5:DC:57:94:3D:17:EC:99:25:3F:AF:54:87:7E:62:FC:51:18:06:B7:F4:87:51:62:3A:3B:1C U AAAAAAAAAAAAAAAAAAAAAA==
markasoftware.bit:443 OID.2.16.840.1.101.3.4.2.1 43:B4:EA:FC:FF:25:CC:85:A9:3D:CE:75:55:31:C9:DB:60:AF:06:C3:65:E5:28:62:08:20:DD:62:F4:70:0E:7D U AAAAAAAAAAAAAAAAAAAAAA==
These 4 lines correspond to the only 4 TLSA records that exist in the Namecoin blockchain right now. Obviously, the first part of each line is the domain name and port of the website. OID.2.16.840.1.101.3.4.2.1 signifies that the fingerprint uses the SHA256 algorithm. (This is the only one that Firefox has ever supported, but Firefox is designed to be future-proof in case a newer hash function becomes necessary.) Next comes the fingerprint itself, in uppercase colon-delimited hex. U indicates that the positive override is capable of overriding an “untrusted” error (it can’t override validity period or domain name mismatch errors). The interesting part is AAAAAAAAAAAAAAAAAAAAAA==, which Mozilla’s source code refers to as a dbKey. Mozilla’s source code always calculates this using the issuer and serial number of the certificate. However, empirically it works just fine if I instead use all 0’s (in the same base64 encoding). Looking at the Mozilla source code, the dbKey isn’t actually utilized in the process of checking whether an override exists. I’m not certain exactly what Mozilla is using it for (it seems to be used in a code path that’s related to enumerating all the overrides that exist). Since the issuer and serial number aren’t always derivable from TLSA records (you generally need either a dehydrated certficate or a full certificate for this; my goal here is to work even if only the SHA256 fingerprint of a cert is known), we just set it to all 0’s.
Copying the above output into Firefox’s cert override file, and then starting up Firefox, I was able to access the Namecoin forum’s .bit domain without any TLS errors. I’ve submitted a PR to ncdns.
While I was writing this code, I noticed that ncdns was actually calculating TLSA records incorrectly. One of the bugs in TLSA record calculation was already known (Jefferson Carpenter reported it last month), while the other was unnoticed (the TLSA records contained a rehydrated certificate that accidentally included a FQDN as the domain name; the erroneous trailing period caused the signatures and fingerprints to fail verification). The fact that these bugs in my TLSA code remained unnoticed for about a year seems to be evidence that no one is actually using TLSA over DNS with Namecoin in the real world; the only Namecoin TLS users are using ncdns’s certinject feature, which did not have this bug.
It should be noted that this approach isn’t secure in the sense that Namecoin TLS with Chromium is, because it doesn’t provide negative overrides (meaning that a public CA could issue a malicious .bit certificate that wouldn’t be blocked by this method). However, positive and negative overrides are mostly orthogonal goals in terms of implementation, so this is huge progress while we wait for proper WebExtensions support for TLS overrides. I also think it’s likely to be feasible to implement negative overrides using NSS, in a way that Firefox will honor. More on that in a future post.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Positive TLS Certificate Overrides for NSS
NSS is the TLS implementation used by various applications, including Chromium on GNU/Linux and Firefox on all platforms. I’ve finished initial support for positive cert overrides in NSS, and have submitted a PR that is now awaiting review.
I had previously written a WIP PR that implemented positive overrides for NSS, but it worked by using an NSS database directory that was auto-detected based on the active user’s home directory. This seemed like a clever usability trick, but it had 2 severe disadvantages:
- Some applications don’t use the shared NSS database, but instead use their own. Firefox is one of these applications.
- For security reasons, we want ncdns to run as its own user with restricted permissions. This would break the database directory auto-detection.
The new PR has explicit configuration options for which NSS database directory is used. For example, the following command line config:
./ncdns -ncdns.namecoinrpcusername=user -ncdns.namecoinrpcpassword=pass -certstore.nss -certstore.nsscertdir="$(pwd)"/certs -certstore.nssdbdir=/home/user/.pki/nssdb -xlog.severity=DEBUG
Allowed the Namecoin Forum’s .bit domain to load in Chromium in my Fedora VM without any TLS errors. Obviously, this would need to be combined with the negative override functionality provided by the tlsrestrict_chromium_tool program (included with ncdns) in order to actually have reasonable security (otherwise, public TLS CA’s could issue .bit certs that would still be accepted by Chromium).
Some remaining challenges:
- NSS’s
certutilis extremely slow, due to failure to properly batch operations into sqlite transactions. I’ve filed a bug about this with Mozilla. Until this is fixed, expect an extra ~800ms of latency when accessing Namecoin HTTPS websites. Possible future workarounds:- Run
certutilsometime before the DNS hook, so that 800ms of latency isn’t actually noticeable for the user. (More on this in a future post.) - Do some highly horrifying
LD_PRELOADwitchcraft in order to fix the crappy sqlite usage. - Use a different pkcs11 backend instead of NSS’s sqlite3 backend. (Yes, NSS uses pkcs11 behind the scenes. More on this in a future post.)
- Run
- Firefox doesn’t actually respect NSS’s trust anchors when the trust anchor is an end-entity certificate. Possible future workarounds:
- Use a Firefox-specific positive override mechanism. (More on this in a future post; also see the WebExtensions posts.)
- Inject CA certs rather than end-entity certs. (More on this in a future post.)
- Some NSS applications don’t use the sqlite backend, but instead use BerkeleyDB as a backend. BerkeleyDB can’t be opened concurrently by multiple applications, so ncdns can’t inject certs while another application is open. Possible future workarounds:
- Use an environment variable to force sqlite usage.
- Run
certutilwhile the database isn’t open. - Use a different pkcs11 backend.
- Wait for those applications to switch to sqlite. (Firefox switched in Firefox 58, and it appears more applications may follow suit.)
That said, despite the need for future work, this PR makes Namecoin TLS fully functional in Chromium on GNU/Linux. (Until negative overrides stop working due to HPKP being removed… more on potential fixes in a future post.)
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 6 (Negative Override Cache in C++, WebExtension Aggregation, and Coordination with Mozilla)
In Phase 5 of Namecoin TLS for Firefox, I discussed the performance benefits of moving the positive override cache from JavaScript to C++. I’ve now implemented preliminary work on doing the same for negative overrides.
The code changes for negative overrides’ C++ cache are analogous to those for positive overrides, so there’s not much to cover in this post about those changes. However, I did take the chance to refactor the API between the C++ code and the JavaScript code a bit. Previously, only 1 WebExtension was able to perform overrides; if multiple WebExtensions registered for the API, whichever replied first would be the only one that had any effect. Now, each WebExtension replies separately to the Experiment, and the Experiment passes those replies on to the C++ code. The Experiment also notifies the C++ code when all of the WebExtensions have replied. Although this does add some extra API overhead, it has the benefit of allowing an override to take place immediately if a single WebExtension has determined that it should take place, even if the other (irrelevant) WebExtensions are still evaluating the certificate.
Unfortunately, at this point I merged upstream changes from Mozilla into my Mercurial repository, only to find that there was now a compile error. I’m still figuring out exactly why this compile error is happening. It looks like it’s unrelated to any of the files that my patch touches; I suspect that it’s due to my general lack of competence with Mercurial (Mozilla’s codebase is the first time I’ve used Mercurial) or my similar general lack of competence with Mozilla’s build system.
So, until I actually get the code to build, I won’t be able to do performance evaluations of these changes. Hence why there are no pretty graphs in this post.
Meanwhile, I reached out to Mozilla to get some feedback on the general approach I was taking. (I had previously discussed high-level details with Mozilla, but this time I provided a WIP code patch, so that it would be easier to evaluate whether I was doing anything with the code that would be problematic.) This resulted in a discussion about what methods should be used to prevent malicious or buggy extensions from causing unexpected damage to user security. This is definitely a legitimate concern: messing with certificate verification is dangerous when done improperly, and it’s important that users understand what they’re getting when they install a WebExtension that might put them at risk. That discussion is still ongoing, and it’s not clear yet what the consensus will arrive at.
(It should be noted that there are some alternative approaches to Firefox support for Namecoin TLS underway as well, which will be covered in a future post.)
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Pruning of Non-scriptPubKey Data in libdohj
Our lightweight SPV client’s leveldbtxcache mode is the most secure of the various Namecoin lightweight SPV modes. Its storage requirements aren’t too bad either (129.1 MB at the moment for Namecoin mainnet). However, while 129.1 MB of storage isn’t a dealbreaker, it’s still a bit borderline on mobile devices. We can do better.
First, a reminder of how leveldbtxcache currently works. Initially, the IBD (initial blockchain download) proceeds the same way a typical lightweight SPV Bitcoin client (such as Schildbach’s Android Bitcoin Wallet) would work: it downloads blockchain headers, aiming for the chain with the most work. However, at the point when the IBD has reached 1 year ago in the blockchain, it begins downloading full blocks instead of block headers. The full blocks aren’t saved; they’re used temporarily for 2 purposes: verifying consistency with the block headers’ Merkle root (thus ensuring that no transactions have been censored), and adding any name_anyupdate transactions to a LevelDB database that allows quick lookup of names. After those 2 things have been processed, the full blocks are discarded. The 129.1 MB storage figure is as low as it is because we’re only storing name transactions from the last year (plus block headers, which are negligible in size).
However, there’s a lot of data in name transactions that we don’t actually need in order to look up names: currency data, signatures, and transaction metadata.
Currency data exists in name transactions because name operations cost a transaction fee, so there will typically be a currency input and a currency output in any name transaction. We don’t need this information in order to look up names. Signatures are used for verifying new transactions, but are not needed to look up previously accepted transaction data. Transaction metadata, such as nVersion and nLockTime, is also not needed to look up names. There may be other sources of unwanted data too.
To improve the situation, I’ve just modified leveldbtxcache so that, instead of storing full name transactions in LevelDB, it only stores the scriptPubKey of the name output. This includes the name’s identifier and value, as well as the Bitcoin-compatible scriptPubKey that can be used to verify future signatures. It’s a relatively straightforward change to the code, although it does break backward-compatibility with existing name databases (so you’ll need to delete your blockchain and resync after updating).
So, how does this fare?
| Full Transactions | Only scriptPubKey |
|
|---|---|---|
| Storage Used after IBD | 129.1 MB | 63.7 MB |
| Time Elapsed for IBD | ~9 Minutes | ~6 minutes |
Not bad, and we even got a faster IBD as a bonus. (This suggests that the bottleneck, at least on my laptop running Qubes with an HDD, was storage I/O.)
I’ve just submitted this change to upstream libdohj.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin Core 0.15.99-name-tab-beta1 Released
Namecoin Core 0.15.99-name-tab-beta1 has been released on the Beta Downloads page. Changes since 0.13.99-name-tab-beta1:
- New features:
- GUI
- Significant rewrite of name GUI. (Patch by brandonrobertz.) In particular, please torture-test the following:
- Full flow for registering names.
- Full flow for updating and renewing names.
- State display in the names list.
- The above with mainnet, testnet, and regtest networks.
- The above with encrypted locked, encrypted unlocked, and unencrypted wallets.
- Significant rewrite of name GUI. (Patch by brandonrobertz.) In particular, please torture-test the following:
- RPC
- Remove name operation from
createrawtransactionRPC method; addnamerawtransactionRPC method. This paves the way for various future improvements to the name GUI, including coin control, anonymity, fee control, registration without unlocking the wallet twice, and decreased transaction size. You’ll need to update your scripts if you currently use the raw transaction API for name transactions. (Reported by JeremyRand, patch by domob1812.) - Restore
getblocktemplateRPC method. This improves workflow for software used by Bitcoin mining pools. (Reported by DrHaribo, patch by domob1812.) - Add
createauxblockandsubmitauxblockRPC methods. This improves workflow for software used by Bitcoin mining pools. (Patch by bitkevin.)
- Remove name operation from
- GUI
- Fixes:
- GUI
- Fix pending name registration bug, where the GUI requests a wallet unlock over and over and then errors with name registered. (Patch by brandonrobertz.)
- Fix bug where names weren’t showing up in the Manage Names list properly until client had been restarted. (Patch by brandonrobertz.)
- P2P
- Update seed nodes. This should decrease likelihood of getting stuck without peers. (Patch by JeremyRand.)
- RPC
- Fix crash when user attempts to broadcast an invalid raw transaction containing multiple
name_updateoutputs. (Reported by maxweisspoker, patch by domob1812.)
- Fix crash when user attempts to broadcast an invalid raw transaction containing multiple
- GUI
- Improvements from upstream Bitcoin Core.
Unfortunately, Windows and macOS builds are broken in this release, so only GNU/Linux binaries are available. We expect Windows and macOS builds to be restored for the 0.15.99-name-tab-beta2 release, which is coming soon.
Recent Reports of Ransomware Using Namecoin are Missing the Real Story
Some reports are making the rounds that a new ransomware strain, “GandCrab”, is using Namecoin for C&C. While this may sound interesting, as far as I can tell these reports are missing the real story.
Looking at the report on Bleeping Computer, we see these quotes:
Another interesting feature is GandCrab’s use of the NameCoin .BIT top-level domain. .BIT is not a TLD that is recognized by the Internet Corporation for Assigned Names and Numbers (ICANN), but is instead managed by NameCoin’s decentralized domain name system.
The developers of GandCrab are using NameCoin’s DNS as it makes it harder for law enforcement to track down the owner of the domain and to take the domains down.
This doesn’t make much sense, since Namecoin isn’t anonymous (so tracking down the owner of the domain is relatively straightforward for law enforcement). But more to the point, most Internet users don’t have Namecoin installed, and it would be rather odd for ransomware to bundle a Namecoin name lookup client. This confusion is explained by Bleeping Computer (to their credit):
This means that any software that wishes to resolve a domain name that uses the .BIT tld, must use a DNS server that supports it. GandCrab does this by making dns queries using the a.dnspod.com DNS server, which is accessible on the Internet and can also be used to resolve .bit domains.
Yep, if this is to be believed, GandCrab isn’t actually using Namecoin, they’re using a centralized DNS server (a.dnspod.com) which nominally claims to mirror the namespace of Namecoin. This means that, if law enforcement wants to censor the C&C .bit domains, they don’t need to censor Namecoin (which would be rather difficult), they simply need to look up who owns dnspod.com (under ICANN policy, looking this up is straightforward for law enforcement) and send them a court order to censor the C&C domains.
However, Bleeping Computer is actually substantially wrong on this point. Why? Take a look in the Namecha.in block explorer at the Namecoin value of bleepingcomputer.bit, which is one of the alleged C&C domains:
{"ns":["A.DNSPOD.COM","B.DNSPOD.COM"]}
First off, note that this is actually a completely invalid Namecoin configuration, because the trailing period is missing from the authoritative nameserver addresses, so any DNS software that tries to process that Namecoin domain will return SERVFAIL. Second, note that the authoritative nameservers listed are… the dnspod.com nameservers. This makes it pretty clear that a.dnspod.com isn’t actually a Namecoin DNS inproxy. If it were, and even if the trailing-period fail were corrected in the Namecoin value, the inproxy would end up in a recursion loop. a.dnspod.com is actually just a random authoritative nameserver that happens to be serving records for a domain name that ends in .bit. Namecoin isn’t used anywhere by GandCrab, and killing the Namecoin domain wouldn’t have any effect on GandCrab. Of course, this raises questions about why exactly that domain name is even registered in Namecoin. The simplest explanations are:
- The GandCrab developers are massively incompetent, and have potentially deanonymized themselves by registering a Namecoin domain despite not ever using that Namecoin domain for their ransomware.
- Someone unrelated to GandCrab has registered that Namecoin domain for the purpose of trolling security researchers.
It’s conceivable that dnspod.com’s nameservers will only allow a .bit domain’s records to be served from their systems if that .bit domain’s Namecoin data points to dnspod.com’s namservers, and it’s further possible that their systems are misconfigured to not notice that the trailing period is missing. However, this seemed rather unlikely to me. Why? Well, first, take a look at the WHOIS data for dnspod.com:
Registrar URL: http://www.dnspod.cn
Registrar: DNSPod, Inc.
Registrar IANA ID: 1697
So DNSPod is apparently an ICANN-accredited DNS registrar, with a primary domain name in China. Which of these scenarios fits better with Occam’s Razor:
- A DNS registrar located in China (which is not exactly known for its government’s respect for Namecoin’s values of free speech), which is accredited by ICANN (which doesn’t recognize Namecoin as either a DNS TLD or a special-use TLD), is doing special processing of domain names that they host in order to respect the authority of Namecoin. They’ve also never contacted the Namecoin developers to inform us that they’re doing this, nor are any of their technical people active in the Namecoin community.
- DNSPod simply doesn’t care what domains their customers host on their nameservers, since if DNSPod’s nameservers aren’t authorized by a domain’s NS record in the DNS, nothing bad will happen anyway (DNSPod simply won’t receive any requests for that domain).
In addition, if DNSPod had such a policy, it’s not clear how exactly their customers would be able to switch their Namecoin domains to DNSPod nameservers without encountering downtime while DNSPod was waiting for the Namecoin transaction to propagate.
However, since empiricism is informative, Ryan Castellucci tested this with an account on DNSPod, and confirmed that no such validation occurs:
$ dig +tcp jeremyrandissomesortofhumanperson.bit @a.dnspod.com
; <<>> DiG 9.9.5-9+deb8u14-Debian <<>> +tcp jeremyrandissomesortofhumanperson.bit @a.dnspod.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23586
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;jeremyrandissomesortofhumanperson.bit. IN A
;; ANSWER SECTION:
jeremyrandissomesortofhumanperson.bit. 600 IN A 255.255.255.255
;; AUTHORITY SECTION:
jeremyrandissomesortofhumanperson.bit. 600 IN NS b.dnspod.com.
jeremyrandissomesortofhumanperson.bit. 600 IN NS c.dnspod.com.
jeremyrandissomesortofhumanperson.bit. 600 IN NS a.dnspod.com.
;; Query time: 595 msec
;; SERVER: 101.226.79.205#53(101.226.79.205)
;; WHEN: Wed Jan 31 03:04:24 UTC 2018
;; MSG SIZE rcvd: 160
(Ryan doesn’t own jeremyrandissomesortofhumanperson.bit.) Ryan also did the same for bleepingcomputer.iq, implying that DNSPod isn’t verifying ownership of DNS domain names either:
$ dig +tcp bleepingcomputer.iq @a.dnspod.com A
; <<>> DiG 9.9.5-9+deb8u14-Debian <<>> +tcp bleepingcomputer.iq @a.dnspod.com A
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50149
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;bleepingcomputer.iq. IN A
;; ANSWER SECTION:
bleepingcomputer.iq. 600 IN A 8.8.8.8
;; AUTHORITY SECTION:
bleepingcomputer.iq. 600 IN NS a.dnspod.com.
bleepingcomputer.iq. 600 IN NS b.dnspod.com.
bleepingcomputer.iq. 600 IN NS c.dnspod.com.
;; Query time: 5758 msec
;; SERVER: 101.226.79.205#53(101.226.79.205)
;; WHEN: Wed Jan 31 03:00:39 UTC 2018
;; MSG SIZE rcvd: 142
Ryan tried registering a .onion domain and bleepingcomputer.malware on DNSPod as well, but these were rejected as invalid TLD’s. Ryan and I have no clue why .bit is on DNSPod’s TLD whitelist while .onion isn’t – probably because a customer asked for it and DNSPod just doesn’t care.
Ryan isn’t aware of any prior cases where a malware C&C was set up in a random free authoritative DNS provider such as DNSPod, with the DNS servers hardcoded in the malware. It’s an interesting strategy for malware authors, since authoritative DNS providers usually don’t bother to confirm domain name ownership. Entertainingly, Ryan found that DNSPod isn’t verifying ownership of the email addresses used to register accounts either.
So in conclusion: while this is a rather interesting case of a possible hilarious opsec fail by a ransomware author (which very well might get them arrested), and the strategy of using authoritative DNS hosting providers for malware C&C is fascinating as well, the ransomware itself is fully irrelevant to Namecoin.
34C3 Summary
As was previously announced, Jonas Ostman and I (Jeremy Rand) represented Namecoin at 34C3 in Leipzig, Germany. This was our first Congress, so we didn’t quite know what to expect, but we were pretty confident that it would be awesome. We were not disappointed. The CCC community is well-known for being friendly and welcoming to newcomers, and we greatly enjoyed talking to everyone there.
Namecoin gave 3 talks, all of which were hosted by the Monero Assembly and the Chaos West Stage. I expect 2 of those talks to have videos posted sometime later this month. Unfortunately, 1 of the talks suffered an audio issue in the recording, so it won’t have a video posted (but I will post the slides of that talk, as well as the other talks’ slides). The talks’ titles are:
- Namecoin as a Decentralized Alternative to Certificate Authorities for TLS
- Namecoin for Tor Onion Service Naming (And Other Darknets) (No video will be posted due to audio recording technical issues)
- A Blueprint for Making Namecoin Anonymous
As usual for conferences that we attend, we engaged in a large number of conversations with other attendees. Also as usual, I won’t be publicly disclosing the content of those conversations, because I want people to be able to talk to me at conferences without worrying that off-the-cuff comments will be broadcast to the public. That said, I can say that a lot of very promising discussions happened regarding future collaboration with allied projects, and we’ll make any relevant announcements when/if such collaborations are formalized.
Huge thank you to the following groups who facilitated our participation:
We definitely intend to return for 35C3 in December 2018. Until then, Tuwat!
Namecoin’s Jeremy Rand and Jonas Ostman will be at 34C3
Namecoin developers Jeremy Rand and Jonas Ostman will attend 34C3 (the 34th Chaos Communication Congress) in Leipzig, December 27-30. There’s a good chance that the 34C3 Monero Assembly will host some Namecoin talks. We’re looking forward to the congress!
Namecoin Lightweight SPV Lookup Client 0.2.7 Beta 1 Source Code Available
Version 0.2.7 Beta 1 of the Namecoin Lightweight SPV Lookup Client has had its source code released. Build instructions are here (it’s the “bleeding-edge branch”). Binaries will be made available later. Meanwhile, the former bleeding-edge branch (the branch that introduced leveldbtxcache mode) has graduated to partially-stable. The former partially-stable branch has been deprecated.
Happily, the 0.2.7 Beta 1 release is using an unmodified upstream libdohj, since Ross Nicoll from Dogecoin has merged all of my changes. I’m still working to get the relevant ConsensusJ (formerly bitcoinj-addons) code merged upstream. As usual, the SPV client is experimental. Namecoin Core is still substantially more secure against most threat models.
Update on Namecoin Core Qt Development
It’s been roughly a year since the initial manage names tab
code was ported from legacy Namecoin to Namecoin Core. Since then, development
of namecoin-qt has been progressing on two fronts: merging the manage names Qt
interface into Namecoin Core’s master branch and the development of a d/ spec
DNS configuration interface.
In October, I initiated a pull request to merge the manage names tab into Namecoin Core’s master branch. This patch replaces the previous, experimental manage names (v0.13.99) interface and brings it current with Namecoin Core version 0.15.99. There have been many bugfixes and improvements, so we welcome users to test the code and report any issues.
Secondly, thanks to support
from the NLnet Foundation’s Internet Hardening Fund, I’ve began developing the
DNS configuration dialog. The goal is to make managing Namecoin domains much simpler
and will remove the need for many users to build d/ spec JSON documents
altogether. We currently have a set of mocks available
for comments from users. Until a pull request is issued, development can be tracked
in the manage-dns
branch of my Namecoin Core repo.
Development is moving quickly, so I will continue to update the community as things progress. As usual, you can follow our work in the GitHub repo and on the Namecoin Subreddit.
Namecoin will be at the 2017 Oklahoma City Fall Peace Festival
Namecoin will have a table at the 2017 Fall Peace Festival in Oklahoma City on November 11. If you happen to be in the OKC area, feel free to stop by and say hello.
What Chromium’s Deprecation of HPKP Means for Namecoin
Readers who’ve been paying attention to the TLS scene are likely aware that Google has recently announced that Chromium is deprecating HPKP. This is not a huge surprise to people who’ve been paying attention; HPKP has had virtually no meaningful implementation by websites, and many security experts have been warning that HPKP is too dangerous for most deployments due to the risk that websites who use it could, with a single mistake, accidentally DoS themselves for months. The increased publicity of the RansomPKP attack drove home the point that this kind of DoS could even happen to websites who don’t use HPKP. I won’t comment on the merits of HPKP for its intended purpose. However, readers familiar with Namecoin will probably be aware that Namecoin’s TLS support for Chromium relies on HPKP. So, what does HPKP’s deprecation mean for Namecoin?
First off, nothing will happen on this front until Chrome 67, which is projected to release as Stable on May 29, 2018. (Users of more cutting-edge releases of Chromium-based browsers will lose HPKP earlier.) When Chrome 67 is released, I expect that the following behavior will be observed for the current ncdns release (v0.0.5):
- The ncdns Windows installer will probably continue to detect Chromium installations (because the HPKP state shares a database with the HSTS state, which isn’t going anywhere). The NUMS HPKP installation will appear to succeed.
- ncdns will continue to be able to add certificates to the trust store. This means that
.bitwebsites that use TLS will continue to load without errors. - The NUMS HPKP pin will silently stop having any effect. This means that Namecoin’s TLS security will degrade to that of the CA system. A malicious CA that is trusted by Windows will be able to issue certificates for
.bitwebsites, and Chromium will accept these certificates as valid even when they don’t match the blockchain.
Astute readers will note that this is the 4th instance of a browser update breaking Namecoin TLS in some way. (The previous 3 cases were Firefox breaking Convergence, Firefox breaking nczilla, and Firefox breaking XPCOM.) In this case, we’re reasonably well-prepared. Unlike the Convergence breakage (which Mozilla considered to be a routine binary-size optimization) and the nczilla breakage (which Mozilla considered to be a security patch), HPKP is a sufficiently non-niche functionality that we’re finding out well in advance (much like the XPCOM deprecation). As part of my routine work at Namecoin, I make a habit of studying how TLS certificate verification works in various common implementations, and regularly make notes on ways we could hack them in the future to use Namecoin. Based on a cursory review of my notes, there are at least 7 possible alternatives to Chromium’s HPKP support that I could investigate for the purpose of restoring Namecoin’s TLS security protections in Chromium. 3 of them would be likely to qualify for NLnet funding, if we decided to divert funding from currently-planned NLnet-funded tasks. (It’s not clear to me whether we actually will divert any funding at this point, but we do have the flexibility to do so if it’s needed.) None of those 7 alternative approaches are quite as nice as our NUMS HPKP approach (which is why we’ve been using NUMS HPKP up until now), but such is life.
In conclusion, while this news does highlight the maintenance benefits of using officially approved API’s rather than hacks (which, it should be noted, is my current approach for Firefox), at this time there is no reason for Namecoin to drop TLS support for Chromium. I’m continuing to evaluate what our best options are, and I’ll report back when I have more information.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 5 (Moving the Override Cache to C++)
In Phase 4 of Namecoin TLS for Firefox, I mentioned that more optimization work remained (despite the significant latency improvements I discussed in that post). Optimization work has continued, and I’ve now moved the override cache from JavaScript to C++, with rather dramatic latency improvement as a result.
Prior to this optimization, my C++ code would synchronously call the WebExtensions Experiment to retrieve override decisions, and the Experiment would block until the WebExtension had returned an override decision. At this point the decision would be added to the cache within the Experiment, and then the C++ code’s call to the Experiment would return. I had long suspected that this was a major latency bottleneck, for 2 reasons:
- JavaScript generally is inefficient.
- After Firefox’s built-in certificate verification completed, control had to flow from C++ to JavaScript (which adds some latency) and then from JavaScript back to C++ (which adds latency as well).
With my latest changes, the control flow changes a lot:
- The synchronous API for the C++ code to get positive override decisions from the Experiment is removed.
- The override decision cache in the Experiment is removed.
- An override decision cache is added to the C++ code.
- An API is added to the C++ code for the Experiment to notify when an override decision has just been received from the WebExtension. This API adds the decision to the C++ override decision cache.
- The C++ code that gets a positive override now simply blocks until an override decision has appeared in the cache; it doesn’t make any calls to JavaScript of any kind.
The advantages of this are:
- A lot of inefficient JavaScript code is removed from the latency-critical code paths, in favor of more efficient C++.
- Control never flows from C++ to JavaScript in order to retrieve the override decision (saves latency), and the flow from JavaScript to C++ can occur in parallel with Firefox’s built-in certificate verification (saves latency as well).
I was originally hoping to use a thread-safe data structure for the C++ override decision cache, and noticed that Mozilla’s wiki mentioned such a data structure. However, I couldn’t actually find that data structure in Mozilla’s source code. After a few hours of grepping and no luck figuring out what the wiki was referring to, I asked on Mozilla’s IRC, and was told that the wiki was out of date and that the thread-safety features of that data structure were long ago removed. So, the cache is only accessible from the main thread, and cross-thread C++ calls will still be needed to access it from outside the main thread. This isn’t really a disaster; cross-thread C++ calls aren’t massively bad.
Since I wrote up some really nice scripts for measuring latency for Phase 4, I reused them for Phase 5 to see how things have improved.
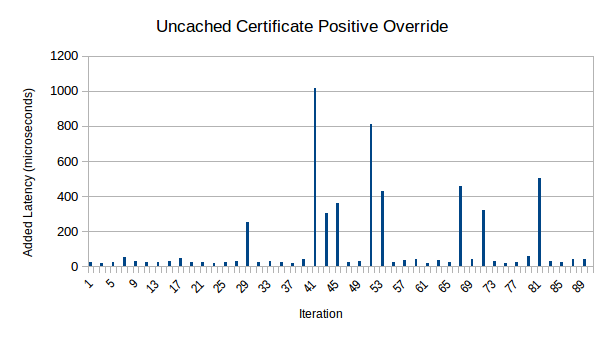
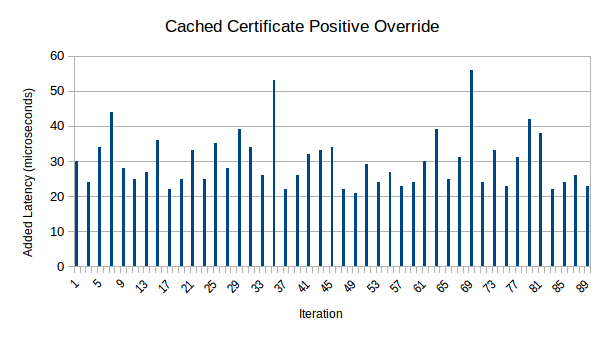
This is a quite drastic speedup. The gradual speedup over time has vanished, which suggests that I was right about it being attributable to the JavaScript JIT warming up. (However, it should be noted that this time I did a single batch of 45 certificate verifications, so this may be an artifact of that change too.) More importantly, based on the fact that uncached and cached overrides are indistinguishable in the vast majority of cases, it can be inferred that the Experiment’s decision usually enters the C++ code’s decision cache before Firefox’s built-in certificate verification even finishes. (The occasional spikes in uncached latency seem to correspond to cases where that’s false.)
The raw data is available in OpenDocument spreadsheet format or in HTML format as before. The median uncached latency for positive overrides has decreased from 375 microseconds in Phase 4 to 29 microseconds in Phase 5.
It should be noted that negative overrides haven’t yet been converted to use the C++ override decision cache. I expect them to be slightly slower than these figures, because negative overrides will have 1 extra cross-thread C++ call.
The same disclaimer as before applies: this data is not intended to be scientifically reproducible; there are likely to be differences between setups that could impact the latency significantly, and I made no effort to control for or document such differences. That said, it’s likely to be a useful indicator of how well we’re doing.
At this point, I am fully satisfied with the performance that I’m getting in these tests of positive overrides. Converting negative overrides to work similarly is expected to be easy. Of course, performance will probably be noticeably worse once the WebExtension is calling ncdns, so there’s a good chance that after ncdns is integrated with the WebExtension, I’ll be coming back to optimization.
For the short-term though, I’ll be focusing on integrating the WebExtension with ncdns.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 4 (Fun with Threads)
In Phase 2 of Namecoin TLS for Firefox, I mentioned that negative certificate verification overrides were expected to be near-identical in code structure to the positive overrides that I had implemented. However, as is par for the course, Murphy’s Law decided to rear its head (but Murphy has been defeated for now).
The specific issue I encountered is that while positive overrides are called from the main thread of Firefox, negative overrides are called from a thread dedicated to certificate verification. WebExtensions Experiments always run on the main thread. This means that the naive way of accessing an Experiment from the C++ function that would handle negative overrides causes Firefox to crash when it detects that the Experiment is being called from the wrong thread.
Luckily, I had recently gained some experience doing synchronous cross-thread calls (it’s how the Experiment calls the WebExtension), and converting that approach from JavaScript to C++ wasn’t incredibly difficult. (The only irritating part was that the Mozilla wiki’s C++ sample code for this hasn’t been updated for years, and Mozilla’s API has made a change since then that makes the sample code fail to compile. It wasn’t too hard to figure out what was broken, though.)
After doing this, I was able to get my WebExtensions Experiment to trigger negative certificate verification overrides.
Meanwhile, I talked with David Keeler from Mozilla some more about performance, and it became clear that some additional latency optimizations beyond Phase 3 were going to be highly desirable. So, I started optimizing.
The biggest bottleneck in my codebase was that basically everything was synchronous. That means that Firefox verifies the certificate according to its normal rules, and only then passes the certificate to my WebExtensions Experiment and has to wait for the Experiment to reply before Firefox can proceed. Similarly, the WebExtensions Experiment has to wait for the WebExtension to reply before the Experiment can reply to Firefox. This means 2 layers of cross-thread synchronous calls, one of which is entirely in JavaScript (and is therefore less efficient).
The natural solution is to try to make things asynchronous. I decided to start with making the Experiment’s communication with the WebExtension asynchronous. This works by adding a new non-blocking function to the Experiment (called from C++), which simply notifies it that a new certificate has been seen. This is called immediately after Firefox passes the certificate to its internal certificate verifier (and before Firefox’s verification happens), which allows the Experiment and the WebExtension to work in parallel to Firefox’s certificate verifier. When the WebExtension concludes whether an override is warranted, it notifies the Experiment, which stores the result in a cache (right now this cache is a memory leak; periodically clearing old entries in the cache is on the to-do list).
Once Firefox has finished verifying the certificate, it asks the Experiment for the override decision, but now the Experiment is likely to already have the required data (or at least be a lot closer to having it). The C++ to Experiment cross-thread call is still synchronous (for now), but the impact on overall latency is greatly reduced.
Unfortunately, at this point Murphy decided he wanted a rematch. My code was consistently crashing Firefox sometime between the C++ code issuing a call to the Experiment and the Experiment receiving the call. I guessed that this was a thread safety issue (Mozilla doesn’t guarantee that the socket info or certificate objects are thread-safe). And indeed, once I modified my C++ code to duplicate the relevant data rather than passing a pointer to a thread, this was fixed. Murphy didn’t go away without a fight though – it looks like Mozilla’s pointer objects also aren’t thread-safe, so I needed to use a regular C++ pointer instead of Mozilla’s smart pointers. (For now, that means that my code has a small memory leak. Obviously that will be fixed later.)
After doing all of the above, I decided to check performance. On both my Qubes installation and my bare-metal Fedora live system, the latency from positive overrides is now greatly reduced. Below are graphs of the latency added by positive overrides on my bare-metal Fedora live system:
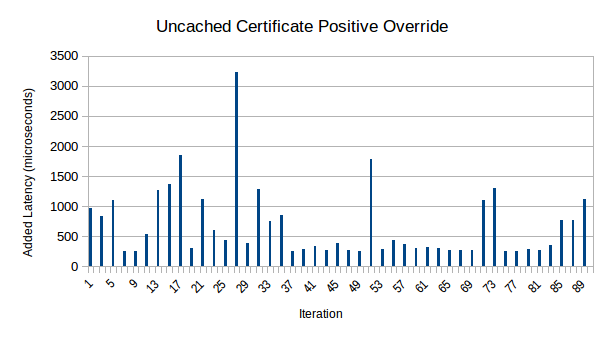
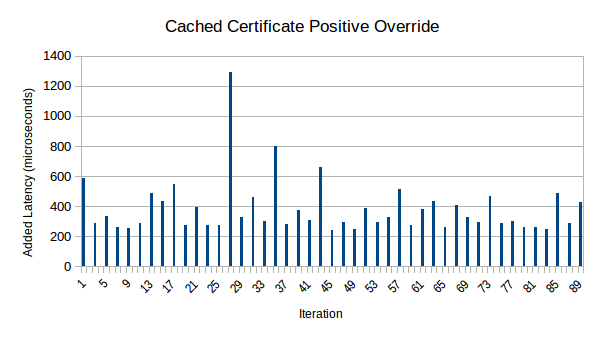
The graphs appear to show a noticeable speedup over time. Part of this is likely to be attributable to the JavaScript JIT warming up. Another part of it may be an artifact of the script I used to make Firefox verify the certificates: I first did 3 batches of 5 certs, then a batch of 10 certs, then a batch of 20 certs, for a total of 45 certificate verifications. The graphs also show that certificates that were previously cached tended to verify faster; this is because the cache is located in the Experiment rather than the WebExtension, which eliminates a cross-thread call.
You can also take a look at the raw data used to generate these graphs in OpenDocument spreadsheet format or in HTML format. This also includes percentile analysis, as well as data roughly corresponding to Mozilla’s telemetry on how long certificate verification takes right now. Although measurements on my Fedora system and from Mozilla telemetry aren’t directly comparable, it is noteworthy that the median overhead introduced by my changes is about 9% of the median certificate verification time measured by Mozilla telemetry.
It should be noted that this data is not intended to be scientifically reproducible; there are likely to be differences between setups that could impact the latency significantly, and I made no effort to control for or document such differences. That said, it’s likely to be a useful indicator of how well we’re doing. My opinion is that this is much, much closer to a performance impact that Mozilla would plausibly be willing to merge, compared to the performance before this optimization. However, additional work is still warranted. (And, of course, it’s Mozilla’s opinion, not mine, that matters here!)
There are 2 additional major optimizations that I intend to do (which aren’t yet started):
- Make the C++ to Experiment calls asynchronous. This way, the C++ code doesn’t need to issue a synchronous cross-thread call to retrieve the override data from the Experiment.
- Add an extra asynchronous call that lets Firefox notify the Experiment and the WebExtension as soon as it knows that a TLS handshake is likely to occur soon for a given domain name. In Namecoin’s case, this gives the WebExtension a chance to ask ncdns for the correct certificate before Firefox even begins the TLS handshake. That way, by the time the observed certificate gets passed to the WebExtension, it will be likely to already know how to verify it.
At this point I’m not 100% certain whether I’ll choose to do more optimization next, or if I’ll focus on hooking the WebExtension into ncdns.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 3 (Latency Debugging)
I recently mentioned performance issues that I observed with the Firefox TLS WebExtensions Experiment. I’m happy to report that those performance issues appear to have been a false alarm, due to 2 main reasons:
- I initially observed the performance issues in a Fedora VM inside Qubes. I decided on a hunch to try the same code on a Fedora live ISO running on bare metal, and the worst-case latency decreased from ~20 ms to ~6 ms. The spread also decreased a lot. I can think of lots of reasons why Qubes might have caused performance issues, e.g. the use of CPU paravirtualization, the I/O overhead associated with Xen, the limit on logical CPU cores inside the VM, the use of memory ballooning, competition from other VM’s for memory and CPU, and probably lots of other reasons. In any event, my opinion is that the fault here lies in Qubes, not my code.
- The Firefox JavaScript JIT seems to improve performance of the WebExtensions Experiment and of the WebExtension each time it runs. After running the same code (on bare-metal Fedora) against 6 different certificates, the latency decreased from ~6 ms to ~1 ms, and it was still monotonically decreasing at the 6th cert. Testing this code with many repeats is tricky, because it caches validation results per host+certificate pair, and I don’t have a large supply of invalid certificates to test with.
The happy side effect of this debugging is that my current code is now quite a lot closer to Mozilla’s standard usage patterns, since I spent a lot of time trying to figure out whether something that I was deviating from Mozilla on was responsible for the latency. Huge thanks to Andrew Swan from Mozilla for providing lots of useful tips in this area.
I believe that there are still several optimizations that could be made to this code, but for now I’m reasonably satisfied with the performance. (Whether Mozilla will want further optimization is unclear; I’ll ask them later.) My next step will be to set up negative overrides in the WebExtensions Experiment and the WebExtension. After that, I’ll be looking into actually making the WebExtension ask Namecoin for the cert data (instead of returning dummy data). Then comes code cleanup, code optimizations, and a patch submission to Mozilla.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 2 (Overrides in a WebExtension)
As I mentioned earlier, I’ve been hacking on a fork of Firefox that exposes an API for positive and negative certificate verification overrides. When I last posted, I had gotten this working from the C++ end (assuming that a highly hacky and unclean piece of code counts as “working”). I’ve now created a WebExtensions Experiment that exposes the positive override portion of this API to WebExtensions. (Negative overrides are likely to be basically identical in code structure, I just haven’t gotten to it yet.)
But wait, what’s a WebExtensions Experiment? As you may know, Mozilla deprecated the extension model that’s been used since Firefox was created, in favor of a new model called WebExtensions, which is more cleanly segregated from the internals of Firefox. This has some advantages: it means that WebExtensions can have a permission model rather than being fully trusted with the Firefox internals, and it also means that Firefox internals can change without requiring WebExtensions to adapt. However, it also means that WebExtensions are significantly more limited in what they can do compared to old-style Firefox extensions. WebExtensions Experiments are a bridge between the Firefox internals and WebExtensions. WebExtensions Experiments are old-style Firefox extensions that happen to expose a WebExtensions API. WebExtensions Experiments have all the low-level access that old-style Firefox extensions had; among other things, this means I can access my C++ API from a WebExtensions Experiment written in JavaScript, and expose an API to WebExtensions that allows them to indirectly access my C++ API.
Creating the WebExtensions Experiment was relatively straightforward, given my prior experience with nczilla (remember, a WebExtensions Experiment is mostly just a standard old-style Firefox extension, like nczilla was). I also created a proof-of-concept WebExtension that uses this API to make “Untrusted” errors be ignored. While I was doing this, I also kept track of performance. And therein lies the current problem. When the Experiment simply returns an override without asking the WebExtension, the added overhead is generally 2 ms in the worst case (and often it’s much less than 1 ms). Unfortunately, Experiments and WebExtensions run in separate threads, and the thread synchronization required to get them to communicate increases the overhead by an order of magnitude: the worst-case overhead is around 20 ms (and it’s very rarely less than 6 ms).
My assumption was that there was no way Mozilla would be merging this with that kind of performance issue; this assumption was confirmed by David Keeler from Mozilla.
On the bright side, it looks like there are several options for communicating between threads that should have lower latency (something like 1-2 ms overhead, assuming that documentation is accurate). So I’ll be investigating those in the next week or two.
As an interesting side note, Mozilla informs me that the current method I’m using to communicate between threads shouldn’t be working at all. I’m not sure why it’s working when they say it shouldn’t, but in any event it’s probably a Very Bad Thing ™ to be using patterns that Mozilla doesn’t expect to work at all, even without the latency issue (since such patterns might break in the future, which I certainly don’t want).
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Registering Names with the Raw Transaction API
The refactorings to the raw transaction API that I mentioned earlier have been merged to Namecoin Core’s master branch. I’ve been doing some experiments with it, and I used it to successfully register a name on a regtest network with only one unlock of my wallet (which covered both the name_new and name_firstupdate operations).
I also coded support for Coin Control and Fee Control for name registrations, although this code is not yet tested (meaning that if Murphy has anything to say about it, it will need some fixes).
So far the code here is a Python script, so it still needs to be integrated into Namecoin-Qt. Brandon expects this to be relatively straightforward once I hand off my Python code to him. Major thanks to Daniel for getting the API refactorings into Namecoin Core, and thanks to Brandon for useful discussions on how best to structure the code so that it can be integrated into Namecoin-Qt smoothly.
Hopefully I’ll have more news on this subject in the next couple weeks.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
ncdns v0.0.5 Released
We’ve released ncdns v0.0.5. List of changes:
- Windows installer:
- Bundle BitcoinJ/libdohj SPV name lookup client as an alternative to Namecoin Core.
- TLS: Support Google Chrome Canary. (Bug reported by samurai321.)
- TLS: Fix bug in Chromium, Google Chrome, and Google Chrome Canary profile detection. (Bug reported by samurai321.)
- User is now prompted to uninstall before reinstalling.
- Add additional debug output. (Bug reported by samurai321.)
- Detect when Namecoin Core or Dnssec-Trigger failed to install.
- All OS’s:
- Various code cleanups.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Namecoin TLS for Firefox: Phase 1 (Overrides in C++)
Making TLS work for Namecoin websites in Firefox has been an interesting challenge. On the positive side, Mozilla has historically exposed a number of API’s that would be useful for this purpose, and we’ve actually produced a couple of Firefox extensions that used them: the well-known Convergence for Namecoin codebase (based on Convergence by Moxie Marlinspike and customized for Namecoin by me), and the much-lesser-known nczilla (written by Hugo Landau and me, with some code borrowed from Selenium). This was a pretty big advantage over Chromium, whose developers have consistently refused to support our use cases (which forced us to use the dehydrated certificate witchcraft). On the negative side, Mozilla has a habit of removing useful API’s approximately as fast as we notice new ones. (Convergence’s required API’s were removed by Mozilla about a year or two after we started using Convergence, and nczilla’s required API’s were removed before nczilla even had a proper release, which is why nearly no one has heard of nczilla.) On the positive side, Mozilla has expressed an apparent willingness to entertain the idea of merging officially supported API’s for our use case. So, I’ve been hacking around with a fork of Firefox, hoping to come up with something that Mozilla could merge in the future. Phase 1 of that effort is now complete.
In particular, I’ve created a C++ XPCOM component (compiled into my fork of Firefox) that hooks the certificate verification functions, and can produce both positive and negative overrides (meaning, respectively, that it can make invalid certs appear valid, and make valid certs appear invalid). This XPCOM component has access to most of the data that we would want: it has access to the certificate, the hostname, and quite a lot of other data that Firefox stores in objects that the XPCOM component has access to. Unfortunately, it doesn’t yet have access to the full certificate chain (I’m still investigating how to do that), and it also doesn’t yet have access to the proxy settings (I do see how to do that, it’s just not coded yet). The full certificate chain would be useful if you want to run your own CA; the proxy settings would be useful for Tor stream isolation with headers-only Namecoin SPV clients.
Performance is likely to be impacted, since this code is not even close to optimized (nor is performance even measured). I’ll be investigating performance later. Short-term, my next step will be to delegate the override decisions to JavaScript code. (This looks straightforward, but as we all know, our friend Murphy might strike at any time.) After that I’ll be looking at making that JavaScript code delegate decisions to WebExtensions. The intention here is to support use cases besides Namecoin’s. The WebExtensions API that this would expose would presumably be useful for DNSSEC/DANE verification, perspective verification, and maybe other interesting experiments that I haven’t thought of.
Major thanks to David Keeler from Mozilla for answering some questions in IRC that I had about how the Firefox certificate verification code is structured.
Hopefully I’ll have more news on this subject in the next couple weeks.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Refactoring the Raw Transaction API
Several improvements are desirable for how Namecoin Core creates name transactions:
- Register names without having to unlock the wallet twice, 12 blocks apart.
- Coin Control (a method of improving anonymity).
- Specifying a fee based on when you need the transaction to be confirmed.
- Pure name transactions (a method of improving scalability of Namecoin by decreasing transaction size).
All of these improvements, though they seem quite different in nature, have one important thing in common: they need to use the raw transaction API in ways that Namecoin Core doesn’t make easy.
What’s the raw transaction API?
Simply put, the raw transaction API is a Bitcoin Core feature that allows the user to create custom transactions at a much lower level than what a typical user would want. The raw transaction API gives you a lot of power and flexibility, but it’s also more cumbersome and, if used incorrectly, you can accidentally lose lots of money.
Why do those features need the raw transaction API?
The raw transaction API is useful for a few reasons. First, it lets you create and sign transactions independently from broadcasting them. That means you can create and sign a name_firstupdate transaction before its preceding name_new transaction has been broadcast. Second, it gives you direct control over the inputs, outputs, and fees for the transaction, whereas the standard name commands instead pick defaults for you that you might not like and can’t change.
What’s wrong with Namecoin Core’s raw transaction API?
It’s not raw enough! First off, the only name transactions it can create are name_update; it can’t create name_new or name_firstupdate transactions. That rules out handling name registrations, and consequently means that anonymously registering names or controlling the fee for name registrations is a no-go. Secondly, it can’t create name_update outputs with a higher monetary value than the default 0.01 NMC. That rules out pure name transactions.
How are we fixing this?
We’re making an API change. Instead of trying to stuff name operation data into createrawtransaction, where it doesn’t belong and where it’s extremely difficult to provide the needed flexibility, we’re removing name support from createrawtransaction and moving it to a new RPC call, namerawtransaction. The new workflow replaces the previous createrawtransaction with two steps:
- Use
createrawtransactionjust like you would with Bitcoin, and specify a currency output of 0.01 NMC for where you want the name output to be. - Use
namerawtransactionto prepend a name operation to the scriptPubKey of the aforementioned currency output. This has the effect of converting that currency output into a name output.
What will be the impact?
Users of the raw transaction API will need to update their code. If you’re using the raw transaction API to create currency transactions, then this will actually allow you to delete your Namecoin-specific customizations, since it will be just like Bitcoin again. If you’re using the raw transaction API to create name transactions (this includes people who are doing atomic name trading), you’ll need to refactor your createrawtransaction-using code so that it also calls namerawtransaction. If you’re a hacker who enjoys experimenting, this new workflow will probably be much more to your liking, as it will allow you to do stuff that you couldn’t easily do before. And if you’re just an average user of Namecoin-Qt, you’ll probably like the new features that this enables, such as easier registration of names, better privacy, and lower fees.
Who’s involved in this work?
- Jeremy Rand wrote a rough spec for the new API.
- Daniel Kraft is implementing the changes to the API.
- Jeremy Rand plans to utilize the new API in proof-of-concept scripts for several use cases (including the above 4 use cases).
- Brandon Roberts plans to convert Jeremy’s proof-of-concept scripts into GUI features in Namecoin-Qt.
This work was funded in part by NLnet Foundation’s Internet Hardening Fund.
What might come later?
Maybe Namecoin-Qt support for atomic name trading? :)
BitcoinJ support merged into ncdns-nsis
The ncdns-nsis project, which provides a zero-configuration Windows installer
for Namecoin domain name resolution functionality, has merged SPV support,
implemented via BitcoinJ. This enables Windows machines to resolve .bit
domain names without having to download the full Namecoin chain.
Merging this functionality means that Namecoin domain names can be resolved on Windows client machines with only a minimal chain synchronization and storage burden, in exchange for a limited reduction in the security level provided.
Installer binaries will be published in due course as remaining ncdns-nsis issues are concluded.
To use the BitcoinJ client, run the ncdns-nsis installer and select the SPV
option when asked whether to install a Namecoin node. Run BitcoinJ after
installation and wait for synchronization to complete; .bit name resolution
is then available.
Video, Slides, and Paper from Namecoin at GCER 2017
As was announced, I represented Namecoin at the 2017 Global Conference on Educational Robotics. Although GCER doesn’t produce official recordings of their talks, I was able to obtain an amateur recording of my talk from an audience member. I’ve also posted my slides, as well as my paper from the conference proceedings.
It should be noted that, as this is an amateur recording, the audio quality is not spectacular. It should also be noted that the audience is rather different from the audiences for whom I usually give Namecoin talks; as a result, the focus of the content is also rather different from my usual Namecoin talks.
The WebM amateur video recording of my talk is here (hosted by Namecoin.org).
Huge thanks to the staff and volunteers from KISS Institute for Practical Robotics, who organized GCER. Especially big thanks to Roger Clement and Steve Goodgame for giving me excellent feedback on the general outline of my paper and talk. This was an excellent event, and I look forward to the next time I’m able to attend.
ncdns v0.0.4 Released
We’ve released ncdns v0.0.4. This release incorporates a bugfix in the madns dependency, which fixes a DNSSEC signing bug. The ncdns Windows installer in this release also updated the Dnssec-Trigger dependency.
As usual, you can download it at the Beta Downloads page.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
TLS Support for Chromium on Windows Released
After quite a bit of code cleanup, we’ve released a new beta of ncdns for Windows, which includes Namecoin-based TLS certificate validation for Chromium, Google Chrome, and Opera on Windows. This includes both the CryptoAPI certificate injection and NUMS HPKP injection that were discussed previously. You can download it on the Beta Downloads page. We’ve also posted binaries of ncdns (without install scripts or TLS support) for a number of other operating systems; they’re also linked on the Beta Downloads page.
Credit for this release goes to:
- Jeremy Rand: Cert injection Go implementation; NUMS HPKP injection concept and Go implementation; review of Hugo’s code.
- Hugo Landau: Cert injection NSIS implementation; NUMS HPKP injection NSIS implementation; review of Jeremy’s code.
- Ryan Castellucci: Dehydrated certificates concept+algorithm; NUMS hash algorithm and Python implementation.
This work was funded by NLnet Foundation’s Internet Hardening Fund.
Meanwhile, Namecoin TLS development focus has started to shift toward Firefox TLS support.
QCon London 2017 Video: Case Study: Alternate Blockchains
InfoQ has posted the recording of my talk, Case Study: Alternate Blockchains at QCon London 2017.
The videos on the InfoQ website do not appear to work when Javascript is disabled. Security-conscious users who prefer not to enable Javascript can view the video via youtube-dl (Debian package) (recommendation by Whonix).
LibreTorNS Merged to Upstream TorNS
Generally I’m of the opinion that it’s better to get patches to other people’s projects merged upstream whenever feasible; accordingly I submitted the LibreTorNS patches upstream. Happily, meejah has merged the LibreTorNS patches to upstream TorNS. That means LibreTorNS is now obsolete, and you should use meejah’s upstream TorNS for testing dns-prop279 going forward.
Huge thanks to meejah for accepting the patch! Also thanks to meejah for the code review – there was a bug hiding in my initial submitted patch, which is one of the reasons I always prefer getting things reviewed by upstream.
Namecoin’s Jeremy Rand will be a speaker at GCER 2017
I will be speaking at the 2017 Global Conference on Educational Robotics (July 8-12, 2017). For those of you unfamiliar with GCER, the audience is mostly a mix of middle school students, high school students, college students, and educators, most of whom are participating in the robotics competitions hosted at GCER (primarily Botball). I competed in Botball (and the other 2 GCER competitions: KIPR Open and KIPR Aerial) between 2003 and 2015, and that experience (particularly the hacking aspect, which is actively encouraged in all three competitions) was a major factor in why I’m a Namecoin developer. My talk is an outreach effort, which I hope will result in increased interest in the Botball scene in the areas of privacy, security, and human rights. My talk (scheduled for July 10) is entitled “Making HTTPS and Anonymity Networks Slightly More Secure (Or: How I’m Using My Botball Skill Set in the Privacy/Security Field)”.
Huge thanks to KISS Institute for Practical Robotics (which organizes GCER) for suggesting that I give this talk. Looking forward to it!
QCon London 2017 Video: Practical Cryptography & Blockchain Panel
InfoQ has posted the recording of the Practical Cryptography & Blockchain Panel at QCon London 2017. The panelists (from left to right) were Elaine Ou, me (Jeremy Rand), David Vorick, Paul Sztorc, and Peter Todd. Riccardo Spagni (on the right) moderated the panel.
The videos on the InfoQ website do not appear to work when Javascript is disabled. Security-conscious users who prefer not to enable Javascript can view the video via youtube-dl (Debian package) (recommendation by Whonix).
Namecoin Resolution for Tor Released
The aforementioned licensing issues with TorNS have been dealt with, and I’ve released the DNS provider for Tor’s Prop279 Pluggable Naming API. This allows Namecoin resolution in Tor.
One issue I encountered is that TorNS currently implements a rather unfortunate restriction that input and output domain names must be in the .onion TLD. I’ve created a fork of TorNS (which I call LibreTorNS) which removes this restriction. LibreTorNS is currently required for Namecoin usage.
The code is available from the Beta Downloads page. Please let me know what works and what doesn’t. And remember, using Namecoin naming with Tor will make you heavily stand out, so don’t use this in any scenario where you need anonymity. (Also please refer to the extensive additional scary warnings in the readme if you’re under the mistaken impression that using this in production is a good idea.)
This development was funded by NLnet.
Namecoin Resolution for Tor (DNS Provider for Tor Prop279 Pluggable Naming API)
A while back, I released on the tor-dev mailing list a tool for using Namecoin naming with Tor. It worked, but it was clearly a proof of concept. For example, it didn’t implement most of the Namecoin domain names spec, it didn’t work with the libdohj client, and it used the Tor controller API. I’ve now coded a new tool that fixes these issues.
Fixing the spec compliance and libdohj compatibility was implemented by using ncdns as a backend instead of directly talking to Namecoin Core. Interestingly, I decided not to do anything Namecoin-specific with this tool. It simply uses the DNS protocol to talk to ncdns, or any other DNS server you provide. (So yes, that means that you could, in theory, use the DNS instead of Namecoin, without modifying this tool at all.)
In order to work with the DNS protocol, some changes were made to how .onion domains are stored in Namecoin. The existing convention is to use the tor field of a domain, which has no DNS mapping. Instead, I’m using the txt field of the _tor subdomain of a domain. This is consistent with existing practice in the DNS world.
This tool is using Tor’s Prop279 Pluggable Naming protocol rather than the Tor controller API. Right now tor (little-t) doesn’t implement Prop279. To experiment with Prop279, TorNS is a useful way of simulating Prop279 support using the control port as a backend. Unfortunately, TorNS’s license is unclear at the moment. I’m in the process of checking with meejah (author of TorNS) to see if TorNS can be released under a free software license. Until that minor bit of legalese is taken care of, the release of Namecoin resolution for Tor is on hold.
This development was funded by NLnet.
Automated Nothing-Up-My-Sleeve HPKP Insertion for Chromium
As I mentioned in my previous post, we protect from compromised CA’s by using a nothing-up-my-sleeve (NUMS) HPKP pin in Chromium. Previously, it was necessary for the user to add this pin themselves in the Chromium UI. This was really sketchy from both a security and UX point of view. I have now submitted a PR to ncdns that will automatically add the necessary pin.
This is implemented as a standalone program that is intended to be run at install. It works by parsing Chromium’s TransportSecurity storage file (which is just JSON), adding an entry for bit that contains the NUMS key pin, and then saving the result as JSON back to TransportSecurity.
I expect this to work for most browsers based on Chromium (e.g. Chrome and Opera), on most OS’s (e.g. GNU/Linux, Windows, and macOS), but so far I’ve only tested with Chrome on Windows. I don’t expect it to work with Electron-based applications such as Riot and Brave; Electron doesn’t seem to follow the standard Chromium conventions on HPKP. I haven’t yet examined Electron to see if there’s a way we can get it to work.
This isn’t yet integrated with the NSIS installer; I’ll be asking Hugo to take a look at doing the integration there.
Progress on Electrum-NMC
Work on the electrum port for Namecoin has been moving along nicely. It was decided that we will use the electrum-client from spesmilo, along with the electrumX server. ElectrumX was chosen due to the original electrum-server being discontinued a few months ago. So far the electrum client has been ported over for compatability with electrumX. This includes the re-branding, blockchain parameters and other electrum related settings for blockchain verification
On the roadmap now are:
- Extend electrumX NMC Support to allow for full veritification of AuxPow
- Modify new electrum client to verify the new AuxPow
- Add Name handling support to electrum
These repo’s are for testing purposes only. Do not use these unless your willing to risk losing funds.
How we’re doing TLS for Chromium
Back in the “bad old days” of Namecoin TLS (circa 2013), we used the Convergence codebase by Moxie Marlinspike to integrate with TLS implementations. However, we weren’t happy with that approach, and have abandoned it in favor of a new approach: dehydrated certificates.
What’s wrong with Convergence? Convergence uses a TLS intercepting proxy to replace the TLS implementation used by web browsers. Unfortunately, TLS is a really difficult and complex protocol to implement, and the nature of intercepting proxies means that if the proxy makes a mistake, the web browser won’t protect you. It’s fairly commonplace these days to read news about a widely deployed TLS intercepting proxy that broke things horribly. Lenovo’s SuperFish is a well-known example of a TLS intercepting proxy that made its users less safe.
Convergence was in a somewhat special situation, though: it reused a lot of code that was distributed with Firefox (via the js-ctypes API), which reduced the risk that it would do something horribly dangerous with TLS. It was also originally written by Moxie Marlinspike (well-known for Signal), which additionally reduced the risk of problems. Unfortunately, Mozilla stopped shipping the relevant code with Firefox, Moxie stopped maintaining Convergence, and Mozilla decided to deprecate additional functionality that was used by Convergence. This made it clear that the Convergence codebase wasn’t going to be viable, and that if we wanted to use an intercepting proxy, we’d be using a codebase that was substantially less reliable than Convergence.
So, we went back to the drawing board, and came up with a new solution.
As a first iteration, TLS implementations have a root CA trust store, and injecting a self-signed end-entity x509 certificate into the root CA trust store will allow that certificate to be trusted for use by a website. (For an explanation of how this can be done with Windows CryptoAPI, see my previous post, Reverse-Engineering CryptoAPI’s Certificate Registry Blobs). We can do this right before the TLS connection is opened by hooking the DNS request for the .bit domain (this is easy since we control the ncdns codebase that processes the DNS request).
However, there are three major issues with this approach:
- An x509 certificate is very large, and storing this in the blockchain would be too expensive. Using a fingerprint would be much smaller, but we can’t recover the full certificate from just the fingerprint.
- x509 certificates might be valid for a different purpose than advertised. For example, if we injected a certificate that has the CA bit enabled, the owner of that certificate would be able to impersonate arbitrary websites if they can get you to first visit their malicious
.bitdomain. x509 is a complex specification, and we don’t want to try to detect every possible type of mischief that can be done with them. - Injecting a certficate doesn’t prevent a malicious CA that is trusted for DNS names from issuing fraudulent certificates for
.bitdomain names.
Problems 1 and 2 can be solved at the same time. First, we use ECDSA certificates instead of the typical RSA. ECDSA is supported by all recent TLS implementations, but RSA is largely dominant because of inertia and the prevalence of outdated software. By excluding the old software that relies on RSA, we get much smaller keys and signatures. (Old software isn’t usable with this scheme anyway, because of our solution to Problem 3.)
Next, instead of having domain owners put the entire ECDSA x509 certificate in the blockchain, the domain owner extracts only 4 components of the certificate: the public key, the start and end timestamps for the valdity period, and the signature. As long as the rest of the certificate conforms to a fixed template, those 4 components (which we call a dehydrated certificate) can be combined with a domain name and the template, and rehydrated into a fully valid x509 certificate that can be injected into the trust store. This technique was invented by Namecoin’s Lead Security Engineer, Ryan Castellucci.
It should be noted that a dehydrated certificate can’t do any mischief such as being valid for unexpected uses; all of the potentially dangerous fields are provided by the template, which is part of ncdns. The dehydrated data is also quite small: circa 252 bytes (we can probably shrink it further in the future). Implementing this in ncdns was a little bit tricky, because the Go standard library’s x509 functions that are needed to perform the signature splicing are private. I ended up forking the Go x509 package, and adding a public function that exposes the needed functionality. (Before you freak out about me forking the x509 package, my package consists of a single file that contains the additional function, and a Bash script that copies the official x509 library into my fork. It’s reasonably self-contained and shouldn’t run into the issues that more invasive forks encounter regularly.)
So what about Problem 3? Well, for this, I abuse take advantage of an interesting quirk in browser implementations of HPKP (HTTPS Public Key Pinning). Browsers only enforce key pins against certificates for built-in certificate authorities; user-specified certificate authorities are exempt from HPKP. This behavior is presumably to make it easier for users to intentionally intercept their own traffic (or for corporations to intercept traffic in their network, which is a less ethical version of a technologically identical concept). As such, I believe that this behavior will not go away anytime soon, and is safe to rely on. The user places a key pin at the bit domain, with subdomains enabled, for a “nothing up my sleeve” public key hash. As a result, no public CA can sign certificates for any domain ending in .bit, but user-specified CA’s can. Windows CryptoAPI treats user-specified end-entity certificates as user-specified CA’s for this purpose. As such, rehydrated certificates that ncdns generates will be considered valid, but nothing else will. (Unless you installed another user-specified CA on your machine that is valid for .bit. But if you did that, then either you want to intercept .bit, in which case it’s fine, or you did it against your will, in which case you are already screwed.)
I’ve implemented dehydrated certificate injection as part of ncdns for 2 major TLS implementations: CryptoAPI (used by Chromium on Windows) and NSS (used by Chromium on GNU/Linux). These are currently undergoing review as pull requests for ncdns. (The macOS trust store should also be feasible, but I haven’t done anything with it yet.) Right now, those pull requests prompt the user during ncdns installation with instructions for adding an HPKP pin to Chromium. (If you’ve tried out the ncdns for Windows installer on a machine that has Chromium, you might have noticed this dialog.) This isn’t great UX, and I’ve found a way to do this automatically without user involvement, which I will be implementing into the ncdns installer soon.
Unfortunately, abusing HPKP in this way isn’t an option in Firefox, because Mozilla’s implementation of HPKP doesn’t permit key pins to be placed on TLD’s. (As far as I can tell, the specifications seem to be ambiguous on this point.) Mozilla does offer an XPCOM API for HPKP (specifically, nsISiteSecurityService) that can inject key pins for individual .bit domains on the fly, but since XPCOM is deprecated by Mozilla, this is not a viable option as-is. On the bright side, Mozilla seems interested in implementing the API’s we need to do this in a less hacky way, so I’ll be engaging with Mozilla on this.
As another note: NSS trust store injection is rather slow right now, because I’m currently using NSS’s certutil to do the injection, and certutil isn’t properly optimized for speed. Sadly, there doesn’t seem to be an easy way of bypassing certutil for NSS like there is for CryptoAPI (NSS’s trust store is a sqlite database with a significantly more complex structure than CryptoAPI, and the CryptoAPI trick of leaving out all the data besides the certificate doesn’t work for NSS). I will probably be filing at least one bug report with NSS about certutil’s performance issues. If progress on fixing those issues appears to be unlikely, I think it may be feasible to do some witchcraft to speed it up a lot, but I’m hoping that things won’t come to that.
I’m hoping to get at least the CryptoAPI PR merged to official ncdns very soon, at which point I’ll ask Hugo to release a new ncdns for Windows installer so everyone can have fun testing.
ncdns for Windows Beta Installer Now Available
In order to facilitate the easy resolution of .bit domains, an installer for
ncdns for Windows has been under development. This installer automatically
installs and configures Namecoin Core, Unbound and ncdns.
An experimental binary release for this installer is now available. Interested Namecoin users are encouraged to test the installer and report any issues they encounter.
This release does not yet integrate the TLS integration support for ncdns under development by Jeremy Rand. This will be incorporated in a future release.
The development of this installer was funded by NLnet.
Reverse-Engineering CryptoAPI’s Certificate Registry Blobs
Every so often, I’m doing Namecoin-related development research (in this case, making TLS work properly) and I run across some really interesting information that no one else seems to have documented. While this post isn’t solely Namecoin-related (it’s probably useful to anyone curious about tinkering with TLS), I hope you find it interesting regardless.
A note on the focus here: while this research was done for the purpose of engineering specific things, I’m writing it from more of a “basic research” point of view. My dad’s career was in basic research, and I firmly believe that learning cool stuff for the sake of learning it is a worthwhile endeavor, regardless of what the practical applications are (and indeed, usually when basic research turns out to have applications, which is commonplace, the initial researchers didn’t know what those applications would be). Since I’m an engineer, there will be a bit of application-related commentary here, but don’t read this expecting it to be a summary of the next Namecoin software release’s feature set or use cases.
In Windows-based OS’s, most applications handle certificates via the CryptoAPI. CryptoAPI serves a somewhat similar role in Windows certificate verification as OpenSSL does on GNU/Linux-based systems. Notably, Mozilla-based applications like Firefox and Thunderbird don’t use CryptoAPI (nor OpenSSL); they use the Mozilla library NSS (on both Windows and GNU/Linux). However, except for Mozilla applications, and a few applications ported from GNU/Linux (e.g. Python) which use OpenSSL, just about everything on Windows uses CryptoAPI for its certificate needs. CryptoAPI is a quite old Microsoft technology; it dates back at least to Windows NT 4. (It might be even older, but I’ve never touched nor read about any of the earlier incarnations of Windows NT, so I wouldn’t know.) Like any other codebase that’s been around for over 2 decades, its design is somewhat convoluted, and my guess is that if it were being designed from scratch today, it would look very different.
CryptoAPI maintains a bunch of different stores for certificates. These stores are designated according to the certificate’s intended usage (e.g. a website cert, an intermediate CA, a root CA, a personal cert, and a bunch of other use cases that I don’t understand because I’ve never managed any kind of certificate infrastructure for an enterprise), the method by which the certificate was loaded (e.g. by a web browser cache, by group policy, and a bunch of other methods that, again, I don’t understand because I don’t do enterprise infrastructure), which users have permission to use the certs (roaming profiles have special handling), and even which applications are expected to consider them valid (Cortana, Edge, and Windows Store all have their own certificate stores, for reasons that I don’t understand in the slightest, although I do wonder whether adding an intercepting proxy to Cortana’s cert store would be useful in an attempt to wiretap Cortana and see what data Microsoft collects on its users). You can see a subset of the certificate stores’ contents via certmgr.msc, and there’s a command-line tool included with Windows called certutil which can edit or dump this data as well. Neither of these tools actually shows all of the stores, e.g. Cortana, Edge, and Windows Store are secret and invisible. Also, don’t confuse the CryptoAPI certutil with the Mozilla command-line tool also called certutil, which is similar but is for NSS stores and has an entirely different syntax.
Incidentally, CryptoAPI has some interesting behavior when it comes to root CA’s. If you add a self-signed website cert to a root CA store, that self-signed website cert becomes fully trusted (HSTS and HPKP even work, which implies that it doesn’t get reported as an override). Of course, this is usually a dangerous idea, since that self-signed website could then sign other websites’ certs – you did tell Windows to treat it as a root CA, after all. But Windows actually does respect the CA and CertUsage flags in this case: if you construct a cert that is not valid as a CA, Windows will happily let you add it to a root CA store, will accept it as a website cert, but will refuse to trust any other cert signed by that cert. Namecoin lead security engineer Ryan Castellucci told me on IRC that he’s not sure if this behavior is even defined in a spec, but in my testing, NSS seems to exhibit identical behavior (no idea about OpenSSL). Regardless of specs, Microsoft has a fanatical obsession with not changing behavior of any public-facing API that might impact backwards compatibility (to Microsoft, the original implementation is the spec), so I think it’s probably pretty safe to rely on this behavior, even when someone as thoroughly knowledgeable as Ryan has never encountered anything in the wild that does this. Of course, that’s just my assessment – I take no responsibility if this burns you. As they say on Brainiac: Science Abuse, “we do these experiments so you don’t have to – do not try this at home – no really, don’t.”
Now, unfortunately, CryptoAPI has a problem. It expects a user to have administrator privileges in order to add a cert to most of the stores. This is probably well-meaning, because you definitely don’t want some random piece of malware that abused a Javascript zero-day to be able to add a root CA, or anything like that. (Fun fact: any such malware can, however, add a root CA to Firefox, because the NSS cert stores are simply a file in your profile directory, and are therefore user-writeable. That’s even true for Firefox on many GNU/Linux systems, even though the OpenSSL store is protected.) Of course, the security benefits of requiring privileged access for this are dubious, given that malware running as the primary user can do all sorts of other mischief, such as replacing the shortcut to your browser with a patched version that MITM’s you. However, regardless of the alleged security benefit of this policy, there’s a fairly obvious problem here: this implies that if you want to run software that programatically adds root CA’s, perhaps for the use case in the previous paragraph, you need to give that software Administrator privileges. As a (minimally) sane person, running anything, much less a daemon that interacts with a bunch of untrusted network hosts (e.g. Namecoin peers), as an administrator is an absolute dealbreaker. Yes, I did code it that way as a proof of concept for the hackathon by the College Cryptocurrency Network that I got 3rd place in, but no way in hell am I going to ship software to end users that does such irresponsible things. And if you’re the kind of person who would be tempted to do that, please, for the sake of your users, exit the software development field before you get some dissident or whistleblower murdered. This stuff actually is important to those of us with ethics.
You might wonder: why the heck isn’t there a permission system for this? Coming from a culture that loves the concept (if not implementation) of things like AppArmor and SELinux, that was certainly my thought. But alas, I was unable to find any Microsoft documentation that suggested a way to delegate access to a specific cert store to some other user. (Of course, Microsoft’s documentation is a train wreck, so maybe they did address this use case and I just couldn’t find any mention of it.) However, I did learn something interesting by Googling. While OpenSSL cert stores are just a filesystem folder, and NSS cert stores are a database file (whose database backend is either BerkeleyDB or SQLite), CryptoAPI mostly uses… the Windows Registry. Remember, this is Microsoft, they dump their garbage in the registry with as little hesitation as petroleum companies dump their garbage in Latin-American rainforests. (Personal certificates that are part of roaming profiles are instead placed in a user’s profile folder, apparently ever since Windows 2000 came out. But almost everything else is in the registry.) Since the registry does have a permission system, this looks like the perfect solution.
It was relatively easy to figure out where these certificates are located in the dense, uncharted jungle that is the registry. Indeed, you can search your registry for keys titled Root and you’ll find all the root CA stores (the other types of stores are in sibling keys). Each certificate is located in its own subkey (the subkey is named based on the certificate’s SHA-1 fingerprint). Actually, let me digress for a moment. Why the hell is Microsoft using SHA-1 hashes as the names of registry keys, even in Windows 10? Yes, I know SHA-1 was not known to be weak when Microsoft designed CryptoAPI, but tying the name of something to a specific hash algorithm seems like a massively stupid idea in terms of design and safety. (And no, it’s not a good idea to drive drunk just because your crazy git uncle Linus does it every New Year’s Eve and hasn’t died yet.) Anyway, inside that subkey is a single value, called Blob, which contains binary data encoding the certificate. Not too complicated, right?
Oh, wait. We’re talking about Microsoft. Everything is complicated, usually for no discernable reason whatsoever. Also, the most complicated things usually have the least documentation. I know people who have long-ago adopted a policy of getting their Windows documentation from the ReactOS source code instead of the Microsoft website, because a small, minimally funded project that’s reverse-engineering everything writes more accurate documentation than the wildly successful company who actually engineered the system and wrote the original source code. Anyway, I looked at the contents of the binary blob in the registry, and noticed that it didn’t look right. More specifically, it wasn’t a DER-encoded x.509 structure, nor was it even PEM-encoded. Actually, there was a substring that did correspond to the DER-encoded x.509 structure, but there was a crapload of extra data too. For reference, it looked like this (in .reg format):
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\SystemCertificates\trust\Certificates\BBC2FAE0B710372FC293E092904F7E628D3D4546]
"Blob"=hex:04,00,00,00,01,00,00,00,10,00,00,00,97,30,35,47,95,5b,3b,e4,05,71,\
d4,5c,6c,cd,7e,21,0f,00,00,00,01,00,00,00,20,00,00,00,95,6e,94,6c,93,46,fd,\
c8,b5,02,66,9b,c9,1b,be,5c,19,df,97,f0,b4,8d,fa,f2,57,28,77,a1,7a,37,bc,bc,\
14,00,00,00,01,00,00,00,14,00,00,00,33,c6,3b,84,aa,7a,15,b1,23,a5,4c,7e,38,\
23,25,bc,e8,7f,cb,eb,19,00,00,00,01,00,00,00,10,00,00,00,73,1a,dd,da,db,51,\
b3,34,87,0f,15,1e,03,c0,b0,11,5c,00,00,00,01,00,00,00,04,00,00,00,00,01,00,\
00,03,00,00,00,01,00,00,00,14,00,00,00,bb,c2,fa,e0,b7,10,37,2f,c2,93,e0,92,\
90,4f,7e,62,8d,3d,45,46,20,00,00,00,01,00,00,00,d3,01,00,00,30,82,01,cf,30,\
82,01,76,a0,03,02,01,02,02,14,00,f5,9d,9e,8e,09,5d,3f,54,a9,02,2a,89,09,62,\
41,df,f1,fa,e1,30,0a,06,08,2a,86,48,ce,3d,04,03,02,30,3e,31,19,30,17,06,03,\
55,04,03,13,10,74,65,73,74,2e,76,65,63,6c,61,62,73,2e,62,69,74,31,21,30,1f,\
06,03,55,04,05,13,18,4e,61,6d,65,63,6f,69,6e,20,54,4c,53,20,43,65,72,74,69,\
66,69,63,61,74,65,30,1e,17,0d,31,37,30,31,30,31,30,30,30,30,30,30,5a,17,0d,\
31,38,30,31,30,31,30,30,30,30,30,30,5a,30,3e,31,19,30,17,06,03,55,04,03,13,\
10,74,65,73,74,2e,76,65,63,6c,61,62,73,2e,62,69,74,31,21,30,1f,06,03,55,04,\
05,13,18,4e,61,6d,65,63,6f,69,6e,20,54,4c,53,20,43,65,72,74,69,66,69,63,61,\
74,65,30,59,30,13,06,07,2a,86,48,ce,3d,02,01,06,08,2a,86,48,ce,3d,03,01,07,\
03,42,00,04,fe,1c,b5,b7,88,c1,d7,8a,e8,9f,1e,a7,d6,6f,15,42,1d,36,8d,b9,51,\
7e,ed,9c,57,7f,cb,73,2a,26,7d,59,63,ca,95,10,30,68,e6,bb,15,8d,6c,f2,34,6b,\
77,05,ea,68,8d,3a,28,d2,0a,eb,6a,4d,97,5b,ed,32,ef,8a,a3,52,30,50,30,0e,06,\
03,55,1d,0f,01,01,ff,04,04,03,02,07,80,30,13,06,03,55,1d,25,04,0c,30,0a,06,\
08,2b,06,01,05,05,07,03,01,30,0c,06,03,55,1d,13,01,01,ff,04,02,30,00,30,1b,\
06,03,55,1d,11,04,14,30,12,82,10,74,65,73,74,2e,76,65,63,6c,61,62,73,2e,62,\
69,74,30,0a,06,08,2a,86,48,ce,3d,04,03,02,03,47,00,30,44,02,20,65,d7,93,a8,\
18,c7,de,6f,42,89,27,47,08,90,e1,ed,bb,23,e0,d7,51,69,04,f0,be,9d,98,bc,00,\
88,69,dc,02,20,5b,b4,45,f5,9e,76,48,37,1d,58,1b,34,f9,17,1f,12,c6,98,cb,c0,\
d0,d3,50,19,2a,db,63,69,6b,31,cb,20
Just to see what would happen, I took a raw DER-encoded x.509 certificate and shoved it into the registry to see if CryptoAPI would accept it, but of course it didn’t, so I needed to figure out what that extra data was. Now, as a middle school student, as a high school student, and as an undergraduate student (though sadly not as a graduate student), I did a lot of reverse-engineering of various binary formats (making a Mega Drive Zero Wing ROM include custom dialogue between “Cracker” and “Admin” about how “All your 802.11b are belong to us” and that “You are on the way to DDoS microsoft.com” was a few days of work in 7th grade). So I was quite ready to go that route. However, I learned long ago that it’s always better to spend a few hours on Google to see if someone else has already done your dirty work for you, because usually someone has. So I did that.
The first result I found was a Microsoft mailing list thread from 2002 where Mitch Gallant and Rebecca Bartlett both inquired about this format. Microsoft’s response was to refuse to provide any documentation, and generally be rude and unhelpful, on the grounds that this use case was unsupported. Now, hang on, because I need to point something out. I’ve asked a lot of software vendors for obscure technical information about their products, nearly all of which were for unsupported use cases. By far my favorite vendor to work with in this area was the robotics hardware company Charmed Labs (they are incredibly nice and helpful, even happily giving me proprietary source code that was protected by patents, for me to do whatever I wanted with, as long as I didn’t distribute or use commercially). But generally speaking, the “good” companies’ responses to such requests follow this kind of formulation:
- What you’re trying to do is not something that we officially support.
- We think what you’re doing is a bad idea for these reasons.
- There may be other reasons that it’s a bad idea, which we haven’t thought of.
- We think the “right” way is something else, and we’re happy to help you with that method if you like.
- Regardless, here are all the answers to your questions.
- If you have any other questions about this unsupported use case, we’ll try to answer, as long as it doesn’t become a time sink for us. Don’t expect super-quick replies, because we’re looking up answers in our spare time.
- If any of the info we’re providing turns out to be incomplete or wrong, or you end up getting burned in any other way for doing this, we’re not responsible.
Whenever I’ve gotten a reply like this (and it’s happened reasonably often), I was a happy camper, because I was able to make an informed decision. Sometimes I decided to abandon my quest; other times I disregarded the warning and pressed on anyway. In the latter case, I knew full well what I was getting into, because the vendor had given me sufficient information and context for me to make up my mind. Usually, I was satisfied with my decision at the end of the day. In fact, I cannot remember a case where I did something I seriously regretted after being warned against it like that. I’m sure it could have happened, had the quantum noise been different, but if that had come to pass, I’m confident that I wouldn’t have blamed the vendor for giving me information coupled with advice that I ignored. There were several times where my disregard for the warning resulted in some lost development time or temporary confusion, but seriously, who could possibly be angry for the chance to gain practical experience in an unfamiliar area, particularly given that when I did decide to change course, I now had both the vendor’s expert recommendations and my new practical experience to inform my decision. What more could anyone want? My point is, the good software vendors treat their users like real, sentient people when they ask for information, while the bad software vendors (Microsoft included) treat their users the way that the owners of Number 4 Privet Drive treated their nephew up until mid-1991: Don’t ask questions!
Technically, Microsoft did provide parts (1) through (4) of the above form, but they don’t even qualify for partial credit here, because the reason they gave for (2) is atrocious on its face: once in 2 decades, they moved a store from the registry to the filesystem to handle roaming profiles, and anyone using the registry directly would have had to update their software (with a really minor change) once Windows 2000 came out. Frankly, if you’re unwilling to update your software once in 2 decades, I don’t know why you’re in this field, and you should go get a Ph.D. in Latin Literature so that you don’t need to ever learn anything new in order to stay at the top of your field for your whole life. Anyway, reading that thread was entirely unhelpful, except for the fact that it told me I had made a great choice never interviewing at Microsoft, because if I ever become the kind of tech support robot who shows up in that thread, someone please kill me.
So, I continued to look through Google for a while. And I did find two people who had actually tried to reverse-engineer the blob format. Tim Jacobs had posted some information in 2008, and Willem Jan Hengeveld had posted some other info in 2003. Interestingly, both Tim and Willem had been looking into dealing with bugs in mobile versions of Windows that made it hard to import a certificate any other way. (See, basic research has diverse, and often non-obvious, use cases.) Tim’s documentation wasn’t particularly helpful for me, because while it explained how to solve a specific problem (which wasn’t the problem I had), it didn’t really explain why that solution worked, nor how he figured it out (actually, I’m very skeptical of why his solution even works, and based on my research below, I suspect that he simply got lucky and that his method will spectacularly break in many real-world scenarios). However, Willem’s documentation was very helpful. According to Willem, a cert blob is a sequence of records, each of which consists of a 4-byte propid (which I gather means “property ID”), a 4-byte unknown value (which I assume is reserved by Microsoft for future expansion, since everything I encountered used exactly the same value), a 4-byte size, and then the raw data for that property (whose size in bytes was specified by the size field). Willem also listed the common property ID’s that show up.
There was just one problem: the blob I was looking at had a bunch of property ID’s that weren’t in Willem’s list. So, of course, I Googled for one of the property ID’s that was in Willem’s list, and I ended up finding this page and this page on the Microsoft website, which had a (mostly) complete list. Except… those references had descriptions (which, admittedly, is nice) but not any info on what numerical values the property ID’s were. However, they did include a reference to Wincrypt.h. Ah ha, I thought, I’ve done this before! So I went and looked up that header file in the MinGW source code, and was treated to a complete list of the numerical values of all the property ID’s.
From there, I started gathering a list of which property ID’s Windows seemed to be using, so that I could generate the appropriate information while inserting a cert, given only its DER x.509 encoding. Unfortunately, quite a lot of the property ID’s were for things that looked quite annoying to calculate. After trying to figure out a way to calculate a “signature hash” of an x.509 cert in Golang, and not having any fun whatsoever (mind you, I did find ways to do it, I just knew I would despise the process of coding it, and of ever looking at the horrible code that was bound to result), a thought crossed my mind: What does CryptoAPI do if some of the properties are missing from the blob, as long as the record format is correct? So, I took the blob that Windows had generated, and I wiped everything except for the x.509 cert itself and the 12-byte header for that property. I inserted it into the registry, and visited the corresponding website in Chrome. The website loaded just fine! Then I went back to the registry editor, and refreshed, and was quite surprised to see that the moment that CryptoAPI had validated the cert, it had re-calculated all of the other missing fields, and inserted them into the registry.
So, basically, all of those other properties are, as best I can tell, just an elaborate caching mechanism, completely superfluous for proper operation. Microsoft made CryptoAPI substantially more complex, added at least 4 public-facing API functions (those are just the ones I accidentally ran across), and invented a custom, undocumented binary blob format, all so that they could avoid doing a couple of extra hash operations when verifying a chain that included a previously seen certificate. (Remember, hash operations are fast, while RSA and ECDSA, which aren’t cached here and are still needed to verify cert chains, are slow.)
Typical Microsoft. slow clap
Thanks goes to ncdns developer Hugo Landau and Monero developer Riccardo Spagni for keeping me company on IRC while I figured all of the above out. What does this have to do with Namecoin? You’ll find out in my next post.
Progress on ncdns-nsis
Development nears completion on the NSIS-based Namecoin and ncdns bundle installer for Windows.
The ncdns-nsis repository provides
source code for an NSIS-based installer which can automatically install and
configure Namecoin Core, ncdns and Unbound and configure name resolution of
.bit domains via Unbound.
The installer can install Namecoin Core and Unbound automatically, but also allows users to opt out of the installation of these components if they wish to provide their own.
Completion of the ncdns-nsis installer project will enable the Namecoin project
to distribute a Windows binary installer providing a turnkey,
configuration-free solution for .bit domain resolution. The installer is also
intended to support reproducible builds and can be built from a POSIX system.
At this point, extensive testing is the primary work remaining on the completion of the ncdns-nsis installer.
Namecoin Receives Funding from NLnet Foundation’s Internet Hardening Fund
We’re happy to announce that Namecoin is receiving 29,895 EUR in funding from NLnet Foundation’s Internet Hardening Fund. If you’re unfamiliar with NLnet, you might want to read about NLnet Foundation, or just take a look at the projects they’ve funded over the years (you might see some familiar names). The Internet Hardening Fund is managed by NLnet and funded by the Netherlands Ministry of Economic Affairs. The funding will be used to fund 4 Namecoin developers (Jeremy Rand, Hugo Landau, Brandon Roberts, and Joseph Bisch) to produce a usable decentralized TLS public key infrastructure.
Specifically, the following areas of development will be funded:
- Integration with DNS functionality of major operating systems. We intend to support GNU/Linux and Windows, including DNS integration for Tor. Other operating system support may be developed if things go well.
- Integration with TLS certificate validation functionality of major web browsers. We intend to support Chromium, Firefox, and Tor Browser on GNU/Linux and Windows. Other browser support may be developed if things go well.
- Improvements to the lightweight SPV name lookup client.
- A lightweight SPV wallet with name support. We intend to use Electrum.
- Wallet GUI improvements, including Coin Control for name transactions and a name update GUI that doesn’t require knowing JSON.
- Improved installation automation. We intend to provide a Windows installer that includes a Namecoin client, DNS integration, and TLS integration. Other OS support may be developed if things go well.
We’d like to thank the awesome people at NLnet Foundation for selecting us for this opportunity, as well as the Netherlands Ministry of Economic Affairs for recognizing that a hardened Internet is worth receiving government financial support.
We’ll be posting updates regularly as development proceeds. (Spoiler alert: a few components are already nearly ready for beta releases.)
ICANN58 Summary
As was announced, I represented Namecoin at ICANN58 in Copenhagen. Below is a brief summary of how it went.
- I presented in the Emerging Identifier Technology Panel.
- Free-software-friendly video recording is hosted by Namecoin.org.
- The above recording is converted from ICANN’s official Adobe Connect video recording. Copyright ICANN; used with permission.
- Namecoin slides are hosted by Namecoin.org.
- I presented in the Technical Experts Group / Board Joint Meeting.
- Free-software-friendly video recording is hosted by Namecoin.org.
- The above recording is converted from ICANN’s official Adobe Connect video recording. Copyright ICANN; used with permission.
- Namecoin slides are hosted by Namecoin.org.
- A significant number of people in the ICANN community are interested in Namecoin.
- While I have not attended previous ICANN events and therefore cannot evaluate this myself, my understanding is that the EIT panel session had an unusually large audience.
- There is skepticism in the ICANN community of Namecoin’s ability to completely replace the DNS.
- By far the most common reason for this skepticism is the concern that Namecoin may not be able to scale to DNS’s usage levels.
- I fully agree that this is a good reason to be skeptical and that work needs to be done in this area.
- Another concern raised was Namecoin’s lack of privacy in its current form (specifically the risk of transaction graph analysis).
- The people who raised this concern appear to be satisfied that the Namecoin developers understand that this is a problem and that we intend to fix it. If we fail to fix it adequately, this concern is likely to become more of a big deal.
- By far the most common reason for this skepticism is the concern that Namecoin may not be able to scale to DNS’s usage levels.
- The ICANN community appears to be reasonably accepting of Namecoin’s role as an alternative to DNS; Namecoin makes different tradeoffs from DNS, is therefore likely to be optimal for a different userbase, and can co-exist with DNS in its current state.
- Several people I met are interested in assisting Namecoin; we are following up with those people.
- I ran out of business cards in my wallet 3 times in 3 days. Luckily, I carry a large stash of business cards with my travel laptop, so everyone who requested my business card received it.
- My wallet is currently sufficiently full of business cards from ICANN58 attendees that I’m having trouble easily fitting my credit card into my wallet.
- The joint meeting of ICANN’s Security and Stability Advisory Committee (SSAC) and the ICANN board included a segment on Special-Use Names and name collisions. For those who are unaware, this is of interest to Namecoin because it would be problematic for Namecoin if ICANN were to allow someone to purchase .bit as a standard DNS TLD.
- Free-software-friendly video recording is hosted by Namecoin.org.
- The above recording is converted from ICANN’s official Adobe Connect video recording. Copyright ICANN; used with permission.
- The discussion of collisions between non-DNS names (such as Namecoin, though Namecoin wasn’t explicitly mentioned) and DNS names (such as if ICANN were to issue the .bit TLD to someone) begins at timestamp 42:25. I highly recommend watching the full segment, but some highlights include:
- The SAC090 document “SSAC Advisory on the Stability of the Domain Namespace” was cited; most important are 3 Recommendations from SSAC (summarized by Jeremy, apologies for any errors):
- Recognize that name collisions will always be with us, and they’re not going to go away. There’s no way to control how people use names.
- It’s important to control the things that you can control: make sure that the parts of the namespace that ICANN controls are predictable (harmonize with private-use names). We need to allow private-use names to exist, in the spirit of innovation.
- Since we recognize that we are not the only ones who have names that will look like TLD names, and the community is going to use that kind of stuff in an interesting way, we need to have procedures for dealing with other bodies who are going to be creating special-use names for their own purposes. It is important to establish regular communication, how we each recognize each other, how we’re going to work together, and set ourselves up for potentially others (besides IETF) who may want to create lists of names. Be prepared to deal with other groups who are going to have their own lists of names.
-
Steve Crocker (chair of the ICANN board) said the following:
The IETF has a special names list, a reserved names list, but my understanding is that that’s not a definitive list in the following sense. It takes a while before a name gets onto that list. So, it tends to be on the conservative side. There are other names that are in use but have not gone through an IETF process. From where we’re sitting over at ICANN, if we want to be conservative, we would take into account not only the names on the reserve list from the IETF but also other names where it’s evident there is usage but nobody has come along and said we’re going to – you should reserve this and reserve this and so forth. So, I would think that our obligation is to have a somewhat wider field of view, including not only the official list but also what’s actually happening in the real world. And I can anticipate arguments that say well, there’s no official reason to reject this name [for ICANN issuance, e.g. someone buying the .bit TLD for non-Namecoin use], therefore you must accept it. I would say just the opposite, that we have an obligation to be careful, and if we see reasons why a name should not be allocated, then we have that authority, we have that obligation to do that and to err on the side of caution there.
- The SAC090 document “SSAC Advisory on the Stability of the Domain Namespace” was cited; most important are 3 Recommendations from SSAC (summarized by Jeremy, apologies for any errors):
- I consider this an extremely good sign.
- In response to a question in the Public Forum 2 about whether ICANN was looking into adopting Namecoin, Steve Crocker (chair of the ICANN board) commented “These things take time.” The full question and answer are in the ICANN transcript, pages 25-28. Steve’s comment is, in my opinion, a completely reasonable response.
- We plan to continue engaging with the ICANN community.
- We plan to continue engaging with IETF on Special-Use Name registration.
- At this time, I have no reason to expect any hostile action by ICANN toward Namecoin.
As with other conferences, I won’t be releasing details of private conversations, because I want people to be able to talk to me at conferences without being worried that off-the-cuff comments will be publicly published. That said, all of the private conversations I engaged in were highly encouraging.
Huge thanks to David Conrad (ICANN CTO) for inviting me to attend ICANN58, and to Adiel Akplogan (ICANN VP of Technical Engagement) for inviting me to the EIT Panel. Also thanks to ICANN for covering my travel expenses. I hope we can do this again sometime.
QCon London 2017 Summary
As was announced, I represented Namecoin at QCon London 2017. Below is a brief summary of how it went.
The theme of the blockchain track was “Beyond the Hype”. As such, the presentations in the track primarily focused on all the things that can go wrong when using a blockchain. Riccardo Spagni (AKA fluffypony of Monero) is definitely an ideal person to host this track. My talk was on alternate blockchains, with a focus on Namecoin (and some Monero). In the spirit of going “Beyond the Hype”, my talk was almost entirely about things that can go wrong when using a non-Bitcoin blockchain.
I think this is a very important theme for a blockchain track, because the hype attached to the blockchain field is seriously problematic for our field’s credibility. None of us were there to sell our technology, attract investors, or grab media attention – we were there to provide a reality check for an audience who, in large part, had minimal exposure to blockchain technology and wanted to learn more about what use cases it’s good or bad for.
Lots of attendees talked with me over dinner and in the hallway, and I’ll be following up with them ASAP. After QCon, I attended a talk Riccardo gave at Imperial College; several people there were interested in Namecoin. I met up with Riccardo the next day to discuss lots of cool stuff involving Namecoin and Monero.
As with other conferences, I won’t be releasing details of private conversations, because I want people to be able to talk to me at conferences without being worried that off-the-cuff comments will be publicly published.
Huge thanks to Riccardo for inviting me, and to all the QCon conference organizers for an awesome conference (and for covering my travel expenses). It’d be awesome if we can do this again.
A video of my talk is scheduled for release on June 26, 2017.
Namecoin Core 0.13.99-name-tab-beta1 Ready for General Use
Namecoin Core 0.13.99-name-tab-beta1, which has been listed on our Beta Downloads page for a few months, has demonstrated itself to be stable enough that it is now listed on the main Downloads page. Huge thanks to our Lead C++ GUI Engineer Brandon Roberts for his work on this.
Namecoin’s Jeremy Rand will be a speaker at ICANN58
ICANN has invited a Namecoin developer to speak at the ICANN58 meeting on March 11-16 2017 in Copenhagen, and I’m happy to say that I’ve accepted their invitation. Since I’m well aware that this may be surprising to some readers, I think it’s beneficial to everyone to announce it here, and give some details about why I’ll be attending.
The rest of this post will be in the excellent Q&A-style format.
Why did ICANN invite you?
To my understanding, I was invited because of a perception that there was a lack of understanding and dialogue between ICANN and Namecoin about specifically what the goals of each group were. The hope is that by encouraging discussion between ICANN and Namecoin, the groups will have a more accurate idea of what the other is doing and what common interests we might have.
It’s not news to me that ICANN has an interest in Namecoin; an ICANN panel report favorably mentioned us. However, I admit that I was (pleasantly) surprised to receive this invitation.
What do you think of ICANN and DNS?
To be totally honest, I’m not really very knowledgeable about how ICANN operates. I hope to gain some knowledge on this subject at the meeting. That said, I’ve heard that ICANN has some political issues. (Indeed, if James Seng’s comments in the aforementioned report are any indication, this is a recognized issue by ICANN participants, not just from the outside.) This is really not surprising, and as far as I know, it’s not due to any kind of nefarious motivation by ICANN or any people within ICANN. My take is that ICANN’s political issues are likely to be simply because ICANN is very large, and large centralized entities are inevitably going to have political issues. If, in an alternate reality, OpenNIC were wildly successful and ended up as large as ICANN is today, I predict that OpenNIC would end up with political issues too.
Isn’t that just ICANN’s own fault for being centralized?
That’s not ICANN’s fault, it’s the reality of the laws of math. When DNS and ICANN were created, everyone believed that decentralized global consensus was impossible (and this belief was well-supported by a proof by Lamport dating back to the 1970’s). It wasn’t until Satoshi Nakamoto invented Bitcoin that anyone had any credible reason to believe that decentralized global consensus was solvable, and it wasn’t until Appamatto and Aaron Swartz proposed BitDNS and Nakanames 2 years later that anyone really seriously considered applying a Nakamoto blockchain to a DNS-like system.
But Namecoin exists now; doesn’t that make DNS obsolete?
Not really. Namecoin makes a number of design tradeoffs in order to achieve decentralization. Compared to DNS, Namecoin has significantly worse security against run-of-the-mill malware, significantly worse privacy against your nosy friends/neighbors/employer, and significantly worse resistance to squatting and trademark infringement, to list just a few. These are open research problems for Namecoin-like systems, whereas DNS has long ago solved them. I work on Namecoin because Namecoin also has some advantages over DNS, and I think there is a significant user base who want those advantages enough that they are willing to cope with the downsides. But that doesn’t mean that DNS is obsolete, or that I expect Namecoin to replace DNS anytime soon. If, in the future, Namecoin eventually solves those open research problems, and as a result replaces DNS, that’d be cool as heck from my point of view, but if that ever happens, I think it will be far enough in the future that it’s not worth worrying about right now.
Namecoin has almost no funding; if you had the budget of the DNS industry, wouldn’t those open research problems have been solved by now?
That would be inconsistent with the definition of “open research problem”. Funding would certainly help us spend more time tackling those problems, but there’s no guarantee that the problems are even solvable. Also, since no one is offering to give us such a budget, there’s not really much point in speculating here.
Are you being paid to attend?
ICANN is covering my travel expenses. (Naturally, I wasn’t going to ask NMDF to pay for me to travel. We don’t have anywhere near enough funding for that.) Other than that, I’m not being paid to attend.
Has ICANN asked for any control or influence on Namecoin?
Of course not. (And if they did, I would decline – as I assume would the other devs.) It’s entirely standard to talk to people working on related projects; it doesn’t imply any desire to influence or control those projects.
Are you concerned that this will be spun by market manipulators as some kind of sell-out?
I’m reasonably confident that market manipulators will try to profit by spinning this in some way, but that’s not anything new. We’ve already seen market manipulators try to make money by alleging a sell-out, based on everything from our application to Google Summer of Code in 2014 and 2015, to me getting a college scholarship from Google in 2013, to our collaboration with GNUnet, I2P, and Tor to try to register the .bit TLD as a special-use name via IETF. Those same market manipulators will, I assume, use this the same way, probably with the same minimal level of success that they had previously.
If I had any interest in spending my time worrying about market manipulators, I’d be in a different line of work, making way more money than I’m making right now. The best I can do is be transparent about this, so that it’s obvious to anyone who does an ounce of research that nothing nefarious occurred. Transparency FTW.
Will you publicly post your presentation slides?
Sure, why not?
Namecoin’s Jeremy Rand will be a speaker at QCon London 2017
As a result of an invitation from Riccardo Spagni (AKA fluffypony of Monero), I will be speaking at the “Practical Cryptography & Blockchains: Beyond the Hype” track at QCon London 2017 (March 6-8 2017). My talk is entitled “Case Study: Alternate Blockchains”. I will also be on a panel discussion alongside Paul Sztorc, David Vorick, Elaine Ou, Peter Todd, and Riccardo Spagni.
My understanding is that a video of my talk will be published by QCon. Assuming that that’s correct, I will post a link here when it’s available.
Huge thanks to Riccardo for inviting me, and to the QCon organizers for putting on the conference and covering my travel expenses. Looking forward to it!
Lightweight SPV Lookups: Initial Beta
If you watched my lightning talk at Decentralized Web Summit 2016 (and if you didn’t, shame on you – go watch it right now along with the other talks!), you’ll remember that I announced SPV name lookups were working. I’m happy to announce that that code is now published in preliminary form on GitHub, and binaries are available for testing.
You can download it at the Beta Downloads page. Once installed, it’s basically a drop-in replacement for Namecoin Core for any application that does name lookups (such as ncdns). Test reports are greatly appreciated so that we can do a proper release sooner.
Initial syncup using a residential clearnet cable modem connection takes between 5 minutes and 10 minutes, depending on the settings. (It is probably feasible to improve this.) Lookup latency for name_show varies from 2 seconds to 4 milliseconds, depending on the settings. (It is also probably feasible to improve this.)
This work wouldn’t have been possible without the work of some very awesome people whom I need to thank.
First, I need to thank Ross Nicoll from Dogecoin (warning: non-TLS link) for creating libdohj, an altcoin abstraction library that has prevented Namecoin from needing to maintain a fork of BitcoinJ. We’re using the same AuxPoW implementation from libdohj that Dogecoin is using – a fitting repayment, since Dogecoin Core uses the same AuxPoW implementation that Daniel Kraft wrote for Namecoin Core. We look forward to continuing to work with Ross and the other excellent people at Dogecoin on areas of shared interest.
Second, I need to thank Sean Gilligan for his work on bitcoinj-addons, a collection of tools that includes a JSON-RPC server implemented using BitcoinJ, which can substitute for Bitcoin Core. Sean is also a big Namecoin enthusiast. (I also finally got to meet Sean in person at DWS.)
Last but not least, I need to thank Marius Hanne, operator of the webbtc.com block explorer. The SPV lookup client currently is capable of using webbtc.com for extra efficiency (either for checking the height of blocks to download over P2P, or for downloading merkle proofs). Marius has been incredibly helpful at customizing the webbtc.com API for this purpose. webbtc.com is under a free software license (AGPLv3), so you can run your own instance if you like.
Remember: this is a beta, for testing purposes only. Don’t use this for situations where incorrect name responses could lead to results that you aren’t willing to accept.
In addition, some notes about security. SPV protects you from being served expired name data, and protects you from being served unexpired name data that isn’t part of the longest chain. However, the SPV modes other than leveldbtxcache (see the documentation) don’t protect you from being served outdated name data that hasn’t yet expired, nor does it protect you from being served false nonexistence responses, nor does it protect you from someone logging which names you look up. We made an intentional design decision to trust webbtc.com here, rather than the Namecoin P2P network, because the P2P network is unauthenticated, trivially easy to wiretap, and trivially easy to Sybil. leveldbtxcache mode avoids these isues, although it takes about twice as long to synchronize. We have plans to add further improvements in these areas as well. SPV also doesn’t protect you from attackers with a large amount of hashpower. As with Bitcoin, a major reason that miners can’t easily attack end users is because there are enough full nodes on the network to keep the miners honest. If you have the ability to run Namecoin Core (syncup time of a few hours, and a few GB of storage), you should do so – you’ll have better security for yourself, and you’ll be improving the security of other users who can’t run a full node.
Have fun testing!
Decentralized Web Summit Recap
As was mentioned on the forum and /r/Namecoin, I represented Namecoin at the Decentralized Web Summit at the Internet Archive in San Francisco, June 6 - June 10. Lots of awesomeness occurred.
I participated in a panel on naming and identity systems on Wednesday. Other panelists were Christopher Allen (Blockstream), Muneeb Ali (Blockstack), and Joachim Lohkamp (Jolocom); Chelsea Barabas (MIT Center for Civic Media) moderated. The panel had a diverse set of perspectives, and I think the discussion was informative.
On Thursday, I did a lightning talk. The talk briefly introduced Namecoin, and then went on to new developments, specifically new announcements about HTTPS and SPV. The lightning talk concluded with an invitation to talk to us about collaboration, and a plug for my workshop (which immediately followed).
The workshop was basically an intro to actually using Namecoin. I walked the attendees through registering domain names and identities, viewing domain names with ncdns, and logging into websites with NameID. We had some minor technical issues during the workshop (which is to be expected), but nothing too bad. At the end of the workshop, I showed a demo of the TLS code working. (Major thanks go out to fellow Namecoin developers Brandon Roberts, Jonas Östman, Joseph Bisch, and Cassini for helping me put together the workshop.)
But of course, I didn’t fly to San Francisco just to do a panel, lightning talk, and workshop. A major goal was to talk to as many other projects as possible to see where we could collaborate. (No single project is going to decentralize the entire Web, but working together, we might have a shot.) I won’t list all the conversations I had on this post, because I want people to be able to talk freely to me at conferences without being worried that the conversation will be posted for the world to see, but the number of orgs I talked to stands at at least 23. Hopefully we’ll be able to announce some results of these conversations in the near future.
And of course, it wouldn’t be an event by the Internet Archive without archived videos, so here are some of the highlights that Namecoiners will find particularly interesting:
Lightning Talk: Jeremy Rand of Namecoin
Builder’s Day Interview: Tamas Kocsis of ZeroNet (uses Namecoin)
Lightning Talk: Tamas Kocsis of ZeroNet (uses Namecoin)
Naming and User Identities Panel
Overall, it was an excellent event. I highly recommend watching all the other non-Namecoin content as well: full archives of all the talks are here.
I also want to thank Brewster Kahle and Wendy Hanamura for organizing the summit, and Kyle Drake of Neocities, Greg Slepak of okTurtles, and John Light of Bitseed for inviting me to attend. Also thanks to all the other organizers, speakers, and attendees: you’re all awesome. I really hope that Internet Archive makes this a regular event.
NMControl 0.8.1
Out now: NMControl v0.8.1.
UPNP Vulnerability in Bitcoin Core affects Namecoin
A vulnerability was found in Bitcoin Core. It allows an attack from malicious peers in the local network via UPNP. Namecoin is affected, too, so everybody should turn off UPNP until further notice.
OneName’s Blockstore is much less secure than Namecoin
Note: the naming system described in this post, Blockstore, is now named Blockstack.
It’s well-known that OneName has been engaged in questionable practices on the Namecoin blockchain, such as creating a duplicate namespace (u/) which harms the security of users and aids squatters. So we were interested to hear the news on September 12 that OneName has decided to stop using Namecoin in favor of a naming system they announced circa February 2015, Blockstore. Blockstore stores name transactions within OP_RETURN outputs on the Bitcoin blockchain (the full values of names are stored in a DHT). OneName claims that Blockstore has better security than Namecoin, on the grounds that Bitcoin hashpower is larger and more decentralized than Namecoin’s. This is a false assumption.
It is fairly well-known that a blockchain is a dynamic-membership multiparty signature (DMMS), attesting to the correctness of the transactions. Specifically, there are two main types of correctness that the blockchain attests to: the ordering of the transactions, and the validity of the transactions with regard to all previous transactions. Correctness of ordering is primarily to prevent double-spending of otherwise-valid coins. Transaction validity, such as checking ECDSA signatures and making sure that names are being spent by their rightful owner, allows SPV-based clients to function properly (among other things). OneName is claiming that Bitcoin’s blockchain is a DMMS attesting to Blockstore’s correctness. But the Bitcoin miners are only verifying ordering and Bitcoin transaction validity – they are not verifying the validity of Blockstore transactions.
Is this a big deal? Yes. It means that if you wrote an SPV client for Blockstore, I would be able to create an OP_RETURN output in the Bitcoin blockchain that claimed ownership of any arbitrary name, and your SPV client would not be able to detect the fraud. It also means that a validating Blockstore node cannot be a UTXO-pruned Bitcoin client – a full Bitcoin client is needed.
To expand further on this issue, in the event of malicious data insertion by users bent on disrupting the system, clients that are asking for data from Blockstore servers have almost no way to verify whether the servers are telling the truth or not.
In Bitcoin, the notion of SPV clients was proposed by Satoshi as a way for lightweight clients to avoid the need to store the entire Bitcoin blockchain themselves. As part of this idea, Satoshi described a mechanism by which fraud proofs could be used to reveal cheating and, ostensibly, punish the cheaters. Bitcoin SPV is in large part enabled by the proof-of-work in Bitcoin which makes forging SPV responses very difficult to begin with. In Blockstore’s system, lightweight lookups have no PoW-backing, and there does not appear to be a way to have even simple Satoshi-style PoW-based fraud proofs to detect cheating, so clients are likely entirely at the mercy of anyone running a server. Blockstore-specific SPV fraud proofs would require complex mechanisms and probably extensive pathing hints, and since fraud proofs don’t even exist yet in Bitcoin (wherein the majority of blockchain research and development is happening and on which the attention of nearly all of the interested cryptographers, research scientists, developers, and engineers is focused) it is unlikely Blockstore can satisfactorily solve this particular problem given the more extreme constraints they are operating with.
The Blockstore system is analogous to recommending that currency be stored in a blockchain that has a higher hashrate than Bitcoin and has 100 equally sized pools, but whose block validation rules are so loose that signature verifications always pass. What’s the point when I can steal your money or names and your client can’t tell? (Of course, when all signature verifications pass, even double-spend detection can’t function either, so this doesn’t even solve double-spends.)
Namecoin, in contrast, enforces transaction validity (including name ownership) in blockchain validation rules. This means that, even if a majority of Namecoin hashpower wanted to steal your name, their transaction that spends your name coin would be rejected by all of the network’s validating nodes. They could double-spend a name, but the only attack that this enables is fraud during non-atomic name trades. Given that Namecoin supports atomic trading of a name for currency (see ANTPY and NameTrade), this attack is unlikely to be an issue.
A prolonged 51% attack on Namecoin could censor name transactions and eventually cause names to expire if the attack lasted 8 months, but this would be detectable and obvious to all users on the Namecoin P2P network. (Moreover, as soon as the attack started, it would be detectable and obvious specifically which names were targeted, and if the names were re-registered by the 51% attacker, they would be distinguishable from the original name by the block height of their corresponding name_firstupdate transaction. We have a pending proposal to make that block height visible to user applications so that such attacks can be automatically mitigated.) And of course, a mining pool who performed an 8-month-long 51% attack would most likely lose a lot of hashpower as their users abandoned them in favor of mining pools who aren’t attacking the network.
Is Namecoin’s mining centralization problematic? Yes, to a point. But with Namecoin there is a possibility for the situation to improve in the foreseeable future with the new Namecoin Core client, and with influx of new users and miners due to improved usability. While Namecoin currently has around 40 percent of Bitcoin’s hashpower verifying transaction validity, Blockstore has 0.
Additionally, DHT-based discovery of storage nodes is one of the classic suggestions of new users as an alternative to DNS seeds, and, originally, IRC-based discovery: it has never been committed because it is trivial to attack DHT-based networks, and partly because once a node is connected, Bitcoin (and thus Namecoin) peer nodes are solicitous with peer-sharing.
As an actual data store, DHT as it is classically described runs into issues with non-global or non-contiguous storage, with little to no way to verify the completeness of the data stored therein. With the decoupled headers in OP_RETURN-using transactions in Bitcoin and the data storage in a DHT (or DHT-like) separate network, there is the likelihood of some little-used data simply disappearing entirely from the network. There is no indication of how Blockstore intends to handle this highly-likely failure condition.
More interesting are Bitcoin-related failure conditions: Blockstore information is not in an obscured Merklized tree-like structure with the root node stored in Bitcoin; Blockstore proposes to store actual raw data in OP_RETURN, with the limited space therein necessarily requiring highly constrained bits of data and limits in its form and structure. With this, it would be trivial for anti-spam mining cabals to censor these transactions, and given the understandable hostility with which some Bitcoin advocates treat altcoin bloating of the Bitcoin blockchain, the inevitable result will be a mass-distributed method of censoring of Blockstore transactions. Even if this is not so, it is a systemic flaw and therefore at permanent risk of being disrupted by miners who choose not to enable what they in turn view as the hostile economic externalities involved with permanent storage of questionably valuable data on behalf of third parties. As Satoshi noted: “Piling every proof-of-work quorum system in the world into one dataset doesn’t scale.”
Finally, one of the biggest flaws in this scheme is the nature of the loosely-connected graph structure formed by the so-called “consensus hash” that Blockstore hand-waves away by saying it will hash the data in the “last 12 blocks” without a concrete description thereof. What algorithms do they propose to ensure that not only does it form a properly, fully-connected graph and is verified, but also that its consensus-hash is accurate or even useful? Graph algorithms are notoriously complex: entire branches of science exist just to study and theorize about them. What use is this consensus hash when it’s entirely voluntary and arbitrarily-connected to prior data? How is the verification process going to proceed without, over a long period of time, becoming so complex that the cost is no longer feasible for normal consumer processors? How does Blockstore intend to discover what data each consensus hash even refers to? Transitive closure searches for such graphs could be made arbitrarily complex and non-deterministic by attackers who are interested in doing so, especially over time, and there is no mention of this class of vulnerability nor its proposed solution by Blockstore.
We will be working on improving Namecoin identities to make pseudo-decentralized naming systems obsolete. But unlike the commercial enterprise OneName, we are volunteers creating ethical software in our spare time. If you prefer our method of prioritizing sound design over flashy PR campaigns, join us!
Why Duplicate Namespaces Are Bad for Users
Every now and then, we’re approached by users who are asking about namespaces which duplicate functionality of the officially recommended namespaces. Examples of these namespaces include tor/, i2p/, and u/. We think these duplicate namespaces are harmful to end users. This blog post will try to explain why duplicating functionality of existing namespaces is almost always a bad idea.
Background
This whole thing seems to have started when someone noticed that the d/ specification, which is used for domain names, only supported IP addresses. This person thought it would be awesome to have DNS for Tor hidden services, and proposed a tor/ namespace for such domains. Someone else appears to have decided the same thing for I2P, and created an i2p/ proposal.
An alternative proposal was the d/ 2.0 spec, which allowed d/ names to map to Tor hidden services and I2P eepsites. This is the proposal which is for the most part still widely used today.
Why was d/ 2.0 a better idea than starting 2 new namespaces?
Duplicate Namespaces Attract Squatters
Imagine that d/, tor/, and i2p/ are all common namespaces. Let’s say that WikiLeaks is running an IPv4-based website using the name d/wikileaks. Now let’s say that WikiLeaks wishes to offer a Tor hidden service for their website. They now have to register a second name, tor/wikileaks. Uh oh, seems a squatter saw that WikiLeaks had d/wikileaks and preemptively grabbed tor/wikileaks and i2p/wikileaks just in case WikiLeaks wanted those names. Now WikiLeaks has to negotiate with a squatter, who potentially might be on the payroll of a government who wants to either cost WikiLeaks lots of money or impersonate it.
What’s the defense here? The only defense is to preemptively register your name in all namespaces, just in case you want them later.
Let’s say that in an alternate reality, WikiLeaks did exactly this, registering d/wikileaks, tor/wikileaks, and i2p/wikileaks. Now let’s imagine that someone decides that CJDNS mesh networking would be nice to have with Namecoin’s domain names, and creates a cjdns/ namespace. Well crap, now WikiLeaks is in a race with squatters to see who can grab cjdns/wikileaks first; if WikiLeaks fails, then they can’t ever use their name with CJDNS.
Remember that the domain squatters probably expend much more time watching namespace proposals, since that’s basically their job. WikiLeaks, on the other hand, probably is more worried about their whistleblower anonymity infrastructure than their choice of Namecoin namespaces.
This is simply a losing game for everyone except squatters.
Duplicate Namespaces Break Users’ Security Assumptions
Imagine a situation where an end user hears from a trusted source that wikileaks.bit is a great place to submit documentation of government corruption. wikileaks.bit uses the d/ namespace. But the end user doesn’t want to use clearnet, so she uses the tor/ namespace instead, accessing the domain wikileaks.tor. Note that she has just made the assumption that d/wikileaks and tor/wikileaks are operated by the same entity. However, this is not the case. The Namecoin network considers those two names to be entirely different things. Imagine that tor/wikileaks is instead operated by a government agency (perhaps they bought it from a squatter). Now our whistleblower is screwed.
If duplicate namespaces are in use, the only way to verify that two names are controlled by the same entity is to inspect the name you trust, and see if it links to the other name. For example, you could visit the website associated with d/wikileaks, and see if it mentions tor/wikileaks. This, of course, is neither automatable nor secure in our whistleblower’s case. Given how popular and successful phishing is, providing scammers with an easy way to break users’ security assumptions is an extremely bad enginering idea.
Consolidate All Namespaces with Common Use Cases
Let’s look instead at the d/ 2.0 proposal. It recognized that IP-based DNS, Tor-based DNS, and I2P-based DNS are all aiming at a common use case. By creating new functionality as new fields of the d/ namespace rather than new namespaces, the proposal makes sure that users of Namecoin DNS will be able to freely switch between IP, Tor, I2P, and any future system which may come along, without ever needing to register a new name. This protects users from squatters and protects their security, both now and in the future. (It also saves them money on name fees.)
Your Options When a Namespace Spec Doesn’t Meet Your Needs
Let’s say that you want to implement a new feature into an existing use case in Namecoin. For example, maybe you wish the id/ spec had some extra fields. You have three options:
- Talk to the other Namecoin developers and propose a change to the spec. This is what we generally recommend, although we realize that in some cases this may be difficult if your project is confidential prior to launch.
- Add a custom field to an existing namespace spec. As long as your new field has a name which isn’t likely to collide with other use cases, this is pretty much harmless (although we’d love it if you talked to us). Even if you’re refactoring existing features, it is likely that software following the existing spec will ignore your extra fields, and you can ignore the preexisting spec’s fields. This means that the two schemes can co-exist pretty much peacefully.
- Make a new namespace for your specific fields, and disregard the existing namespace. This is harmful; there is almost never a good reason to do this.
The u/ Namespace: Exactly How Not to Approach the Problem
As far as we can tell, a for-profit company (whom we won’t name here) decided to start offering identity products using the Namecoin blockchain. They didn’t like the structure of the id/ spec. So, did they talk to us? Nope, we never heard of their product until after it launched (we first noticed their product because of a bunch of nonstandard names showing up in the blockchain). Did they add some custom fields to id/? Nope, they instead did the worst possible thing as listed above: they made their own namespace (u/) with identical use cases as the pre-existing id/.
The Squatting Argument Revisited
While we’ve had difficulty reaching the team behind u/ for an official statement, we are under the impression that one of their stated rationales for creating a new namespace was that id/ was allegedly squatted too much. This is a quite strange claim. Creating a new namespace every time an existing namespace is heavily squatted will disrupt legitimate users of the existing namespace much more than it will disrupt squatters, even if a lot of the existing names are squatted. It also is an inherently cyclic process, since squatters can grab a new namespace just as fast as the old namespace. The correct way to disincentivise squatting (to the extent that it is a problem) is with changes to Namecoin’s fee structure.
A “More Structured” Spec
Another commonly cited “advantage” of u/ is that its JSON structure is allegedly better organized than that of id/. This is not an adequate reason to start a new namespace. Even if the u/ team didn’t want to directly work with us, they could have simply used their incompatible spec with the id/ namespace, and everything would have worked just fine. End users who wanted to use both specs would have been subject to the slight annoyance of having to enter duplicate fields in their existing names, but this would be infinitely better than needing a new name.
“Decentralization”
Several people have commented that because Namecoin is decentralized, or because it’s a general-purpose naming system, that it’s completely acceptable to create new namespaces without regard for the consequences. There is a fundamental difference between centralization and interoperability. Centralization would mean that an authority is dictating which names can and cannot be created; this would be extremely bad for end users. Interoperability means that the developer community is voluntarily standardizing on practices that allow everything to work together with minimal disruption; this directly benefits end users. We are for interoperability, not centralization. The ability to create new namespaces is primarily available for creating new applications. Of course, the blockchain validation math doesn’t care if two namespaces are used for similar things. This doesn’t mean it’s a good idea, or that people should be doing it on a regular basis.
Where From Here?
The u/ team has gotten themselves into a potentially bad situation, since now if they wish to move to id/, they’ll have to race against squatters: precisely the reason why we don’t recommend changing namespaces in the first place. We have limited sympathy for this predicament, since this could have easily been averted had they not created u/ in the first place. This has resulted in unnecessary trouble for end users, and we hope that a good resolution can be found.
Fix for OpenSSL Consensus Vulnerability has been deployed on 100% of mining hashpower
Fix for OpenSSL Consensus Vulnerability has been deployed on 100% of mining hashpower. Users of NamecoinQ (i.e. namecoind/Namecoin-Qt 0.3.x) are on semi-SPV security, and should wait for at least 6 confirmations for incoming transactions. Users of Namecoin Core (in beta) are on full-node security. Thanks to the miners for their quick action and everyone else who assisted in the response.
OpenSSL Consensus Vulnerability affects Namecoin
Warning: severe vulnerability disclosed - be careful.
Namecoin Bounty Cornucopia
Check out the Namecoin Bounty Cornucopia.
Namecoin’s 4th Birthday
The Namecoin blockchain is now four years old. Happy birthday!
N-O-D-E Interviews Daniel Kraft
Interview with Namecoin lead developer Daniel Kraft.
Name-Only Clients
Currently, the only options for people wanting to resolve Namecoin names are to deploy a full node or to trust results provided by someone else. It doesn’t have to be this way, though. Like with Bitcoin lightweight SPV clients which have much smaller local storage requirements can be created for Namecoin. Unlike Bitcoin, we can have “Namecoin Name-Only Clients” that give up support for “Namecoin as a currency” in exchange for better security and even lighter storage requirements.
Without the need to support currency transactions, a Namecoin SPV client can delete block headers that are more than 36,000 blocks old because they are not required to validate “current” (unexpired) name transactions. This data can be stored in a few dozen megabytes. We call this mode “SPV-Current” (SPV-C).
To support SPV-C, a name-only client must be able to query full nodes for transactions by name. This capability can either be added to the Namecoin “wire protocol” or operate as a separate service. Responses include cryptographic proof (using a Merkle hash tree) that the transaction was included in a block which the SPV-C client has headers for.
This basic implementation of SPV-C is vulnerable to a malicious node responding with an older (but non-expired) name transaction in response to a query or censoring the result. The easiest way to combat this is to query multiple full nodes and use the most recent response, but this is fragile. A more robust option would be to use a cryptographic (Merkle) hash tree to represent the list of all “unspent” transactions. This can be used to prove that it is responding with the latest data, since updating a name is done by “spending” the previous update.
The SPV-C client only needs to have the “root” of the hash tree (which is only 32 bytes long) to verify this proof. By having miners include this root hash in the coinbase transaction of every block, the set of all current names is verified continuously throughout the mining process. Since name operations are marked spent when they expire, the fact of a name transaction is unspent is proof that it is current. We call this Unspent Transaction Output Tree/Coinbase Commitments (UTXO-CBC).
Once the UTXO-CBC is included in all blocks, name-only clients can then keep track of the current root hash (more accurately, the root hash of the 12th deepest block, as keeping the UTXO set’s current at all blocks in memory is infeasible). When a client queries for a transaction by name, a full node will respond with the name transaction, proof that the transaction was included in a particular block, and that the name data hasn’t been updated by “spending” the transaction. UTXO-CBC constitutes a significant security improvement for SPV-C clients, as it prevents full nodes from returning anything but current name data. This mode is referred to as ‘SPV-C+UTXO-CBC’.
Implementing UTXO-CBC is complicated by a number of problems relating to the formulation of the cryptographic data structure representing the UTXO set. The most fundamental of these issues is that since new transactions occur continuously, it is important that miners be able to efficiently compute updates to the UTXO set. In other words, it must not be necessary for the entire cryptographic data structure to be recomputed when a new transaction is added to the set. Of course, any solution must preserve the ability to concisely represent the set and the ability to generate small, efficient proofs of inclusion. Thankfully, a similar UTXO coinbase attestation proposal has been made for Bitcoin, so existing work (such as the Authenticated Prefix Trees proposal) will be transferable to Namecoin.
The final security issue is ensuring that full nodes cannot censor names by simply lying “that name does not exist”. A very similar problem was solved in DNSSEC to provide “authenticated denial of existence” using a sorted list of all names. It’s possible to do this with the same sort of hash tree used to represent all unspent transactions. This commitment is referred to as Unspent Name Output Non-Existence CBC (UNO NX CBC). The UNO set is a name-only subset of the UTXO set.
Name-only clients can be improved incrementally, as attacks on even the basic SPV-C design require an attacker to control 100% of the full nodes connected to the target and even then it cannot arbitrarily forge data. Bootstrapping nodes can also attempt to provide a diverse selection of full nodes to clients, increasing the attack cost. However, UTXO CBC and UNO NX CBC reduce the amount of network traffic, reduce latency, and increase security, so they should be implemented eventually.
Hopefully this post has illustrated how both secure and lightweight resolution of Namecoin is not only possible but practical. Once implemented, name-only clients will provide a much better option to those who cannot run a full node versus all other currently available options which either provide no real security and/or require complete trust of a third party.
This post was slightly edited from its original version upon import to Jekyll, to more accurately reflect consensus among the Namecoin development community.
Developer Meeting Saturday, Jan. 3
Lately we’ve had a few new people who are interested in joining development. This is, of course, awesome. Unfortunately, helping them get started has been kind of ad-hoc, because there’s not a great way to have a low-latency conversation with current developers to bounce ideas off of. None of the current developers are in IRC at predictable, consistent times, and some developers are rarely on IRC at all. Forums have too much latency and overhead for quick back-and-forth discussions. This is a non-ideal situation.
So, we’re going to do an experiment – there will be a public developer IRC meeting in #namecoin-dev on Freenode on Saturday, Jan. 3, 9AM Pacific / 11AM Central / 12PM Eastern / 5PM UK / 6PM CET. We’re going to try to have as many Namecoin developers present as possible.
Current developers will give updates on what they’ve been doing; interested new developers can use it as an opportunity to get involved in discussions, ask questions, etc.; and interested average users will get to see more of how the development process works (because transparency is good). This bears some similarity to how Tor handles things.
Remember, this is an experiment, so we’re not quite sure how it will go. If it goes well, this may become a regular occurrence.
So, if you’ve been thinking of getting involved, or if you’re just curious, now’s your chance – stop by the developer meeting on Jan. 3 and talk to us. See you there!
Early Christmas Present for Namecoin
Christmas has come early for Namecoin: Discus Fish (aka F2Pool) has donated 20,000 namecoins to fund a reimplementation based on mainline Bitcoin!
What’s more is that chief Namecoin scientist Daniel Kraft has been working so hard that the code is already usable! Indeed, Discus Fish has been using it in production for a few weeks. The code is still considered experimental but you can check it out on Daniel’s Github repo. As always, make encrypted backups before playing around.
TL;DR: Namecoin is back!
This post was slightly edited from its original version upon import to Jekyll, to more accurately reflect consensus among the Namecoin development community.
New Version 0.3.80, Softfork Upcoming
This release smooths the transition to a new Namecoin codebase rebased on the latest version of Bitcoin!
Softfork
Starting at block height 212500 (around New Year’s Eve) miners will begin applying some checks for edge cases. There is a a small chance that miners running older versions will fork, so all pool operators and solo miners must update. Regular users should update too but the traditional precaution of waiting for six confirmations should be safe as well.
Be safe and make an encrypted backup of your wallet.dat file before updating. Thanks to everybody who helped make this happen!
Download v0.3.80 here, and see the release notes and full changelog.
Happy Halving Day!
As of block 210000 the Namecoin block reward halved to 25NMC. Happy halving day!
Cakes for Competitors
The proliferation of cryptocurrencies working on decentralized TLDs has spurred a narrative of competition with Namecoin. However, the distance between our communities is small, and the competition is friendly. The free software movement has shown us that multiple approaches strengthen the ecosystem. Competition is not the zero-sum game fundamentalist Chicago-school economists make it out to be.
This blog post is based on a forum thread from September 21st.
The title of this post is a reference to the Internet Explorer and Firefox tradition of sending celebratory cakes for major releases. While the two teams are competitors, this competition has pushed them to create better products. We believe the same is true of cryptocurrencies.
Namecoin developers are in this game to win it, but “winning” is the creation of decentralized, secure, and usable naming systems for the internet. Gaining acceptance with the IETF, building more secure registrars, lightweight clients, usable browser integration, and dynamic domain pricing are just a few challenges facing cryptocurrencies looking to add a decentralized TLD.
From proof-of-work to funding models and governance styles, Namecoin is very different from BitShares, Ethereum, or CounterParty. Sticking to our academic background allows us to build more robust security models and better defend ourselves from political and legal attacks. However, it also means we have to apply for public funding and struggle to build consensus. We believe that this diversity ultimately strengthens the community as a whole.
The bottom line is that we wouldn’t be working on Namecoin if the technology and solutions we are building were not reusable. BitShares has already benefited greatly from our work, borrowing our namespace specifications, adopting our protocols, and more. Building a usable censorship resistant web will require significant blood, sweat, and tears from lots of smart people. We are happy to do our part, and we are looking forward to the contributions that comes from competition and cooperation with the other cryptos.
This post was slightly edited from its original version upon import to Jekyll, to more accurately reflect consensus among the Namecoin development community.
Official Social Media Accounts
A large number of unofficial social media accounts have been making false claims about Namecoin. While we wish to encourage a healthy community and decentralization, we take user safety very seriously. Content posted through these accounts may pose a threat to average users, and the Namecoin development team has established official social media accounts in an attempt to help protect users.
The most serious issue, by far, has been claims about Namecoin being anonymous. We know that if a product is advertised as anonymous, it will be used in high-risk situations. If the product turns out to not actually be anonymous it can end up killing its users.
There are a large number of unofficial accounts [1] that have actively posted claims about anonymity to Facebook and Twitter groups related to WikiLeaks, Anonymous, Whistleblowing, Occupy, and Tor. The Namecoin client has not been audited (even a little bit) for security over Tor, and a recent proxy leak issue was fixed in Namecoin-Qt after these postings occurred. If someone living under an oppressive regime had tried to use our software in conjunction with Tor, that proxy leak could have gotten them arrested, tortured, or killed as a result.
Namecoin transactions, including domain name purchases, are not anonymous. Namecoin, being based on the Nakamoto blockchain used in Bitcoin, inherently leaks large amounts of information about its users’ identity. In one early example, researchers Reid and Harrigan were able to trace stolen Bitcoins to a bank account where the funds were deposited, despite the thief using sophisticated attempts to anonymize the funds. In a later example, researchers Meiklejohn et. al successfully identified the cluster of most WikiLeaks donations, even for donors who utilized single-use addresses. As the graph theory and data mining experts take over from the cryptography experts, and as the financial incentive for targeted advertising increases, these attacks will only get more effective.
We have asked the owner(s) of these accounts to stop posting false assertions about Namecoin on multiple occasions. They have consistently disregarded our requests, sometimes claiming that it’s “just marketing” and that we “are not very good marketers.” After two of our developers criticized this behavior on the forum, they were banned from one Facebook group for “trying to make trouble”.
This reckless “marketing trumps accuracy” attitude is dangerous for Namecoin’s users and harmful to Namecoin’s and our professional reputations. We recognize the importance of anonymity and are working towards a client specifically designed to be used with Tor as well as adopting methods from ZeroCash for anonymously purchasing records (such as ‘.bit’ domains and ‘id/’ identities) on Namecoin [2].
At Namecoin, we try hard to avoid unnecessary drama and focus on development. We really wish we could trust these unofficial accounts to represent us on social media platforms, but they have unapologetically put Namecoin users at risk. We would like to welcome everyone to migrate from the unofficial accounts to the official ones listed below. We will delegate posting rights to community members that demonstrate competency and a respect for user safety.
[Jeremy edit 2017 05 10: social media accounts are now listed in the footer of every page on Namecoin.org.]
Stay safe,
- The Namecoin Development Team
[1] We won’t be linking to these accounts, since we don’t want to boost their PageRank. However, they are unfortunately very easy to find on the various social networks.
[2] Ironically, the owner of the social media accounts has cited development discussions regarding these features as evidence that his claims of anonymity are correct.
Namecoin & Retail Usage
Well-meaning investors have been pushing for various currency-related use cases for Namecoin such as ATMs, acceptance at retailers, etc. The core development team sees these efforts as benign but generally do not expend time nor funds on them. Why would developers of a currency not place a priority on currency related use-cases?
The answer is that we place a priority on the specific use-cases that differentiate Namecoin from Bitcoin: DNS, ID, etc. Namecoin’s value comes from its utility as a naming system whereas Bitcoin’s value is primarily derived from its use as a currency. Competing with Bitcoin for dominance as a currency of exchange is suicide: Bitcoin has network effects that will overpower every other competitor in its market.
Furthermore, it is not clear that generic retail use of Namecoin is beneficial: most retailers immediately exchange crypto currencies into a reserve currency. Spending Namecoin at a retailer is only a step removed from exchanging Namecoin for fiat directly. Use as a reserve currency is Bitcoin’s problem, we have our own troubles to worry about.
The Great Aggregating Postmortem
In the past couple of weeks, Namecoin suffered outages. Someone (whom we’ve nicknamed “The Aggregator”) tried consolidating a large quantity of “loose change” into a single address. When done correctly, this is good because it reduces the amount of data lite clients [Jeremy edit 2017 05 10: this means UTXO-pruned clients] need to keep. Unfortunately, a combination of volume and an oversight in fee policies led to miners getting knocked offline.
Within 48/hours, we released a patch fixing the low fees which should have stopped the transactions, but miners were slow to uptake the patch. We then increased performance and miners have since finished processing the remaining transactions.
Our initial response was slow because our core developers were traveling. However, we are taking further steps to mitigate similar problems, improve our response times, and improve communications with miners.
Technical deep dive after the jump.
Deep Dive
An unknown party (The Aggregator) began consolidating a massive volume (50,000-100,000K) of unspent outputs into a single address. However, namecoind has extreme difficulty selecting outputs to spend in a wallet containing tens of thousands of unspent outputs. The Aggregator appears to have attempted to address this by writing a script which manually built transactions spending 50 or 100 of those unspent outputs to a new address (N8h1WYaCpnZrN72Mnassymhdrm7tT6q5yL).
The problem is that each of these transactions were 17-30 KB and rather than the standard transaction fee of 0.005NMC per KB (rounded up), a flat fee of 0.005NMC was used. Namecoin, like Bitcoin actually has two fee values, MIN_TX_FEE (used by miners) and MIN_RELAY_TX_FEE (used by all other full nodes). This enables MIN_TX_FEE to be lowered down to MIN_RELAY_TX_FEE without nodes who haven’t yet upgraded refusing to forward transactions with the new lower fee. On Bitcoin, the ratio between MIN_TX_FEE and MIN_RELAY_TX_FEE is 5:1, but due to an oversight it was 50:1 in Namecoin. The result was that The Aggregator’s transactions had a large enough fee to be forwarded throughout the network, but were considered “insufficient fee/free” transactions by miners. Since there is very limited space in blocks for such transactions, they just kept building up in the miners’ memory pools. The volume of transactions soon began causing the merge-mining software run by pools to time-out trying to get work.
We released an initial “band-aid” patch which simply upped the MIN_RELAY_TX_FEE to stop these particular problem transactions from being rebroadcast or accepted by pools. Phelix and Domob put together an RC branch which fixed the performance issues associated with The Aggregator’s transactions. The transactions have all been process but we have had positive feedback from miners and will be merging the RC branch with mainline shortly.
Additional techniques are being discussed to ensure Namecoin can better handle situations where there are too many transactions being broadcast to process them all. One is to temporarily drop lowest-priority transactions in the event of a flood, while granting higher priority to name transactions (NAME_NEW, NAME_FIRSTUPDATE, NAME_UPDATE) in order to ensure that time-sensitive operations are not delayed. Bitcoin developers have planned enhancements which will further mitigate the problem.
It was observed that at one point only one pool was functional. This pool mined many blocks in a row with no transactions. We have identified this pool and have been in contact with the operator. They modified their software some time ago to ignore all transactions to address some performance issues. We do not believe there was any malicious intent on their part, and they have committed to working with us to get to a point where they can include transactions in their blocks.
Response
Downtime is very bad; it opens us up to attacks and messes things up for businesses which depend on Namecoin. Trying to guarantee some arbitrary level of uptime is a fool’s errand but we endeavour to outline what went wrong and what steps we are taking to prevent similar issues from occurring in the future.
Each step of our response was unacceptably slow: discovering a problem, diagnosing the problem, submitting patches, and coordinating with miners all took far longer than they needed to. Our response was primarily slowed by the fact that two of our lead developers (Ryan and Domob) were both away from home with limited or no availability. There were other issues as well, which are addressed in the following recommendations, but this single factor significantly slowed every step of the process. Had they been available, we would have had patches out within 24 hours of the initial problem.
Initial Error Detection
The initial response times lagged mainly because we were unable to diagnose the problem. Individual developers (Ryan in particular) have patched clients which aid in diagnosing abnormalities. Initial detection of the problem lagged as well, individual users and developers noted problems but this took some time to reverberate. Automated monitoring system that will alert us to abnormalities on the network would be useful as well.
Recommendations
- Document and share patched clients
- Ryan
- Anon developer M?
- Setup automated monitoring √
- Block discovery times. √ Namecha.in has agreed to help.
- Mining Pool ratios. √ Namecha.in + Ryan
- Testnet-in-a-box. (Domob/Ryan need to publish)
Pushing Fixes
We went nearly 48 hours between having a bandaid patch and pushing out a statically compiled binary. This occurred for the following reasons:
- Indolering didn’t know how to properly communicate and distribute the fix.
- Limited communications with pool operators: it appears that the miners did not apply the initial bandaid patch which would have fixed network issues immediately.
- Even after the correct course of action was identified, it took 3-4 hours to create an official fork, produce a statically compiled binary, and post to the blog. We have been focusing our efforts on automating the build process for Libcoin, it should not be a problem moving forward.
Recommendations
- Codify process for creating an emergency branch and binary √
- Setup new alerts mailing list and ask pool operators to join √
- Gather contact info for major pool operators. √
- Setup multi-user access to Twitter.
- Streamline build processes.
- Jeremy Rand’s progress on Libcoin:
- Travis CI/automated builds √
- Functional unit testing √
- Miner-specific unit tests (Libcoin doesn’t yet support mining).
- Jeremy Rand’s progress on Libcoin:
Readiness & Coordination
In first-aid, the first thing you do is order bystanders to contact emergency services, direct traffic, etc. More developers would obviously help, but, akin to first-aid, emergencies need someone ensuring that progress is being made. Without a proper first responder, you have a lot of bystanders simply standing around.
Recommendations
- Fix developer mailing list. √
- Create security mailing list. (in progress)
- Appointing an official emergency coordinator to ensure things are moving.
- Has contact information of developers (including phone numbers) and miners.
- Alternate for when emergency contact is unavailable.
- Improve volunteer onboarding. (planned for September)
- Improve documentation.
- Better labeling of repos (deprecate mainline, rebrand Libcoind, etc)
- Public development roadmap.
- Organize bounties/tickets on needed items.
Thanks
Big thanks to Domob, Ryan, Phelix, Jeremy Rand, Indolering, our anonymous devs, mining pool operators, and others for their help
While Domob and Phelix coded the final fix, many people contributed to development. Phelix and Jeremy Rand were omnipresent during the entire response, from raising the initial warning to diagnosing the problem, proposing fixes, and testing. At one point, Jeremy Rand pulled 36 hours with no sleep. Ryan was especially generous with his time during a business trip, pulling all-nighters to help us diagnose the problem, develop fixes, and communicate with the mining pools.
Indolering worked hard to coordinate the response and communicate with miners. Our anonymous developers were a huge help, it’s a shame we can’t thank them publicly.
Luke-Jr, CloudHashing, BitMinter, GHash.io, and MegaBigPower helped us test our patches and provided feedback on miner performance.
Namecoin Response to Recent No-IP Seizure
On June 30, 2014, customers of the No-IP dynamic DNS service suddenly experienced an outage. According to media reports, the outage was not caused by a technical issue or any kind of negligence by No-IP, but rather by a court order requested by Microsoft, supposedly to fight cybercrime. For background, see No-IP’s official statement.
First off – we only know what was reported by the media. However, we are very concerned that a US judge decided to shut down an immensely popular service provider due to a few abuses by a tiny minority of its users, particularly with no due process afforded to No-IP.
At Namecoin, we believe that decentralization is the best way to prevent malicious takedowns. The only way to be certain that your domain will not be collateral damage to this kind of abusive court action is to make sure that it is mathematically infeasible to take it down without your consent. Bad lawyers can’t change the laws of math.
Namecoin supports dynamic DNS via the .bit top-level domain and the DyName software by Namecoin developer Jeremy Rand. DyName has existed since October 2013, and both Jeremy and Namecoin developer Daniel Kraft have invested development effort to improve the security of this use case. Dynamic DNS was tricky to implement securely with Namecoin, because updates have to be done automatically on a machine with network access, and if the wallet (which must be unencrypted to be used automatically) is compromised, control of the name could permanently be transferred to the attacker. We circumvented this by using a Namecoin specification feature called the “import” field. Under this system, the keys necessary to transfer control of your domain, or to impersonate the server it points to, remain on an encrypted wallet. If the keys used to update your IP are stolen, the worst the attacker can do is make your website go down until you notice and change keys (your visitors will receive a TLS error upon visiting your website in the meantime). Our software for accessing .bit domains, NMControl (which is used by FreeSpeechMe), supports this feature.
Namecoin also supports simulated dynamic DNS via Tor and I2P services. If you configure a .onion or .b32.i2p domain using Tor or I2P, you can give this domain a human-memorable name using Namecoin. The Namecoin software FreeSpeechMe has supported this for HTTP websites since December 2013. While bandwidth and latency are worse than standard IPv4, this method does not require any port forwarding or IPv6 connectivity (DyName requires one of these).
The system is not yet perfect. DyName DNS updates take approximately 10 minutes to propagate the network, and up to 30 minutes after that to be refreshed in the NMControl cache. The Tor and I2P service support does not yet support HTTPS and non-HTTP connections. Due to build issues, we haven’t yet been able to release a FreeSpeechMe update which includes the latest NMControl with support for DyName domains. And the Namecoin-Qt GUI does not yet make it easy to set up DyName or Tor/I2P .bit domains.
We believe that all of the above shortcomings are fixable. However, Namecoin developers are working on this in their free time, and we don’t have a significant financial stake in Namecoin like most altcoin developers do. If you’d like to support decentralized dynamic DNS to help prevent the next takedown, please consider contributing to a bounty for the features you want more attention paid to. And if you’re a developer and you want to help, get in touch with us on the forum.
New Website
Thanks to Shobute for designing and Indolering for pushing the new website.